This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon DataZone is a datamanagement service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and from third-party sources.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or data lake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
Amazon Redshift supports querying data stored in Apache Iceberg tables managed by Amazon S3 Tables , which we previously covered as part of getting started blog post. Well also review an example with simultaneously using data that resides both in Amazon Redshift and Amazon S3 Tables, enabling a unified analytics experience.
Below is our third post (3 of 5) on combining data mesh with DataOps to foster greater innovation while addressing the challenges of a decentralized architecture. We’ve talked about data mesh in organizational terms (see our first post, “ What is a Data Mesh? ”) and how team structure supports agility. Source: Thoughtworks.
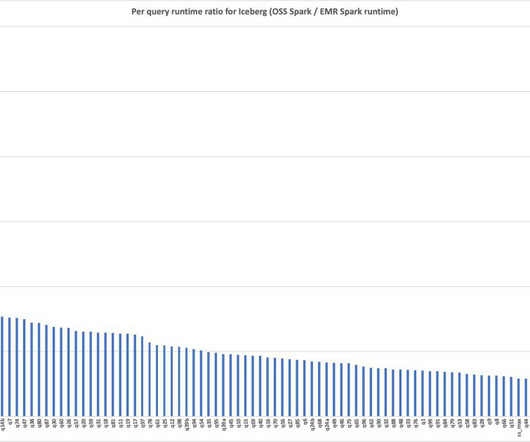
4xlarge instances, providing observable gains for data processing tasks. To minimize the influence of external catalogs like AWS Glue and Hive, we used the Hadoop catalog for the Iceberg tables. This uses the underlying file system, specifically Amazon S3, as the catalog. with Iceberg 1.6.1 and Iceberg 1.5.2.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed data lake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
DataOps has become an essential methodology in pharmaceutical enterprise data organizations, especially for commercial operations. Companies that implement it well derive significant competitive advantage from their superior ability to manage and create value from data.
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and data architecture and views the data organization from the perspective of its processes and workflows.
When an organization’s data governance and metadata management programs work in harmony, then everything is easier. Data governance is a complex but critical practice. There’s always more data to handle, much of it unstructured; more data sources, like IoT, more points of integration, and more regulatory compliance requirements.
Remote working has revealed the inconsistency and fragility of workflow processes in many data organizations. The data teams share a common objective; to create analytics for the (internal or external) customer. Data Science Workflow – Kubeflow, Python, R. Data Engineering Workflow – Airflow, ETL.
Data intelligence has a critical role to play in the supercomputing battle against Covid-19. While leveraging supercomputing power is a tremendous asset in our fight to combat this global pandemic, in order to deliver life-saving insights, you really have to understand what data you have and where it came from.
Data governance (DG) as a an “emergency service” may be one critical lesson learned coming out of the COVID-19 crisis. Where crisis leads to vulnerability, data governance as an emergency service enables organization management to direct or redirect efforts to ensure activities continue and risks are mitigated.
I’m excited to share the results of our new study with Dataversity that examines how data governance attitudes and practices continue to evolve. Defining Data Governance: What Is Data Governance? . 1 reason to implement data governance. Constructing a Digital Transformation Strategy: How Data Drives Digital.
AWS Data Pipeline helps customers automate the movement and transformation of data. With Data Pipeline, customers can define data-driven workflows, so that tasks can be dependent on the successful completion of previous tasks. Some customers want a deeper level of control and specificity than possible using Data Pipeline.
The release of Cloudera Data Platform (CDP) Private Cloud Base edition provides customers with a next generation hybrid cloud architecture. Traditional data clusters for workloads not ready for cloud. Introduction and Rationale. Private Cloud Base Overview. Further information and documentation [link] . Summary of major changes.
This blog post is co-written with Raj Samineni from ATPCO. In today’s data-driven world, companies across industries recognize the immense value of data in making decisions, driving innovation, and building new products to serve their customers.
Aptly named, metadata management is the process in which BI and Analytics teams manage metadata, which is the data that describes other data. In other words, data is the context and metadata is the content. Without metadata, BI teams are unable to understand the data’s full story. Donna Burbank.
This week I was talking to a data practitioner at a global systems integrator. The practitioner asked me to add something to a presentation for his organization: the value of data governance for things other than data compliance and data security. Now to be honest, I immediately jumped onto data quality.
In the current industry landscape, data lakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. However, efficiently managing and synchronizing data within these lakes presents a significant challenge.
Untapped data, if mined, represents tremendous potential for your organization. While there has been a lot of talk about big data over the years, the real hero in unlocking the value of enterprise data is metadata , or the data about the data. They don’t know exactly what data they have or even where some of it is.
Capital Fund Management ( CFM ) is an alternative investment management company based in Paris with staff in New York City and London. CFM assets under management are now $13 billion. Using social network data has also often been cited as a potential source of data to improve short-term investment decisions.
Data modeling supports collaboration among business stakeholders – with different job roles and skills – to coordinate with business objectives. Data resides everywhere in a business , on-premise and in private or public clouds. A single source of data truth helps companies begin to leverage data as a strategic asset.
And yeah, the real-world relationships among the entities represented in the data had to be fudged a bit to fit in the counterintuitive model of tabular data, but, in trade, you get reliability and speed. Ironically, relational databases only imply relationships between data points by whatever row or column they exist in.
Many organizations operate data lakes spanning multiple cloud data stores. In these cases, you may want an integrated query layer to seamlessly run analytical queries across these diverse cloud stores and streamline your data analytics processes. To achieve this, Oktank envisions a unified data query layer using Athena.
It’s time to consider data-driven enterprise architecture. The traditional approach to enterprise architecture – the analysis, design, planning and implementation of IT capabilities for the successful execution of enterprise strategy – seems to be missing something … data. Data-Driven Enterprise Architecture and Cloud Migration.
4xlarge instances, providing observable gains for data processing tasks. In this post, we explore the performance benefits of using the Amazon EMR runtime for Apache Spark and Apache Iceberg compared to running the same workloads with open source Spark 3.5.1 on Iceberg tables. Additionally, the cost efficiency improves by 2.2 workloads 4.5
Datacatalogs have quickly become a core component of modern datamanagement. Organizations with successful datacatalog implementations see remarkable changes in the speed and quality of data analysis, and in the engagement and enthusiasm of people who need to perform data analysis.
Data agility, the ability to store and access your data from wherever makes the most sense, has become a priority for enterprises in an increasingly distributed and complex environment. That’s where the data fabric comes in. Data fabric in action: Retail supply chain example. enterprises to minimize their time to value.
In this blog post, we will highlight how ZS Associates used multiple AWS services to build a highly scalable, highly performant, clinical document search platform. ZS is a management consulting and technology firm focused on transforming global healthcare.
We are going to talk about auditing, different security levels, security features of DataCatalog, and Client Considerations. Access audits are mastered centrally in Apache Ranger which provides comprehensive non-repudiable audit log for every access event to every resource with rich access event metadata such as: IP.
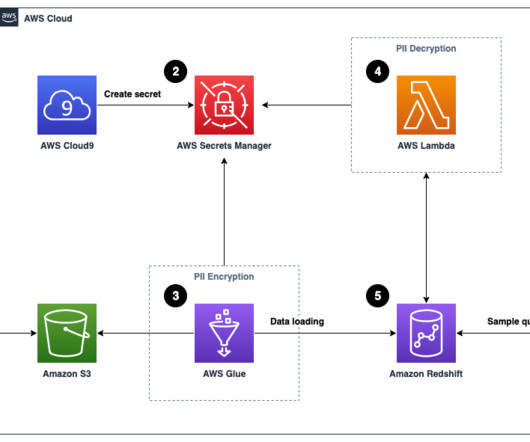
Amazon Redshift is a massively parallel processing (MPP), fully managed petabyte-scale data warehouse that makes it simple and cost-effective to analyze all your data using existing business intelligence tools. A sample 256-bit data encryption key is generated and securely stored using AWS Secrets Manager.
According to analysts, data governance programs have not shown a high success rate. According to CIOs , historical data governance programs were invasive and suffered from one of two defects: They were either forced on the rank and file — who grew to dislike IT as a result. The Risks of Early Data Governance Programs.
MasterDataManagement (MDM) and datacatalog growth are accelerating because organizations must integrate more systems, comply with privacy regulations, and address data quality concerns. What Is MasterDataManagement (MDM)? DataCatalog and MasterDataManagement.
Thousands of customers rely on Amazon Redshift to build data warehouses to accelerate time to insights with fast, simple, and secure analytics at scale and analyze data from terabytes to petabytes by running complex analytical queries. The star schema is a popular data model for building data marts.
Businesses everywhere have engaged in modernization projects with the goal of making their data and application infrastructure more nimble and dynamic. The newly introduced Environments feature allows you to export only the generic, reusable parts of code and resources, while managing environment-specific configuration separately.
Data is the new oil and organizations of all stripes are tapping this resource to fuel growth. However, data quality and consistency are one of the top barriers faced by organizations in their quest to become more data-driven. Unlock quality data with IBM. and its leading data observability offerings.
Included in the post are recommendations for measurement and data analysis. While I'm using the term Store here, it encompasses sales (or leads or catalog requests) driven to a retail store or company call center, people driven to donate blood via online campaigns, or essentially any offline outcome driven by the online channel.
This is a guest blog post co-written with Zack Rossman from Alcion. Alcion, a security-first, AI-driven backup-as-a-service (BaaS) platform, helps Microsoft 365 administrators quickly and intuitively protect data from cyber threats and accidental data loss. OpenSearch is an Apache-2.0-licensed, OpenSearch is an Apache-2.0-licensed,
Modern-day enterprises face a similar situation regarding data assets. On one side there is a need for data. Businesses ask: “Do we have this kind of data in the enterprise?” “How do we get that data?” “Can Can I trust that data?” This discussion is more relevant with the advent of data fabric.
And now, arguably the greatest rivalry the world (well, at least the data community) has ever witnessed: Data Fabric vs Data Mesh! Data fabric and data mesh are both having a moment. Gartner calls data fabric the Future of DataManagement 1. Gartner on Data Fabric. Tyson vs Holyfield.
Our recent blog discussed the four paths to get from legacy platforms to CDP Private Cloud Base. In this blog and accompanying video, we will deep dive into the mechanics of running an in-place upgrade from CDH5 or CDH6 to CDP Private Cloud Base. Zookeeper data. HDFS Master Node data directories. Hue dependencies.
Datacatalogs are here to stay. This week, two independent analyst reports validated what we’ve known for years – datacatalogs are critical for self-service analytics.[1]. The Forrester Wave : Machine Learning DataCatalogs, Q2 2018. This is Forrester’s inaugural Wave on datacatalogs.
Nourish yourself with the "info snacks" the tool's engineers and product managers cooked up. Ravaging data. Leverage Custom Alerts – Let Data Kick Your Butt Into Action. #3. In-Page Analytics – Re-imagine Traveling Through Data. #5. Exploit every possible button. Produce built-in visualization magic.
Data fabric is now on the minds of most datamanagement leaders. In our previous blog, Data Mesh vs. Data Fabric: A Love Story , we defined data fabric and outlined its uses and motivations. The datacatalog is a foundational layer of the data fabric.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content