This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Choose Next to create your stack.
The data mesh design pattern breaks giant, monolithic enterprise dataarchitectures into subsystems or domains, each managed by a dedicated team. First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt.
It’s not enough for businesses to implement and maintain a dataarchitecture. The unpredictability of market shifts and the evolving use of new technologies means businesses need more data they can trust than ever to stay agile and make the right decisions.
However, most of this data is not new or original, much of it is copied data. For example, data about a. The post Data Minimization as Design Guideline for New DataArchitectures appeared first on Data Virtualization blog.
Data Gets Meshier. 2022 will bring further momentum behind modular enterprise architectures like data mesh. The data mesh addresses the problems characteristic of large, complex, monolithic dataarchitectures by dividing the system into discrete domains managed by smaller, cross-functional teams.
Amazon Redshift enables you to directly access data stored in Amazon Simple Storage Service (Amazon S3) using SQL queries and join data across your data warehouse and datalake. With Amazon Redshift, you can query the data in your S3 datalake using a central AWS Glue metastore from your Redshift data warehouse.
Over the years, organizations have invested in creating purpose-built, cloud-based datalakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple datalakes, each built on different technology stacks.
In the current industry landscape, datalakes have become a cornerstone of modern dataarchitecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient data analytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. 5 seconds $0.08 8 seconds $0.07 8 seconds $0.02 107 seconds $0.25
But, even with the backdrop of an AI-dominated future, many organizations still find themselves struggling with everything from managing data volumes and complexity to security concerns to rapidly proliferating data silos and governance challenges.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
Amazon SageMaker Lakehouse , now generally available, unifies all your data across Amazon Simple Storage Service (Amazon S3) datalakes and Amazon Redshift data warehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. The tools to transform your business are here.
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and dataarchitecture and views the data organization from the perspective of its processes and workflows.
Reading Time: 3 minutes At the heart of every organization lies a dataarchitecture, determining how data is accessed, organized, and used. For this reason, organizations must periodically revisit their dataarchitectures, to ensure that they are aligned with current business goals.
The Analytics specialty practice of AWS Professional Services (AWS ProServe) helps customers across the globe with modern dataarchitecture implementations on the AWS Cloud. Of those tables, some are larger (such as in terms of record volume) than others, and some are updated more frequently than others.
Data has continued to grow both in scale and in importance through this period, and today telecommunications companies are increasingly seeing dataarchitecture as an independent organizational challenge, not merely an item on an IT checklist. Previously, there were three types of data structures in telco: .
With data becoming the driving force behind many industries today, having a modern dataarchitecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Modern dataarchitectures. To eliminate or integrate these silos, the public sector needs to adopt robust data management solutions that support modern dataarchitectures (MDAs). Deploying modern dataarchitectures. Lack of sharing hinders the elimination of fraud, waste, and abuse. Forrester ).
This leads to having data across many instances of data warehouses and datalakes using a modern dataarchitecture in separate AWS accounts. We recently announced the integration of Amazon Redshift data sharing with AWS Lake Formation. Take note of this role’s ARN to use later in the steps.
In August, we wrote about how in a future where distributed dataarchitectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level.
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern dataarchitectures.
However, you can use the same file name as long as it’s from different auto-copy jobs: job_customerA_sales – s3://redshift-blogs/sales/customerA/2022-10-15-sales.csv job_customerB_sales – s3://redshift-blogs/sales/customerB/2022-10-15-sales.csv Do not update file contents. Prior to AWS, he built data warehouse solutions at Amazon.com.
Several factors determine the quality of your enterprise data like accuracy, completeness, consistency, to name a few. But there’s another factor of data quality that doesn’t get the recognition it deserves: your dataarchitecture. How the right dataarchitecture improves data quality.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalakearchitectureDatalakes are, at a high level, single repositories of data at scale.
In the ever-evolving landscape of data management, two key concepts have emerged as essential components for organizations seeking to harness the power of their data: data marts and datalakes. Understanding the distinctions […]
Today, the way businesses use data is much more fluid; data literate employees use data across hundreds of apps, analyze data for better decision-making, and access data from numerous locations. Then, it applies these insights to automate and orchestrate the data lifecycle.
Now generally available, the M&E data lakehouse comes with industry use-case specific features that the company calls accelerators, including real-time personalization, said Steve Sobel, the company’s global head of communications, in a blog post. Partner solutions to boost functionality, adoption.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes.
There’s a recent trend toward people creating datalake or data warehouse patterns and calling it data enablement or a data hub. DataOps expands upon this approach by focusing on the processes and workflows that create data enablement and business analytics. DataOps Process Hub.
“Data mesh” is a new data analytics paradigm proposed by Zhamak Dehghani, one that is designed to move organizations from monolithic architectures such as the data warehouse and the datalake to more decentralized architectures. As long-time supporters of logical.
“Data mesh” is a new data analytics paradigm proposed by Zhamak Dehghani, one that is designed to move organizations from monolithic architectures such as the data warehouse and the datalake to more decentralized architectures. As long-time supporters of logical.
Over the past decade, Cloudera has enabled multi-function analytics on datalakes through the introduction of the Hive table format and Hive ACID. Companies, on the other hand, have continued to demand highly scalable and flexible analytic engines and services on the datalake, without vendor lock-in.
One modern data platform solution that provides simplicity and flexibility to grow is Snowflake’s data cloud and platform. These Snowflake accelerators reduce the time to analytics for your users at all levels so you can make data-driven decisions faster. Security DataLake. Overall dataarchitecture and strategy.
New Data Lakehouse Enables Stronger Data Governance SoftBank needed to reduce the number of workloads on its existing platform and decided to adopt Cloudera to build a datalake capable of managing data more effectively. We believe these new data analysis capabilities will boost what we can offer to our customers.”
Many customers are extending their data warehouse capabilities to their datalake with Amazon Redshift. They are looking to further enhance their security posture where they can enforce access policies on their datalakes based on Amazon Simple Storage Service (Amazon S3). Choose Create endpoint.
The Solution: CDP Private Cloud brings a next-generation hybrid architecture with cloud-native benefits to HBL’s data platform. HBL started their data journey in 2019 when datalake initiative was started to consolidate complex data sources and enable the bank to use single version of truth for decision making.
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Compare ongoing data that is replicated from the source on-premises database to the target S3 datalake.
Carrefour Spain , a branch of the larger company (with 1,250 stores), processes over 3 million transactions every day, giving rise to challenges like creating and managing a datalake and honing down key demographic information. . Working with Cloudera, Carrefour Spain was able to create a unified datalake for ease of data handling.
This blog post is co-written with Pinar Yasar from Getir. Amazon Redshift is a fully managed cloud data warehouse that’s used by tens of thousands of customers for price-performance, scale, and advanced data analytics.
By 2025, it’s estimated that the amount of data created, consumed, and stored will reach 180 zettabytes , with up to 90% of that unstructured and nearly all of it unused for decision making. The purpose of this blog isn’t to emphasize the cyber risk of dark data but to spotlight its implications.
This blog post is co-written with Raj Samineni from ATPCO. In today’s data-driven world, companies across industries recognize the immense value of data in making decisions, driving innovation, and building new products to serve their customers. Choose the Amazon DataZone blueprint you want to enable.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










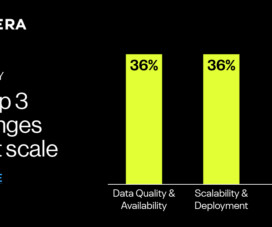

























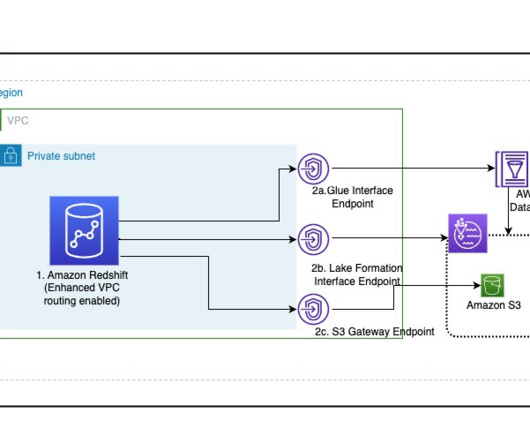















Let's personalize your content