This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Announcing DataOps Data Quality TestGen 3.0: Open-Source, Generative Data Quality Software. It assesses your data, deploys production testing, monitors progress, and helps you build a constituency within your company for lasting change. Imagine an open-source tool thats free to download but requires minimal time and effort.
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern data architectures.
Unlocking Data Team Success: Are You Process-Centric or Data-Centric? Over the years of working with data analytics teams in large and small companies, we have been fortunate enough to observe hundreds of companies. We want to share our observations about data teams, how they work and think, and their challenges.
Innovation/Ideation/Design for UI/X: In traditional software engineering projects, product managers are key stakeholders in the activities that influence product and feature innovation. As a result, designing, implementing, and managing AI experiments (and the associated software engineering tools) is at times an AI product in itself.
Read the complete blog below for a more detailed description of the vendors and their capabilities. This is not surprising given that DataOps enables enterprise data teams to generate significant business value from their data. Testing and Data Observability. Download the 2021 DataOps Vendor Landscape here.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Today’s digital data has given the power to an average Internet user a massive amount of information that helps him or her to choose between brands, products or offers, making the market a highly competitive arena for the best ones to survive. First things first – organizing and prioritizing your marketing data.
Third, any commitment to a disruptive technology (including data-intensive and AI implementations) must start with a business strategy. These changes may include requirements drift, data drift, model drift, or concept drift. A business-disruptive ChatGPT implementation definitely fits into this category: focus first on the MVP or MLP.
Data lineage is an essential tool that among other benefits, can transform insights, help BI teams understand the root cause of an issue, as well as help achieve and maintain compliance. Through the use of data lineage, companies can better understand their data and its journey. DataEngineering Podcast.
Enterprise data is brought into data lakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Under Actions , choose Open Jupyter Navigate to Jupyter console, select New , and then choose Console.
In June 2021, we asked the recipients of our Data & AI Newsletter to respond to a survey about compensation. The average salary for data and AI professionals who responded to the survey was $146,000. We didn’t use the data from these respondents; in practice, discarding this data had no effect on the results.
1) What Is Data Interpretation? 2) How To Interpret Data? 3) Why Data Interpretation Is Important? 4) Data Analysis & Interpretation Problems. 5) Data Interpretation Techniques & Methods. 6) The Use of Dashboards For Data Interpretation. Business dashboards are the digital age tools for big data.
The importance of data science and machine learning continues to grow in business and beyond. I did my part this year to spread interest in data science to more people. Below are my top 10 blog posts of 2018: Favorite Data Science Blogs, Podcasts and Newsletters. Click image to enlarge.
2024 Gartner Market Guide To DataOps We at DataKitchen are thrilled to see the publication of the Gartner Market Guide to DataOps, a milestone in the evolution of this critical software category. At DataKitchen, we think of this is a ‘meta-orchestration’ of the code and tools acting upon the data.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that lets you analyze your data at scale. Amazon Redshift Serverless lets you access and analyze data without the usual configurations of a provisioned data warehouse. For more information, refer to Amazon Redshift clusters.
Alation increases search relevancy with data domains, adds new data governance capabilities, and speeds up time-to-insight with an Open Connector Framework SDK. Categorize data by domain. As a data consumer, sometimes you just want data in a single category. Data quality is essential to data governance.
Analyzing the hiring behaviors of companies on its platform, freelance work marketplace Upwork has AI to be the fastest growing category for 2023, noting that posts for generative AI jobs increased more than 1000% in Q2 2023 compared to the end of 2022, and that related searches for AI saw a more than 1500% increase during the same time.
These microservices are provided as downloadable software containers used to deploy enterprise applications, Nvidia said in an official blog post. They’ll be accessible via Amazon SageMaker, Google Kubernetes Engine, and Microsoft Azure AI, and integrations with AI frameworks like Deepset, LangChain and LlamaIndex are also supported.
Introduction In the real world, obtaining high-quality annotated data remains a challenge. This blog post summarizes our findings, focusing on NER as a first-step key task for knowledge extraction. Data In Natural Language Processing (NLP), domain-specific knowledge plays a crucial role in the accuracy of tasks like NER.
The market for data warehouses is booming. While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around data lakes. We talked about enterprise data warehouses in the past, so let’s contrast them with data lakes. Data Warehouse. billion by 2030.
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
In the multiverse of data science, the tool options continue to expand and evolve. While there are certainly engineers and scientists who may be entrenched in one camp or another (the R camp vs. Python, for example, or SAS vs. MATLAB), there has been a growing trend towards dispersion of data science tools. Data Languages.
In a recent blog, we talked about how, at DataRobot , we organize trust in an AI system into three main categories: trust in the performance in your AI/machine learning model , trust in the operations of your AI system, and trust in the ethics of your modelling workflow, both to design the AI system and to integrate it with your business process.
One of the most important ways that marketers can benefit from AI is with search engine marketing. It is important to understand the role that AI is playing with new search engine algorithms. You can use a number of new tools that rely on data analytics to improve your strategy. What is Latent Semantic Indexing?
There is not a clear line between business intelligence and analytics, but they are extremely connected and interlaced in their approach towards resolving business issues, providing insights on past and present data, and defining future decisions. Your Chance: Want to extract the maximum potential out of your data?
Building a data lake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based data lake, require handling data at a record level.
The Syntax, Semantics, and Pragmatics Gap in Data Quality Validate Testing Data Teams often have too many things on their ‘to-do’ list. They have a backlog full of new customer features or data requests, and they go to work every day knowing that they won’t and can’t meet customer expectations.
Our annual Data Impact Awards are all about celebrating organizations that are unlocking the maximum value from their data in order to drive the business forward. One category that highlighted some fantastic examples of customers doing just that, was The Enterprise Data Cloud award. million and has 10,000 employees.
Concerning professional growth, development, and evolution, using data-driven insights to formulate actionable strategies and implement valuable initiatives is essential. Data visualization methods refer to the creation of graphical representations of information. That’s where data visualization comes in.
In that context, Real-Time reports are an impressive feat of engineering by the team at Google. And, that's not all, when you consider that it is segmented data, across multiple dimensions, it really is impressive. If it can't, figure out what the time from insight to action is, then optimize the data to insight process.
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in data lakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your data lake.
This month’s #ClouderaLife Spotlight features software engineer Amogh Desai. Snatching victory from the jaws of defeat Amogh and his fellow hackathon team members felt the rush of victory after winning Cloudera’s 2022 global hackathon in the product development category. One way he does this is through blog writing.
You are trying really hard to figure out how to improve the performance but you are stymied by the fact that there is ton of data and you have no idea where to start. If you don't fall into those two categories you need to pay very careful attention to this metric. Find out the quality of traffic coming from the search engines.
In the build-up to this year’s Data Impact Awards, we’re looking back at last year’s winners. Last year’s awards saw OVO crowned as Data Champions. OVO – 2020’s Data Champion award winner . To do this, OVO built UnCover, a contextual offer engine capable of processing the large-scale volumes of data generated by its users.
Apache Hudi is an open table format that brings database and data warehouse capabilities to data lakes. Apache Hudi helps dataengineers manage complex challenges, such as managing continuously evolving datasets with transactions while maintaining query performance.
Presenting the cross-sell recommendation engine. With the aid of a cross-sell recommendation engine, casinos can take this information a step further. With the aid of a cross-sell recommendation engine, casinos can take this information a step further. The benefits of a cross-sell recommendation engine.
Therefore, I wanted to comment on the rise of ChatGPT and how I think AI tools could impact data visualisation work now and in the future, as I believe it’s significant. After consuming a number of YouTube videos, blog posts, articles, and playing around with ChatGPT, I felt the need to write down my thoughts and observations on the topic.
The reason is simple: The ecosystem within which you function on the web contains mind blowing data you can use to become better. It is simply magnificent what you can do with freely available data on the web about your direct competitors, your industry segment and indeed how people behave on search engines and other websites.
This year, OVO has done just that, setting itself apart to win the Data Champions category at our 2020 Data Impact Awards. The Data Champions category is for those solutions that are bringing the best of both agility and risk mitigation together, to support multiple use cases.
This marks a full decade since some of the brightest minds in data science formed DataRobot with a singular vision: to unlock the potential of AI and machine learning for all—for every business, every organization, every industry—everywhere in the world. How to Thrive in the Age of Data Dominance. 10 Keys to AI Success. Download Now.
Multimodal search enables both text and image search capabilities, transforming how users access data through search applications. Amazon OpenSearch Service and Amazon OpenSearch Serverless support the vector engine, which you can use to store and run vector searches. and specialized field data types, such as knn_vector.
To this six-part series, where we’ll look at how to get control of the health of your Cloudera Data platform (CDP) environment. With each blog we’ll outline the symptoms and root causes of common environmental health challenges and prescribe solutions. That’s observability. We’ve done it too. We confess.
AI users say that AI programming (66%) and data analysis (59%) are the most needed skills. Given the cost of equipping a data center with high-end GPUs, they probably won’t attempt to build their own infrastructure. Few nonusers (2%) report that lack of data or data quality is an issue, and only 1.3%
It adds tables to compute engines including Spark, Trino, PrestoDB, Flink, and Hive using a high-performance table format that works just like a SQL table. Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback. AWS Glue 3.0
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








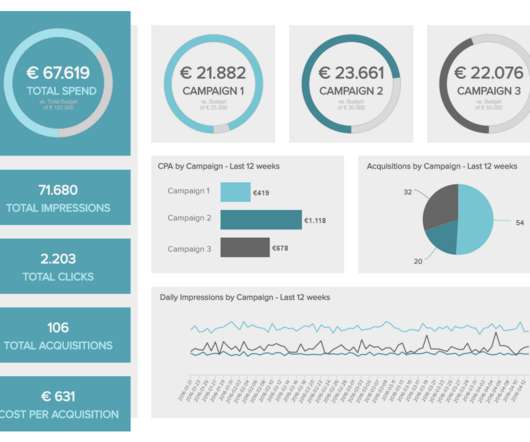














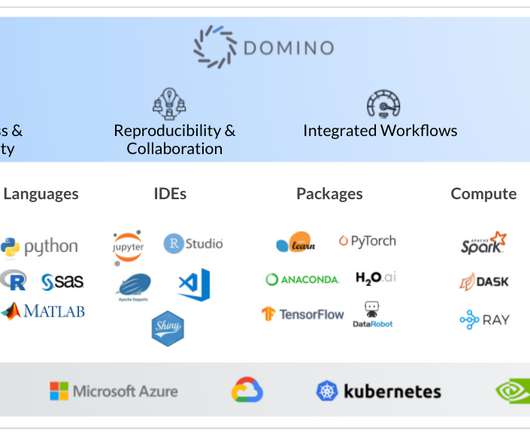


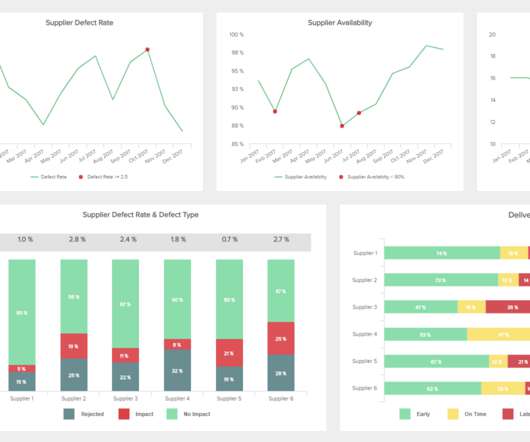



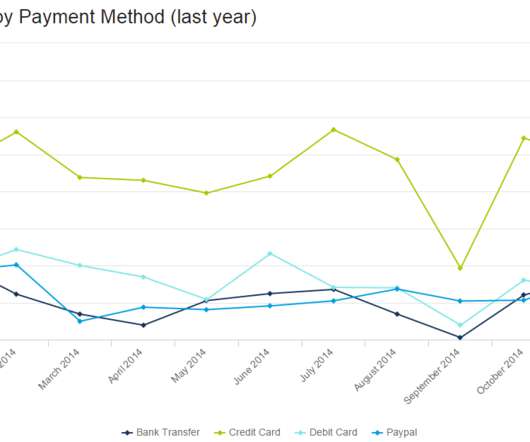























Let's personalize your content