This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
“Big data is at the foundation of all the megatrends that are happening.” – Chris Lynch, big data expert. We live in a world saturated with data. At present, around 2.7 Zettabytes of data are floating around in our digital universe, just waiting to be analyzed and explored, according to AnalyticsWeek. In 2013, less than 0.5% click for book source**.
DataOps automation provides a way to boost innovation and improve collaboration related to data in pharmaceutical research and development (R&D). A typical R&D organization has many independent teams, and each team chooses a different technology platform. Mastery of Heterogeneous Tools.
In this blog series, we will discuss each of these deployments and the deployment choices made along with how they impact reliability. In Part 1, the discussion is related to: Serial and Parallel Systems Reliability as a concept, Kafka Clusters with and without Co-Located Apache Zookeeper, and Kafka Clusters deployed on VMs. .
Dean Wampler provides a distilled overview of Ray, an open source system for scaling Python systems from single machines to large clusters. this post on the Ray project blog ?. Ray is an open-source system for scaling Python applications from single machines to large clusters. Introduction. Ray: Scaling Python Applications.
Read the complete blog below for a more detailed description of the vendors and their capabilities. Download the 2021 DataOps Vendor Landscape here. DataOps is a hot topic in 2021. This is not surprising given that DataOps enables enterprise data teams to generate significant business value from their data. Meta-Orchestration .
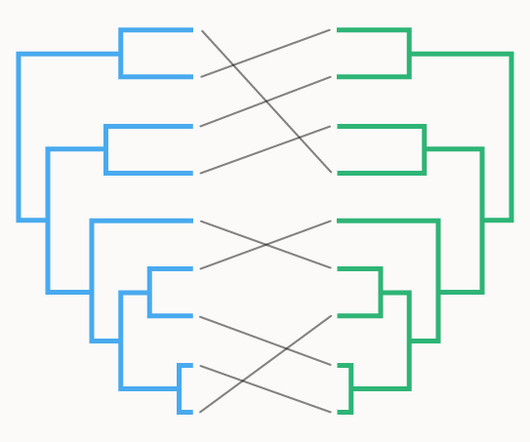
As a visualisation method, Tanglegrams are often implemented to compare and display the concordance (similarity of traits) between two datasets of hierarchical clustering. Tanglegram comparing dendrograms between volume and site index by the ADA and GADA approach, based on hierarchical clustering, in clonal teak (Tectona grandis Linn F.)
Cluster Analysis is an important problem in data analysis. Data scientists use clustering to identify malfunctioning servers, group genes with similar expression patterns, and perform various other applications. There are many families of data clustering algorithms, and you may be familiar with the most popular one: k-means.
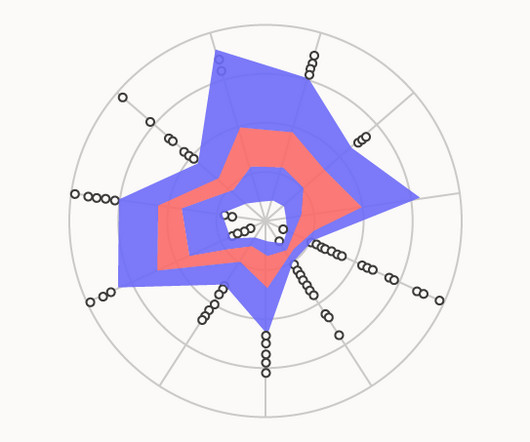
This combination enables the comparison of multivariate data across multiple classes or clusters simultaneously. This visualisation uses radar polygons that can be compared based on their shape and thickness, providing insights into data variability and similarities among classes or clusters.
Fourteen years later, there are quite a number of Hadoop clusters in operation across many companies, though fewer companies are probably creating new Hadoop clusters? Fourteen years later, there are quite a number of Hadoop clusters in operation across many companies, though fewer companies are probably creating new Hadoop clusters?—?instead
The current Amazon EMR pricing page shows the estimated cost of the cluster. In this post, we share a chargeback model that you can use to track and allocate the costs of Spark workloads running on Amazon EMR on EC2 clusters. It can help you identify cost optimizations and improve the cost-efficiency of your EMR clusters.
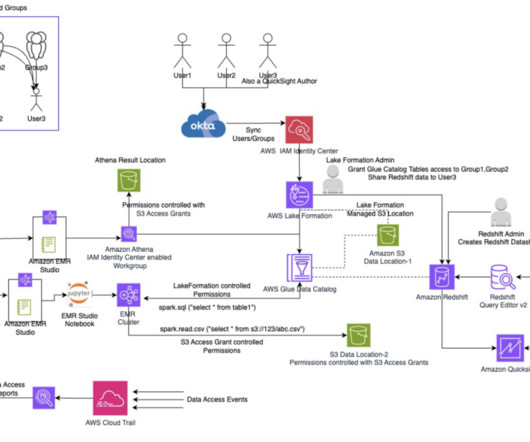
This approach empowers administrators to grant access directly based on existing user and group memberships federated from external IdPs, rather than relying on IAM users or roles. Solution overview Let’s consider a fictional company, OkTank. The user identities are managed externally in an external IdP: Okta.
In this blog we show what the changes in behavior of data are in high dimensions. In our next blog we discuss how we try to avoid these problems in applied data analysis of high dimensional data. Each property is discussed below with R code so the reader can test it themselves. Data Has Properties. P >> N) ).
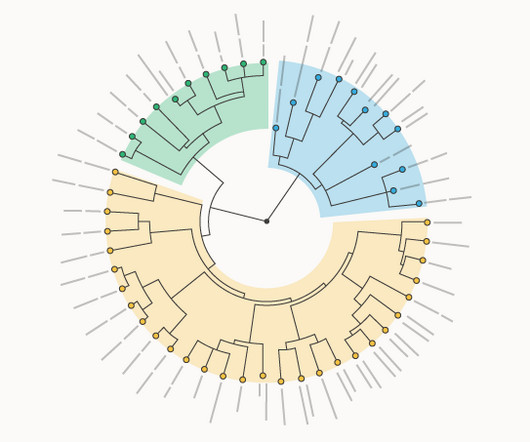
A Circular Dendrogram is a variation of a Dendrogram that visualises the structure of hierarchical clustering on a polar (radial) layout. Clades closer to the edges of the diagram show individual entities, while the more central clades represent groups of entities clustered together. js Graph Gallery (D3.js) js) Observable (D3.js)
Ray: is an open-source library framework that offers a simple API for scaling applications from a single computer to large clusters. The library contains an assortment of tools for machine learning and statistical modeling including classification, regression, clustering and dimensionality reduction and predictive data analysis.
This post is co-written with Julien Lafaye from CFM. Capital Fund Management ( CFM ) is an alternative investment management company based in Paris with staff in New York City and London. CFM takes a scientific approach to finance, using quantitative and systematic techniques to develop the best investment strategies.
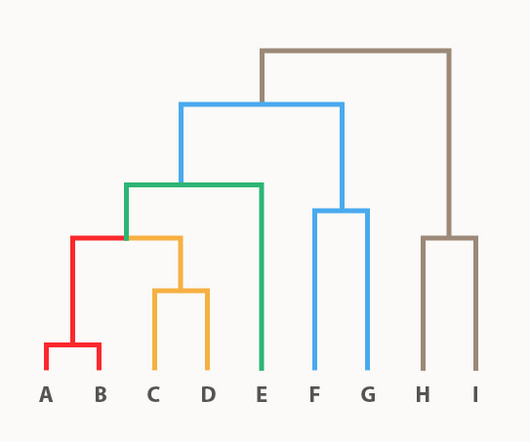
A Dendrogram is a variation of a Tree Diagram that illustrates the arrangement of clusters formed by hierarchical clustering. Clades closer to the bottom of the diagram show individual entities, while higher clades represent groups of entities that have been clustered together. Each leaf represents an individual entity.
In the previous blog post in this series, we walked through the steps for leveraging Deep Learning in your Cloudera Machine Learning (CML) projects. pip install -r requirements.txt. Introduction. In this tutorial, we will illustrate how RAPIDS can be used to tackle the Kaggle Home Credit Default Risk challenge. Get the Dataset.
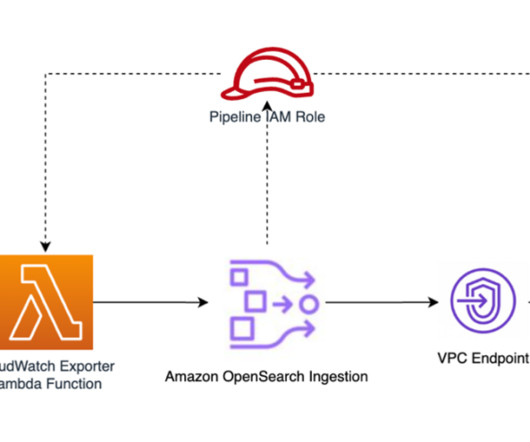
At the time of publishing this blog post, these subscription filters support delivering logs to Amazon OpenSearch Service provisioned clusters only. In this blog post, we will show how to use Amazon OpenSearch Ingestion to deliver CloudWatch logs to OpenSearch Serverless in near real-time.
Text data is proliferating at a staggering rate, and only advanced coding languages like Python and R will be able to pull insights out of these datasets at scale. R or Python?”. People looking into data science languages are usually confused about which language they should learn first: R or Python. R: Analytics powerhouse.
By automating cluster deployment this way, you reduce the risk of misconfiguration, promote consistent deployments across multiple clusters in your environment, and help to deliver business value more quickly. . This blog will walk through how to deploy a Private Cloud Base cluster, with security, with a minimum of human interaction.
Additionally, with version 6.15, Amazon EMR introduces access control protection for its application web interface such as on-cluster Spark History Server, Yarn Timeline Server, and Yarn Resource Manager UI. Besides demonstrating with Hudi here, we will follow up with other OTF tables with other blogs.
Replication ( covered in this previous blog article ) has been released for a while and is among the most used features of Apache HBase. That means any pre-existing data on all clusters involved in the replication deployment will still need to get copied between the peers in some other way. HashTable/SyncTable in a nutshell.
Main benefits of COD include: Auto-scaling – based on the workload utilization of the cluster and will soon have the ability to scale up/down the cluster. In this blog, I will demonstrate how COD can easily be used as a backend system to store data and images for a simple web application. *For import phoenixdb.cursor.
Amazon Redshift RSQL is a native command-line client for interacting with Amazon Redshift clusters and databases. You can connect to an Amazon Redshift cluster, describe database objects, query data, and view query results in various output formats. The RSQL job performs ETL and ELT operations on the Amazon Redshift cluster.
Our previous Domino Blog on the Curse of Dimensionality [2] , describes weird behaviors that emerge in data when P >> N: Points move far away from each other. High throughput screening technologies have been developed to measure all the molecules of interest in a sample in a single experiment (e.g., The 12 are listed in Table 1.
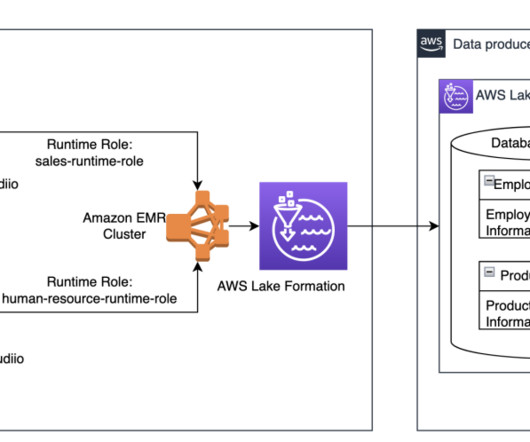
Amazon EMR Studio is an integrated development environment (IDE) that makes it straightforward for data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark. The jobs on the EMR cluster will use this runtime role to access AWS resources.
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers. The AWS Region used for this post is us-east-1.
Possible permissions (zero or more letters from the set “RWXCA”): Read (R) – can read data at the given scope. Admin (A) – can perform cluster operations such as balancing the cluster or assigning regions at the given scope. The user who runs HBase on your cluster is a superuser. normal/override.
Using an Alluvial Diagram provided the ability to track a field of interest and which cluster it belonged to over a time period. Most of the research listed below focuses on the applications of Alluvial Diagrams, but in recent years more research has been done on the construction and design of Alluvial Diagrams. By Martin Rosvall , Carl T.
In previous blog posts the Four Paths to CDP and Choosing your Upgrade or Migration Path , we covered the overall business and technical issues that go into moving your legacy platform to CDP. In this blog we shift our focus to a specific area that should be given some special attention while upgrading or migrating from CDH to CDP.
Cloudera Data Science Workbench is a web-based application that allows data scientists to use their favorite open source libraries and languages — including R, Python, and Scala — directly in secure environments, accelerating analytics projects from research to production. Add it to an existing HDP cluster, and it just works.
We covered HBOSS in this previous blog post. Unfortunately, when running the HBOSS solution against larger workloads and datasets spanning over thousands of regions and tens of terabytes, lock contentions induced by HBOSS would severely hamper cluster performance. You can access COD from your CDP console. HBase on S3 review.
This is a guest blog post co-written with SangSu Park and JaeHong Ahn from SOCAR. As companies continue to expand their digital footprint, the importance of real-time data processing and analysis cannot be overstated. SOCAR is the leading Korean mobility company with strong competitiveness in car-sharing.
In the previous blog posts, we looked at application development concepts and how Cloudera Operational Database (COD) interacts with other CDP services. In this blog post, let us see how easy it is to create a COD instance, and deploy a sample application that runs on that COD instance. . Quick start to deploy your application.
In this blog we are going to demonstrate how these audit events can be streamed to a third-party SIEM platform via syslog or they can be written to a local file where existing SIEM agents may be able to pick them up. According to research by The Ponemon Institute the average global cost of ?Insider Insider Threats? 31% in two years?
All of these techniques center around product clustering, where product lines or SKUs that are “closer” or more similar to each other are clustered and modeled together. In this blog post, we describe these strategies. Clustering by product group. The most intuitive way of clustering SKUs is by their product group.
Through a marriage of traditional statistics with fast-paced, code-first computer science doctrine and business acumen, data science teams can solve problems with more accuracy and precision than ever before, especially when combined with soft skills in creativity and communication. 3 Components of Data Science Skills. Math and Statistics Expertise.
Solution overview The following diagram illustrates the architecture that you implement through this blog post. In the current industry landscape, data lakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data.
In this blogpost, we are going to take a look at some of the OpDB related security features of a CDP Private Cloud Base deployment. We are going to talk about auditing, different security levels, security features of Data Catalog, and Client Considerations. You can find part 1 of this series, here. . User, business classification of asset accessed.
However, any user with HDFS admin or root access on cluster nodes would be able to impersonate the “hdfs” user and access sensitive data in clear text. The capability increases security and protects sensitive data from various kinds of attack that could be internal or external to the platform.
In todays data-driven world, securely accessing, visualizing, and analyzing data is essential for making informed business decisions. Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud data warehouses.
A collaboration between the Met Office and EUMETSAT, detailed in Data Proximate Computation on a Dask Cluster Distributed Between Data Centres , highlights the growing need to develop a sustainable, efficient, and scalable data science solution. This solution was inspired by work with a key AWS customer, the UK Met Office.
The audit log for the above operations, with details like time, user, path, operation, client IP address, cluster name, and Ranger policy that authorized the access, are interactively available in Apache Ranger console. In addition, Apache Ranger enables policy-based dynamic column-masking and row-filtering. Cloudera Data Platform 7.2.1
The team can allow enterprise access to VPC resources like Virtual Service Instances running applications or VPC RedHat OpenShift IBM Cloud clusters. All the tests should pass: python install -r requirements.txt pytest A note on enterprise-to-transit cross-zone routing The initial design worked well for enterprise <> spokes.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content