This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These data processing and analytical services support Structured Query Language (SQL) to interact with the data. Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL, business intelligence (BI), and reporting tools. Wait a few seconds and run the following SQL query to see integration in action.
Read the complete blog below for a more detailed description of the vendors and their capabilities. Because it is such a new category, both overly narrow and overly broad definitions of DataOps abound. Redgate — SQL tools to help users implement DataOps, monitor database performance, and provision of new databases. .
This example shows additional information for the net profit: the top 5 product categories by using a drill-through. Sometimes referred to as nested charts, they are especially useful in tables, where you can access additional drilldown options such as aggregated data for categories/breakdowns (e.g. 8) Advanced Data Options.
64% of the respondents took part in training or obtained certifications in the past year, and 31% reported spending over 100 hours in training programs, ranging from formal graduate degrees to reading blog posts. The tools category includes tools for building and maintaining data pipelines, like Kafka. Salaries by Programming Language.
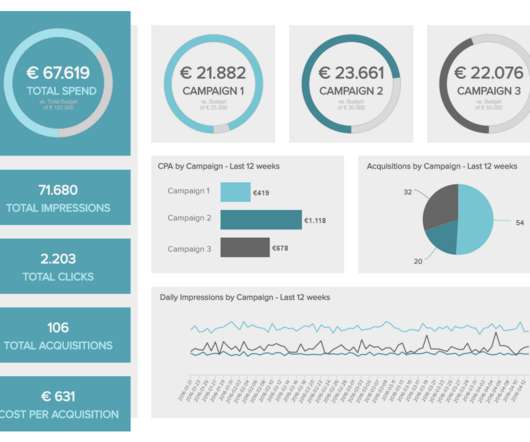
As we have already talked about in our previous blog post on sales reports for daily, weekly or monthly reporting, you need to figure out a couple of things when launching and executing a marketing campaign: are your efforts paying off? 1) Blog Traffic And Blog Leads Report. 2) Marketing KPI Report. click to enlarge**.
All of my top blog posts of 2018 (most reads) are all related to data science, with posts that address the practice of data science, artificial intelligence and machine learning tools and methods that are commonly used and even a post on the problems with the Net Promoter Score claims. Click image to enlarge.
The groups for the illustration can be broadly classified into the following categories: Regional sales managers will be granted access to view sales data only for the specific country or region they manage. Args: sql (str): The SQL query to execute. redshift_client (boto3.client): client): The Redshift Data API client.
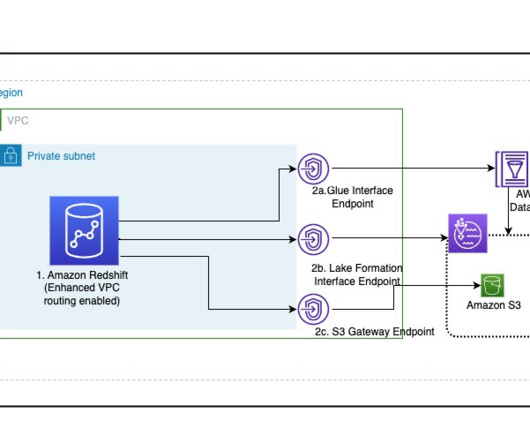
Solution overview To explain this setup, we present the following architecture, which integrates Amazon S3 for the data lake (Iceberg table format), Lake Formation for access control, AWS Glue for ETL (extract, transform, and load), and Athena for querying the latest inventory data from the Iceberg tables using standard SQL.
It is considered a “complex to license and expensive tool” that often overlaps with other products in this category. AWS Data Pipeline : AWS Data Pipeline can be used to schedule regular processing activities such as SQL transforms, custom scripts, MapReduce applications, and distributed data copy. Conclusion.
It adds tables to compute engines including Spark, Trino, PrestoDB, Flink, and Hive using a high-performance table format that works just like a SQL table. We use iceberg-blog-cluster. Apache Iceberg integration is supported by AWS analytics services including Amazon EMR , Amazon Athena , and AWS Glue. Choose Next.
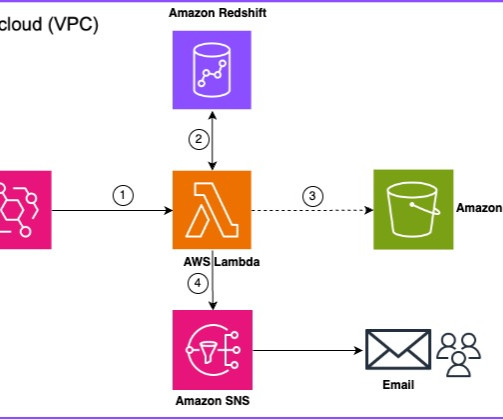
For Stack name , enter a name for the stack, for example, blog-redshift-advisor-recommendations. Next, the function will summarize recommendations by each provisioned cluster (for all clusters in the account or a single cluster, depending on your settings) based on the impact on performance and cost as HIGH, MEDIUM, and LOW categories.
Key categories of tools and a few examples include: Data Sources. SQL based) to big data stores (e.g. Languages are typically broken into two categories, commercial and open source. The post Data Science Tools: Understanding the Multiverse appeared first on Data Science Blog by Domino. They range from flat files (e.g.
Amazon Redshift Spectrum enables you to run Amazon Redshift SQL queries on data stored in Amazon S3. For Service category , select AWS services. For Service category , select AWS services. For Service category , select AWS services. Redshift Spectrum uses the AWS Glue Data Catalog as a Hive metastore. Congratulations!
As another example, if your sales went up by 10%, Sisense might explain that the increase was attributable to both a specific product category and a certain age group of customer with a visual display of the breakdown. For every query, Sisense translates live widget information into SQL data.
In this blog, I’ll talk about the data catalog and data intelligence markets, and the future for Alation. While we’re widely credited with driving the creation of the data catalog category 1 , Alation isn’t just a data catalog company. We’re excited to continue to innovate and lead the data intelligence category for years to come!
Flink SQL is a data processing language that enables rapid prototyping and development of event-driven and streaming applications. Flink SQL combines the performance and scalability of Apache Flink, a popular distributed streaming platform, with the simplicity and accessibility of SQL. You can view the code here.
When Google talked about releasing this tool in its blog, the brand pointed out that if you don’t protect user data, you risk losing people’s trust. Users only need to include the respective path in the SQL query to get to work. It allows secure and interactive SQL analytics at the petabyte scale. Kubernetes.
As an example of this, in this post we look at Real Time Data Warehousing (RTDW), which is a category of use cases customers are building on Cloudera and which is becoming more and more common amongst our customers. SQL editor for running Hive and Impala queries. SQL editor for running Impala+Kudu queries. General Purpose RTDW.
Apache Iceberg is an open table format for large datasets in Amazon Simple Storage Service (Amazon S3) and provides fast query performance over large tables, atomic commits, concurrent writes, and SQL-compatible table evolution. KiB 7ffbc860/my_ns/my_table/00328-1642-5ce681a7-dfe3-4751-ab10-37d7e58de08a-00015.parquet
All BI teams are capable of producing a data dictionary, whether they use data dictionary SQL tools or Excel, but manual methods, such as the creation of a spreadsheet, are less reliable and far more time-consuming than an automated data dictionary tool. Our blog post will help you figure it out! Take Me to the Blog Post.
In the first blog of the Universal Data Distribution blog series , we discussed the emerging need within enterprise organizations to take control of their data flows. In this second installment of the Universal Data Distribution blog series, we will discuss a few different data distribution use cases and deep dive into one of them. .
It lists forty-five metrics to track across their Operational categories: DataOps, Self-Service, ModelOps, and MLOps. However, it is not just the speed at which you can deploy some new SQL, a new data set, a new model, or another asset from development into production. It takes them too long to write SQL, python, or make a dashboard.
The distinction between all three categories can become blurred, for example if a business analyst also provides code for new business systems and applications. With strong technical abilities, database specialists are likely to be at ease with both SQL databases like MySQL and PostgreSQL, and NoSQL technologies such as MongoDB and Redis.
Flink SQL does this and directs the results of whatever functions you apply to the data into a sink. Therefore, there are two common use cases for Hive tables with Flink SQL: A lookup table for enriching the data stream. Registering a Hive Catalog in SQL Stream Builder. id` VARCHAR(2147483647), `category` VARCHAR(2147483647).
On January 3, we closed the merger of Cloudera and Hortonworks — the two leading companies in the big data space — creating a single new company that is the leader in our category. Our new Chief Product Officer Arun Murthy has a post up on the Hortonworks blog , explaining what the future holds in product strategy and development.
Dimensions provide answers to exploratory business questions by allowing end-users to slice and dice data in a variety of ways using familiar SQL commands. It contains different categories of columns: Keys – It contains two types of keys: customer_sk is the primary key of this table.
In this blog we will cover the new features in the 7.1.6 delivers benefits in the following categories: Better Upgrade Support . Supports both SQL and No SQL with 15 – 20% better throughput performance. appeared first on Cloudera Blog. and HDP 2.6.5. and HDP 2.6.5. CDP Private Cloud Base 7.1.6
And, the Enterprise Data Cloud category we invented is also growing. Future-proof, “no-code” connectors enable customers to extract data from a wide range of popular data sources, and multi-level transformations are automatically orchestrated using, just, SQL. The post Turning the page appeared first on Cloudera Blog.
In this blog we will take you through a persona-based data adventure, with short demos attached, to show you the A-Z data worker workflow expedited and made easier through self-service, seamless integration, and cloud-native technologies. Assumptions. In our data adventure we assume the following: . Company data exists in the data lake.
I attended the machine learning meetup and reached out to Mawer for the permissions to excerpt Mawer’s work for this blog post. sql/ <- SQL source code ? ??? If you are interested in your data science work being covered in this blog series, please send us an email at content(at)dominodatalab(dot)com.
SQL-driven Streaming App Development. SQL Stream Builder (part of CDF). SQL Stream Builder reduces time to develop streaming use cases using Cloudera Data Flow, by offering a familiar SQL-based query language (Continuous SQL) . Single-cloud visibility with Ambari. SDX and Cloudera Control Plane. Not available.
This year Quest® (including erwin) is competing in 7 out of 29 product / solution categories: Best CDC Solution (Quest Shareplex). Concerned about meeting your personal data regulatory compliance responsibilities across your SQL Server estate? 2022 DBTA Reader’s Choice Awards appeared first on erwin Expert Blog.
Additionally, the real-time view is transparent for the front-end SQL. The business teams can embrace real-time with their most familiar SQL tools. The ‘category’ is the business partition column of the Hive ORC/Parquet table. Therefore, it’s more adopted by the ecosystem of BI tools and applications. Design Detail.
While some functionality mirrors how it was done in Dynamics AX, there have been changes to how you create SQL Server Reporting Services (SSRS) reports, ad-hoc reports, and custom reports in D365FO. In this blog post, we are going to cover Data Entities. What is a Data Entity? General ledger). Reference (Ex. Tax Codes). Master (Ex.
We need to create two categories of dashboards. For both categories, especially the valuable second kind of dashboards, we need words – lots of words and way fewer numbers. I do not think unwell of them, you''ll find plenty, what I now call CDPs, on this blog. I believe the solution is multi-fold (and when is it not? : )).
Snowpipe data ingestion might be too slow for three use categories: real-time personalization, operational analytics, and security. With AWS Glue and Snowflake, customers get the added benefit of Snowflake’s query pushdown, which automatically pushes Spark workloads, translated to SQL, into Snowflake. Real-Time Personalization.
This blog is for anyone who was interested but unable to attend the conference, or anyone interested in a quick summary of what happened there. The actual unveiling was a bit underwhelming as the SQL console left a lot to be desired, and outside of serverless auto-scaling functionality there was no “wow” factor.
End users access this data using third-party SQL clients and business intelligence tools. Technical Solution To implement customer needs for securing different categories of data, it requires the definition of multiple AWS IAM roles, which requires knowledge in IAM policies and maintaining those when permission boundary changes.
A global fast-moving consumer goods (FMCG) enterprise needed to modernize its product portfolio, focusing on high-growth categories like pet care, coffee and consumer health.
McKinsey lists building capabilities for the workforce of the future as one of five categories of factors improving the chances of a successful digital transformation. The post Workforce competency key to digital transformation efforts, more possibilities available through Skillsfuture Singapore appeared first on Cloudera Blog.
Do they want to get more social reach on the blog posts your company is putting out? The vast majority of people who fall into this category are what is called color impaired. Do they care about helping their staff get more sales and leads? Are they hoping to manage customer support calls more effectively? of women are colorblind.
All BI teams are capable of producing a data dictionary, whether they use data dictionary SQL tools or Excel, but manual methods, such as the creation of a spreadsheet, are less reliable and far more time-consuming than an automated data dictionary tool. Our blog post will help you figure it out! Take Me to the Blog Post.
In this new blog series, we will take a closer look at some of the most innovative partners, and how the Cloudera platform is helping them deliver groundbreaking solutions to our customers. The post Cloudera Data Warehouse – A Partner Perspective appeared first on Cloudera Blog. Director of Products and Solutions, Arcadia Data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content