This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Noting that companies pursued bold experiments in 2024 driven by generative AI and other emerging technologies, the research and advisory firm predicts a pivot to realizing value. Forrester said most technology executives expect their IT budgets to increase in 2025. Others won’t — and will come up against the limits of quick fixes.”
In doing so, a unified view across all their data is required—one that breaks down data silos and simplifies data usage for teams, without sacrificing the depth and breadth of capabilities that make AWS tools unbelievably valuable. And move with confidence and trust with built-in governance to address enterprise security needs.
However, you can use the same file name as long as it’s from different auto-copy jobs: job_customerA_sales – s3://redshift-blogs/sales/customerA/2022-10-15-sales.csv job_customerB_sales – s3://redshift-blogs/sales/customerB/2022-10-15-sales.csv Do not update file contents. Do not overwrite existing files.
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern dataarchitectures.
To populate source data: Run the following script on Query Editor to create the sample database DEMO_DB and tables inside DEMO_DB. To populate source data: Run the following script on Query Editor to create the sample database DEMO_DB and tables inside DEMO_DB.
This post explores how you can use AWS Glue Data Quality to maintain data quality of S3 Tables and Apache Iceberg tables on general purpose S3 buckets. We’ll discuss strategies for verifying the quality of published data and how these integrated technologies can be used to implement effective data quality workflows.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
Reading Time: 3 minutes Data is often hailed as the most valuable assetbut for many organizations, its still locked behind technical barriers and organizational bottlenecks. Modern dataarchitectures like data lakehouses and cloud-native ecosystems were supposed to solve this, promising centralized access and scalability.
From streaming trade data and fraud signals to real-time KYC updates and credit scoring models, the tempo of financial operations has shifted to milliseconds.
Today’s data teams are more distributed than ever, working with an increasingly complex modern data stack that spans cloud warehouses, transformation tools, and API-first architectures. Yet despite these technological advances, one challenge persists: overcoming the gap between data modeling and implementation.
Many enterprises have heterogeneous data platforms and technology stacks across different business units or data domains. For decades, they have been struggling with scale, speed, and correctness required to derive timely, meaningful, and actionable insights from vast and diverse big data environments.
Reading Time: 2 minutes The data lakehouse has emerged as a powerful and popular dataarchitecture, combining the scale of data lakes with the management features of data warehouses. It promises a unified platform for storing and analyzing structured and unstructured data, particularly for.
It aims to rebalance power in the digital ecosystem by promoting fair, transparent, The post Unlocking Data Democracy: Denodo and the European Data Act appeared first on Data Management Blog - Data Integration and Modern Data Management Articles, Analysis and Information.
The post Building a Truly Smart Nation Why Data Interoperability Is the Next Digital Breakthrough appeared first on Data Management Blog - Data Integration and Modern Data Management Articles, Analysis and Information. But the real challenge often lies.
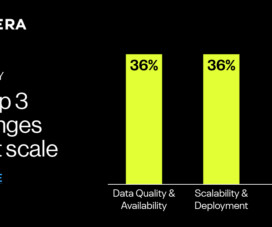
In business today, the ability to embraceflexible technology adoptionhas become a critical factor for success. Yetonly 48%of digitization initiatives meet or exceed their intended outcomes. Clearly, theres a very big gap between expectations and reality for transformation projects.
Citizens expect efficient services, The post Empowering the Public Sector with Data: A New Model for a Modern Age appeared first on Data Management Blog - Data Integration and Modern Data Management Articles, Analysis and Information. In this dynamic environment, time is everything.
In other words, its ability to navigate complex business environments, interface with multiple technology systems, reason through business rules, and deliver value aligned with business goals. This evolution isnt just about creating a single general system that does everything, Savarese wrote in a blog post today. Risk governance.
Reading Time: 3 minutes Gartner Hype Cycle provides a graphic representation of the maturity and adoption of technologies and applications, and how they are potentially relevant to solving real business problems and exploiting new opportunities. Gartner Hype Cycle methodology provides a view of how.
Reading Time: 3 minutes A few months ago, I spoke with the head of dataarchitecture at a leading European bank. Theyd just completed a multi-year investment in a modern data lakehouse platform a combination of Databricks on Azure, paired with legacy systems.
Reading Time: 2 minutes An edited version of this blog is also posted onInsightJam. The recent announcement that Salesforce is acquiring Informatica has sent waves throughout the data management community. This follows ServiceNows acquisition of data.world, a cloud-native data catalog platform, raising questions in.
To ensure your dataarchitecture remains secure and future-ready, your best bet is to proactively replace SAP PowerDesigner with a powerful alternative now. Incompatibility with modern technologies: PowerDesigner was built for an earlier era of data management. Dont saddle your organization with outdated technology.
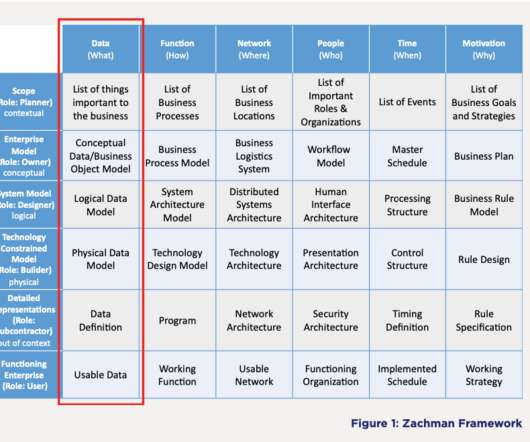
Although there is some crossover, there are stark differences between dataarchitecture and enterprise architecture (EA). That’s because dataarchitecture is actually an offshoot of enterprise architecture. The Value of DataArchitecture. DataArchitecture and Data Modeling.
However, most of this data is not new or original, much of it is copied data. For example, data about a. The post Data Minimization as Design Guideline for New DataArchitectures appeared first on Data Virtualization blog.
The need for data fabric. As Cloudera CMO David Moxey outlined in his blog , we live in a hybrid data world. Data is growing and continues to accelerate its growth. Cloudera data fabric and analyst acclaim. Data fabrics are one of the more mature modern dataarchitectures. Next steps.
At a time when AI is exploding in popularity and finding its way into nearly every facet of business operations, data has arguably never been more valuable. More recently, that value has been made clear by the emergence of AI-powered technologies like generative AI (GenAI) and the use of Large Language Models (LLMs).
It’s not enough for businesses to implement and maintain a dataarchitecture. The unpredictability of market shifts and the evolving use of new technologies means businesses need more data they can trust than ever to stay agile and make the right decisions.
Data has continued to grow both in scale and in importance through this period, and today telecommunications companies are increasingly seeing dataarchitecture as an independent organizational challenge, not merely an item on an IT checklist. Why telco should consider modern dataarchitecture. The challenges.
Technology alone would not have prevented the banking crisis, but the fact remains that financial institutions still aren’t leveraging technology as creatively, intelligently, and cost-effectively as they should be. Apply emerging technology to intraday liquidity management.
Enterprise IT leaders across industries are tasked with preparing their organizations for the technologies of the future – which is no simple task. Challenges in Implementing AI Implementing AI does not come without challenges for many organizations, primarily due to outdated or inadequate data infrastructures. EMEA and APAC regions.
It would be incredibly inefficient to build a data mesh without automation. DataOps focuses on automating data analytics workflows to enable rapid innovation with low error rates. It also engenders collaboration across complex sets of people, technology, and environments. Conclusion.
This blog post is co-written with Hardeep Randhawa and Abhay Kumar from HPE. This post describes how HPE Aruba automated their Supply Chain management pipeline, and re-architected and deployed their data solution by adopting a modern dataarchitecture on AWS.
Modern dataarchitectures. To eliminate or integrate these silos, the public sector needs to adopt robust data management solutions that support modern dataarchitectures (MDAs). Deploying modern dataarchitectures. Lack of sharing hinders the elimination of fraud, waste, and abuse.
While we have seen a change in the calendar year, one initiative that continues to be a top priority for businesses is storing, managing, accessing and optimizing corporate data. With the new year events well behind us, we’re steadily focused on moving forward in 2021. Given that, let’s consider what I believe will be some […].
Full disclosure: some images have been edited to remove ads or to shorten the scrolling in this blog post. DBTA’s 100 Companies That Matter Most in Data. DataKitchen and its DataKitchen DataOps platform have been attracting attention in the emerging realm of data operations or “DataOps.”.
DataOps adoption continues to expand as a perfect storm of social, economic, and technological factors drive enterprises to invest in process-driven innovation. As a result, enterprises will examine their end-to-end data operations and analytics creation workflows. Data Gets Meshier.
Each of these trends claim to be complete models for their dataarchitectures to solve the “everything everywhere all at once” problem. Data teams are confused as to whether they should get on the bandwagon of just one of these trends or pick a combination. First, we describe how data mesh and data fabric could be related.
Most importantly, it helps organizations control costs and reduce risks, enforcing consistent security and governance across all enterprise data assets.”. This does not mean ‘one of each’ – a public cloud data strategy and an on-prem data strategy. The proof is in the pudding.
The following resources will help you understand DataOps principles and how to get started: Blog: For Data Team Success, What You Do is Less Important Than How You Do It. Blog: What is DataOps ? White Paper: DataOps is Not Just DevOps for Data . Blog: 4 Easy Ways to Start DataOps Today.
Learn more about how you can benefit from a well-supported data management platform and ecosystem of products, services and support by visiting the IBM and Cloudera partnership page. The post IBM Technology Chooses Cloudera as its Preferred Partner for Addressing Real Time Data Movement Using Kafka appeared first on Cloudera Blog.
Several factors determine the quality of your enterprise data like accuracy, completeness, consistency, to name a few. But there’s another factor of data quality that doesn’t get the recognition it deserves: your dataarchitecture. How the right dataarchitecture improves data quality.
Practically overnight, organizations have been forced to adapt by modernizing their dataarchitecture to support new types of analysis and new ways to connect to data. The post Modernize Your DataArchitecture with Data Virtualization appeared first on Data Virtualization blog.
Practically overnight, organizations have been forced to adapt by modernizing their dataarchitectures to support new types of analysis and new ways to connect to data. The post Modernize Your DataArchitecture with Data Virtualization appeared first on Data Virtualization blog.
In this article, we argue that a knowledge graph built with semantic technology (the type of Ontotext’s GraphDB) improves the way enterprises operate in an interconnected world. Okay, You Got a Knowledge Graph Built with Semantic Technology… And Now What? Not surprisingly, everyone seems to have or want to have a knowledge graph.
Reading Time: 3 minutes At the heart of every organization lies a dataarchitecture, determining how data is accessed, organized, and used. For this reason, organizations must periodically revisit their dataarchitectures, to ensure that they are aligned with current business goals.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content