This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deeplearning. In this blog post, we demonstrate how you can use DJL within Kinesis Data Analytics for Apache Flink for real-time machine learning inference. Then we feed the array to the model and apply a forward pass.
While artificial intelligence (AI), machine learning (ML), deeplearning and neural networks are related technologies, the terms are often used interchangeably, which frequently leads to confusion about their differences. This blog post will clarify some of the ambiguity. Machine learning is a subset of AI.
AWS DeepLearning Containers now support Tensorflow 2.0 AWS DeepLearning Containers are docker images which are preconfigured for deeplearning tasks. This blog post acts more like a step-by-step tutorial. It walks through classifying Yahoo Answers into different categories. Education/Courses.
All of my top blog posts of 2018 (most reads) are all related to data science, with posts that address the practice of data science, artificial intelligence and machine learning tools and methods that are commonly used and even a post on the problems with the Net Promoter Score claims. Click image to enlarge.
Analyzing the hiring behaviors of companies on its platform, freelance work marketplace Upwork has AI to be the fastest growing category for 2023, noting that posts for generative AI jobs increased more than 1000% in Q2 2023 compared to the end of 2022, and that related searches for AI saw a more than 1500% increase during the same time.
Read the complete blog below for a more detailed description of the vendors and their capabilities. Because it is such a new category, both overly narrow and overly broad definitions of DataOps abound. Download the 2021 DataOps Vendor Landscape here. DataOps is a hot topic in 2021.
People tend to use these phrases almost interchangeably: Artificial Intelligence (AI), Machine Learning (ML) and DeepLearning. DeepLearning is a specific ML technique. Most DeepLearning methods involve artificial neural networks, modeling how our bran works.
And in the world of e-commerce, assigning product descriptions to the most fitting product category ensures quality control. . Very few real-world use cases have categories that are eternally set in stone. The reality is that new classes, topics, and categories will likely emerge over time as business needs evolve.
Niels Kasch , cofounder of Miner & Kasch , an AI and Data Science consulting firm, provides insight from a deeplearning session that occurred at the Maryland Data Science Conference. DeepLearning on Imagery and Text. DeepLearning on Imagery. So how does representation learning in DL work?
This blog will reveal or show the difference between the data warehouse and the data lake. This is true when it comes to deeplearning that needs scalability in the growing number of training information. However, a data lake functions for one specific company, the data warehouse, on the other hand, is fitted for another.
The imperative to deliver meaningful change and value through innovation is why the Data for Enterprise AI category at the Data Impact Awards has never been more of the moment than it is today. UOB used deeplearning to improve detection of procurement fraud, thereby fighting financial crime. We hope to see your entry next year!
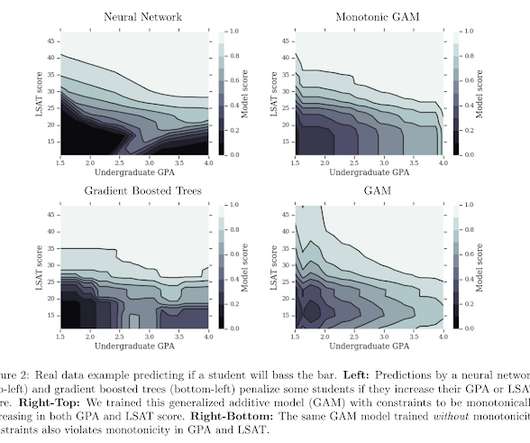
On the other hand, sophisticated machine learning models are flexible in their form but not easy to control. This blog post motivates this problem more fully, and discusses monotonic splines and lattices as a solution. In this blog post, we describe how we impose common-sense “shape constraints” on complex models.
If you’re a regular reader of the DataRobot blog, you likely fall into one of two categories. Our blogs target these two groups because they are the primary people who interact with our software. Until now.
Key categories of tools and a few examples include: Data Sources. Languages are typically broken into two categories, commercial and open source. Originally created for software development, Python is used in a variety of contexts, including deeplearning research and model deployment. They range from flat files (e.g.
Machine learning algorithms can be trained to recognize patterns in the data and classify data accordingly. For example, an AI system could be trained to classify emails into categories like “sensitive” or “restricted” based on patterns it has learned from a training dataset.
Our goal is to take the incredible data science and machine learning research developments we see emerging from academia and large industrial labs, and bridge the gap to products and processes that are useful to practitioners working across industries. Evolving Research At Cloudera Fast Forward. Structural Time Series.
Within USEEIO, goods and services are categorized into 66 spend categories, referred to as commodity classes, based on their common environmental characteristics. This involves mapping the 15.909 sectors found across the Eora26 categories and more detailed national sector classifications to the USEEIO 66 spend categories.
Data: AI systems learn and make decisions based on data, and they require large quantities of data to train effectively, especially in the case of machine learning (ML) models. text, images, audio and more), which enables the system to generalize its learning to new, unseen data.
Unlike basic machine learning models, deeplearning models allow AI applications to learn how to perform new tasks that need human intelligence, engage in new behaviors and make decisions without human intervention. The three kinds of AI based on capabilities 1. Explore watsonx.ai
The official (first) repo is tensorflow/tensor2tensor that has topics: machine-learning reinforcement-learningdeep-learning machine-translation tpu. By exploring the first topic machine-learning , we find 117k Github repos. Wikipedia categories are used to classify articles, and to form a hierarchy.
Ludwig is a tool that allows people to build data-based deeplearning models to make predictions. When Google talked about releasing this tool in its blog, the brand pointed out that if you don’t protect user data, you risk losing people’s trust. The website breaks down the types of charts into categories.
Machine learning types Machine learning algorithms fall into five broad categories: supervised learning, unsupervised learning, semi-supervised learning, self-supervised and reinforcement learning. AI studio The post Five machine learning types to know appeared first on IBM Blog.
AI and machine learning (ML) are not just catchy buzzwords; they’re vital to the future of our planet and your business. Know the limitations of your existing dataset and answer these questions: What categories of data are there? Datasets have quickly grown too huge, complex, and fast-moving for humans to grapple with.
This blog discusses quantifications, types, and implications of data. DeepLearning, a subset of AI algorithms, typically requires large amounts of human annotated data to be useful. The post The Rise of Unstructured Data appeared first on Cloudera Blog. The word “data” is ubiquitous in narratives of the modern world.
Figure 1: The Data Monetization Lifecycle The raw data that fuels data monetization will come from three source categories: enterprise systems, external data and personal data. Realize : Each data service has an agreed unit of value which is transacted and measured.
Image credit: [link] As the title suggests, this is a story about a question that may resonate well with many machine learning practitioners trying to build applications in the real world, where clean and annotated data on a specific problem can be sparse— How do we leverage the power of AI when we have very little data? Meta-Learning v.s.
CPUs are sufficient for basic AI workloads, but GPUs are more ideally suited for deeplearning workloads, which can require multiple large datasets and scalable neural networks. Perhaps one of the biggest issues that falls into this category is not having a full understanding of the scalability requirements.
These categories are relatively broad (e.g. To measure this sentiment, Derek classified each sentence in a review as belonging to one of five categories: Culture & Values, Work/Life Balance, Senior Management, Compensation & Benefits, Career Opportunities (the same five dimensions Glassdoor asks employees to rate along).
In this blog, I will share how I built Pair , a scalable web application that takes in a product image, analyzes its design features using convolutional neural network, and recommends products in other categories with similar style elements. In this project, I was curious to see if deeplearning approaches?—?specifically
In this blog, I’ll describe how to solve this with Contextual Topic Identification, leveraging machine learning methods to identify semantically similar groups and surface relevant category tags of the reviews. Steam review screenshot Dataset I used the Steam Review Dataset , published on Kaggle as a .csv csv file.
By 2025, AI will be the top category driving infrastructure decisions, due to the maturation of the AI market, resulting in a tenfold growth in compute requirements. For accurate predictions, companies now use various data models, machine and deeplearning techniques to continuously improve and refine the quality of the outcome.
With that said, recent advances in deeplearning methods have allowed models to improve to a point that is quickly approaching human precision on this difficult task. LSTMs and other recurrent neural networks RNNs are probably the most commonly used deeplearning models for NLP and with good reason. More advanced models.
NASA [Public domain] In this blog, I’ll discuss how I worked collaboratively with various domain experts, using reinforcement learning to develop innovative solutions in rocket engine development. The biggest categories of cost for hardware designers and manufacturers are testing, verification, and calibration of their control systems.
When sales performance is analyzed and correlated with marketing data, for instance, it is critical to make sure that across the board there is good alignment regarding the categories of products, the regions, the suppliers and the relationships between them. We use other deeplearning techniques for such tasks.
Keras is an open source deeplearning API that was written in Python and runs on top of Tensorflow, so it’s a little more user-friendly and high-level than Tensorflow. If you’d like to read more about all of the different optimizers out there, check out this excellent Medium article and this wonderfully detailed blog post.
Text classification: Useful for tasks like sentiment classification, spam filtering and topic classification, text classification involves categorizing documents into predefined classes or categories. And with advanced software like IBM Watson Assistant , social media data is more powerful than ever.
Model explainability is typically grouped into the categories of Global Explainability and Local Explainability. Because our dataset contains image data, DataRobot used models that contain deeplearning based image featurizers. Local Explainability tells you why the model made a certain prediction for an individual row.
Filtering email ML algorithms in Google’s Gmail automate filtering customers’ email into Primary, Social and Promotions categories while also detecting and rerouting spam to a spam folder. Reinforcement learning uses ML to train models to identify and respond to cyberattacks and detect intrusions.
Across well over 100 nominations, this year’s 11 winners, representing nine categories and six industries, demonstrate outstanding innovation to accelerate their mission, technical advancement, and overall impact. Congratulations to the Sixth Annual Data Impact Awards winners appeared first on Cloudera Blog.
Taxonomies, with their hierarchical structure, enable the identification of broader categories or themes present within the content. The semantic model leverages ontologies and taxonomies.
This blog post provides a concise session summary, a video, and a written transcript. and drop your deeplearning model resource footprint by 5-6 orders of magnitude and run it on devices that don’t even have batteries. Paco Nathan presented, “Data Science, Past & Future” , at Rev. Session Summary.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content