This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern dataarchitectures.
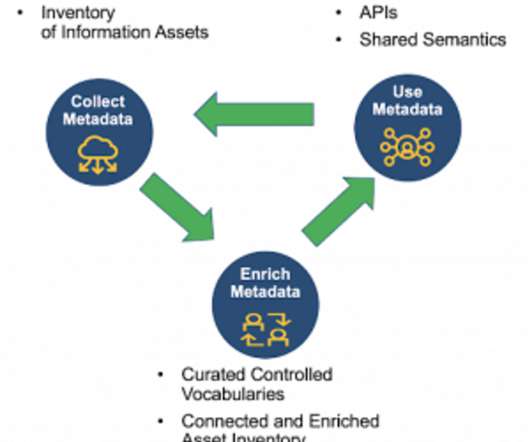
Untapped data, if mined, represents tremendous potential for your organization. While there has been a lot of talk about big data over the years, the real hero in unlocking the value of enterprise data is metadata , or the data about the data. Metadata Is the Heart of Data Intelligence.
The data mesh design pattern breaks giant, monolithic enterprise dataarchitectures into subsystems or domains, each managed by a dedicated team. The communication between business units and data professionals is usually incomplete and inconsistent. Introduction to Data Mesh. Source: Thoughtworks.
In August, we wrote about how in a future where distributed dataarchitectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
Metadata is an important part of data governance, and as a result, most nascent data governance programs are rife with project plans for assessing and documenting metadata. But in many scenarios, it seems that the underlying driver of metadata collection projects is that it’s just something you do for data governance.
The AI Forecast: Data and AI in the Cloud Era , sponsored by Cloudera, aims to take an objective look at the impact of AI on business, industry, and the world at large. AI is only as successful as the data behind it. LLM precision is good, not great, right now Paul: I wanted to chat about this notion of precision data with you.
To improve the way they model and manage risk, institutions must modernize their data management and data governance practices. Implementing a modern dataarchitecture makes it possible for financial institutions to break down legacy data silos, simplifying data management, governance, and integration — and driving down costs.
Aptly named, metadata management is the process in which BI and Analytics teams manage metadata, which is the data that describes other data. In other words, data is the context and metadata is the content. Without metadata, BI teams are unable to understand the data’s full story.
Modern dataarchitectures. To eliminate or integrate these silos, the public sector needs to adopt robust data management solutions that support modern dataarchitectures (MDAs). Deploying modern dataarchitectures. Lack of sharing hinders the elimination of fraud, waste, and abuse.
Open data is the future. And for that future to be a reality, data teams must shift their attention to metadata, the new turf war for data. The need for unified metadata While open and distributed architectures offer many benefits, they come with their own set of challenges. A few solutions manage both.
This blog post is co-written with Hardeep Randhawa and Abhay Kumar from HPE. This post describes how HPE Aruba automated their Supply Chain management pipeline, and re-architected and deployed their data solution by adopting a modern dataarchitecture on AWS. To achieve this, Aruba used Amazon S3 Event Notifications.
Reading Time: 3 minutes While cleaning up our archive recently, I found an old article published in 1976 about data dictionary/directory systems (DD/DS). Nowadays, we no longer use the term DD/DS, but “data catalog” or simply “metadata system”. It was written by L.
Each of these trends claim to be complete models for their dataarchitectures to solve the “everything everywhere all at once” problem. Data teams are confused as to whether they should get on the bandwagon of just one of these trends or pick a combination. First, we describe how data mesh and data fabric could be related.
That’s because it’s the best way to visualize metadata , and metadata is now the heart of enterprise data management and data governance/ intelligence efforts. So here’s why data modeling is so critical to data governance. erwin Data Modeler: Where the Magic Happens.
The main goal of creating an enterprise data fabric is not new. It is the ability to deliver the right data at the right time, in the right shape, and to the right data consumer, irrespective of how and where it is stored. Data fabric is the common “net” that stitches integrated data from multiple data […].
Several factors determine the quality of your enterprise data like accuracy, completeness, consistency, to name a few. But there’s another factor of data quality that doesn’t get the recognition it deserves: your dataarchitecture. How the right dataarchitecture improves data quality.
Over the past decade, the successful deployment of large scale data platforms at our customers has acted as a big data flywheel driving demand to bring in even more data, apply more sophisticated analytics, and on-board many new data practitioners from business analysts to data scientists.
Over the years, data lakes on Amazon Simple Storage Service (Amazon S3) have become the default repository for enterprise data and are a common choice for a large set of users who query data for a variety of analytics and machine leaning use cases. Analytics use cases on data lakes are always evolving.
How do you approach data lineage? We all know that data lineage is a complex and challenging topic. In this blog, I am drilling into something I’ve been thinking about and studying for a long time: fundamental approaches to lineage creation and maintenance. What Is Data Lineage Creation & Maintenance?
This is a guest blog post co-written with Sumesh M R from Cargotec and Tero Karttunen from Knowit Finland. They chose AWS Glue as their preferred data integration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed.
Metadata is an important part of data governance, and as a result, most nascent data governance programs are rife with project plans for assessing and documenting metadata. But in many scenarios, it seems that the underlying driver of metadata collection projects is that it’s just something you do for data governance.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
With this launch, you can query data regardless of where it is stored with support for a wide range of use cases, including analytics, ad-hoc querying, data science, machine learning, and generative AI. We’ve simplified dataarchitectures, saving you time and costs on unnecessary data movement, data duplication, and custom solutions.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. Components of a Data Mesh. How CDF enables successful Data Mesh Architectures.
Modern, strategic data governance , which involves both IT and the business, enables organizations to plan and document how they will discover and understand their data within context, track its physical existence and lineage, and maximize its security, quality and value. Five Steps to GDPR/CCPA Compliance. How erwin Can Help.
Companies can now capitalize on the value in all their data, by delivering a hybrid data platform for modern dataarchitectures with data anywhere. Cloudera Data Platform (CDP) is designed to address the critical requirements for modern dataarchitectures today and tomorrow.
But increasingly at Cloudera, our clients are looking for a hybrid cloud architecture in order to manage compliance requirements. This is not just to implement specific governance rules — such as tagging, metadata management, access controls, or anonymization — but to prepare for the potential for rules to change in the future. .
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient data analytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. This concept makes Iceberg extremely versatile. SparkActions.get().expireSnapshots(iceTable).expireOlderThan(TimeUnit.DAYS.toMillis(7)).execute()
Today, the way businesses use data is much more fluid; data literate employees use data across hundreds of apps, analyze data for better decision-making, and access data from numerous locations. It uses knowledge graphs, semantics and AI/ML technology to discover patterns in various types of metadata.
As a foundational component of enterprise data management, DG would reside in such a group. Enterprise Data Management Methodology : DG is foundational to enterprise data management. metadata management, enterprise dataarchitecture, data quality management), DG will be a struggle.
First, you must understand the existing challenges of the data team, including the dataarchitecture and end-to-end toolchain. Monitoring Job Metadata. Monitoring and tracking is an essential feature that many data teams are looking to add to their pipelines. Second, you must establish a definition of “done.”
In fact, we recently announced the integration with our cloud ecosystem bringing the benefits of Iceberg to enterprises as they make their journey to the public cloud, and as they adopt more converged architectures like the Lakehouse. 1: Multi-function analytics . 3: Open Performance.
The role of data modeling (DM) has expanded to support enterprise data management, including data governance and intelligence efforts. Metadata management is the key to managing and governing your data and drawing intelligence from it. Types of Data Models: Conceptual, Logical and Physical.
The typical notion is that enterprise architects and data (and metadata) architects are in opposite corners. At Avydium , we believe there’s an important middle ground where different architecture disciplines coexist, including enterprise, solution, application, data, metadata and technical architectures.
Customers want to know how their data is being accessed, when it is being accessed, and who is accessing it. With exponential growth in data volume, centralized monitoring becomes challenging. It is also crucial to audit granular data access for security and compliance needs.
With complex dataarchitectures and systems within so many organizations, tracking data in motion and data at rest is daunting to say the least. Harvesting the data through automation seamlessly removes ambiguity and speeds up the processing time-to-market capabilities.
The journey starts with having a multimodal data governance framework that is underpinned by a robust dataarchitecture like data fabric. To understand how a data fabric helps maintain compliance to privacy regulations, it’s helpful to look at some essential elements of that single pane of glass.
Data fabric and data mesh are emerging data management concepts that are meant to address the organizational change and complexities of understanding, governing and working with enterprise data in a hybrid multicloud ecosystem. The good news is that both dataarchitecture concepts are complimentary.
A well-designed dataarchitecture should support business intelligence and analysis, automation, and AI—all of which can help organizations to quickly seize market opportunities, build customer value, drive major efficiencies, and respond to risks such as supply chain disruptions.
With Cloudera’s vision of hybrid data , enterprises adopting an open data lakehouse can easily get application interoperability and portability to and from on premises environments and any public cloud without worrying about data scaling. Why integrate Apache Iceberg with Cloudera Data Platform?
It is a replicated, highly-available service that is responsible for managing the metadata for all objects stored in Ozone. As Ozone scales to exabytes of data, it is important to ensure that Ozone Manager can perform at scale. The hardware specifications are included at the end of this blog.
Invest in maturing and improving your enterprise business metrics and metadata repositories, a multitiered dataarchitecture, continuously improving data quality, and managing data acquisitions. enhanced customer experiences by accelerating the use of data across the organization.
The current method is largely manual, relying on emails and general communication, which not only increases overhead but also varies from one use case to another in terms of data governance. Data domain producers publish data assets using datasource run to Amazon DataZone in the Central Governance account.
Iceberg stores the metadata pointer for all the metadata files. When a SELECT query is reading an Iceberg table, the query engine first goes to the Iceberg catalog, then retrieves the entry of the location of the latest metadata file, as shown in the following diagram. In this post, we use Athena to convert the data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content