This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this article you will read why and how SPARQLqueries make for a better search and are of immense help when it comes to accessing all the independently designed and maintained datasets across an organization (and outside it) in an integrated way. Data, Databases and Deeds: A SPARQLQuery to the Rescue.
quintillion bytes of data created each day, the bar for enterprise knowledge and information systems, and especially for their search functions and capabilities, is raised high. One such way towards better search (and better informed actions) is the SPARQLquery. Think of all the databases an organization is operating with.
In our previous blog posts of the series, we talked about how to ingest data from different sources into GraphDB , validate it and infer new knowledge from the extant facts as well as how to adapt and scale our basic solution. And the LAZY system from our previous blog posts is at the threshold of that important step.
Relational databases (RDBS) have been the workhorse of ICT for decades. Being able to sit down and define a complete schema, a blueprint of the database, gave everyone assurity and consistency. Graph Databases vs Relational Databases. Sure, you have to ignore the edge cases and hope that they stay edge cases.
We are going to go down the rabbit hole of advanced SPARQL. Suppose you have a database of movies. In that database, you also have data on the actors. So, you may think of a query such as: “Return the four top-grossing movies, and then return the two highest actors for each movie.”. appeared first on Ontotext.
Data in GraphDB is stored in repositories. You can think about them as you would think about separate databases. You can use SPARQL federation to access data across repositories. We offer a default internal user database, but can also cover users coming from LDAP, OAuth, Kerberos, OpenID. How about write access?
ONTOTEXT ANSWER: The answer to this question loops back to one of our previous posts – GraphDB is a forward chaining database. This means that inferred statements are changed – inserted or removed – during data updates. No data is ingested for these repositories. At no point do they store the triples.
Stop wasting time building data access code manually, let the Ontotext Platform auto-generate a fast, flexible, and scalable GraphQL APIs over your RDF knowledge graph. Are you having difficulty joining your knowledge graph APIs with other data sources? This leads to lots of small data fetches to/from GraphDB over the network.
For these reasons, publishing the data related to elections is obligatory for all EU member states under Directive 2003/98/EC on the re-use of public sector information and the Bulgarian Central Elections Committee (CEC) has released a complete export of every election database since 2011. The complexities of election data.
So, we started this series by introducing knowledge graphs & their application in data management and how to reason with big knowledge graphs & use graph analytics. Here, we want to talk about our flagship product GraphDB – an enterprise-ready RDF database optimized for the development and operations of knowledge graphs.
You step onto the market, and if you don’t keep your data, there’s no knowing where you might be swept off to. [1]. Picture this – you start with the perfect use case for your data analytics product. Nowadays, data analytics doesn’t exist on its own. But would the surveyors write SPARQL? But with robots.
In our previous blog post of the series, we covered how to ingest data from different sources into GraphDB , validate it and infer new knowledge from the extant facts. Today we’ll deal with the big issue of scaling, tackling it on two sides: what happens when you have more and faster sources of data? A bespoke program.
As you might guess from its name, GraphDB stores data in a graph data structure, which is much more flexible than the rigid table structures used by relational database managers. Relational databases have been around for a long time, though, and vast amounts of data are stored in them.
In the previous post, we talked about data virtualization and how Ontotext’s RDF database for knowledge graphs GraphDB provides the tools for the full journey from graphs to relational tables and back. On the other hand, LPGs lack many features that are an absolute must for enterprise data management, e.g., standard schema language.
Natural Language Querying (NLQ) refers to the process of querying a database or an information system using natural language, such as English, instead of formal query languages such as Structured Query Language (SQL). NLQ allows users to interact with databases or systems in a more intuitive and user-friendly way.
But it has enriched us in terms of identifying key needs for those looking to build a simple prototype in order to demonstrate the power of semantic technology, linked data and knowledge graphs. Some of that journey has been recorded in a previous blog post. This training will not make a SPARQL master out of anyone.
Rebel GraphQL developers strike from a hidden base and have won their first victory against the evil SPARQL empire. During the battle, however, it is discovered that Ontotext has secret plans to allow both GraphQL and SPARQL to co-exist, and flourish together, building the ultimate weapon, the ONTOTEXT PLATFORM ! Species subClass).
In 2019 we have published many engaging blog posts on various topics and now, at the end of this exciting year, we have analyzed your interest in them and would like to present the top 5 most fascinating blog posts for 2019. Telling Stories with an RDF Database. Artificial Intelligence and the Knowledge Graph.
In this blog post, we will highlight how ZS Associates used multiple AWS services to build a highly scalable, highly performant, clinical document search platform. We use leading-edge analytics, data, and science to help clients make intelligent decisions. Overview of solution The solution was designed in layers.
Nose-first data: the project Odeuropa preserving the smells heritage of Europe No doubt our olfactory perception contributes and enriches our understanding and experiencing of the world. The question is how we can use data and cutting-edge technology to learn about the smell experiences and the perception of different smells in the past.
In the first part of this series of technological posts, we talked about what SHACL is and how you can set up validation for your data. Tacking the data quality issue — bit by bit or incrementally There are two main approaches to validating your data, which would be dependent on the specific implementation.
The beauty and power of knowledge graphs is their abstraction away from the fiddly implementation details of our data. The data and information is organized in a way human-users understand it regardless of the physical location of the data, the format and other low-level technical details. Firstly, There’s Federation.
It is common nowadays to see environments where various actors have access to the same database and can write their own data. While everyone may subscribe to the same design decisions and agree on an ontology, there may be differences in the data quality. In such situations, data must be validated.
So far we have covered the capabilities and business applications of knowledge graphs as well as some of the major benefits of our RDF database – GraphDB. They focus on business-specific information needs and how to properly source the needed data rather than analyze preexisting application models.
Bulk validation is great when data comes together nicely as one big package. The data only becomes problematic when it’s joined together with the rest of the dragon data. However, to do that, we had to perform bulk validation on the whole database. Then, validation happens on the data within that context only.
Over the years, Ontotext’s leading semantic graph database GraphDB has helped organizations in a variety of industries with their data and knowledge management challenges. Experts in linked data, semantic technology and triplestores are testing GraphDB’s capabilities and performance, and applying it in various technical use cases.
The update is to drop and re-import the same graph data into a single atomic transaction. The simplified SPARQLquery below describes how to delete the old data and insert the new one. The biggest advantage of the approach is that the user can query the database at any given past timestamp.
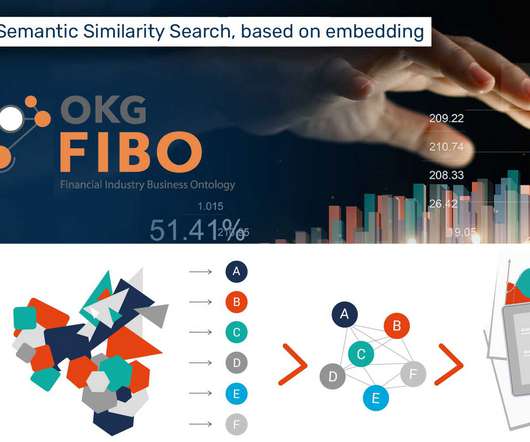
Knowledge of the subject domain is always helpful, but rarely sufficient as there are many choices to be made in representing domain knowledge as data in a graph. The Financial Industry Business Ontology (FIBO) is a conceptual model of the financial industry that has been developed by the Enterprise Data Management Council (EDMC).
ONTOTEXT ANSWER: The dreaded answer to this question is “it depends” JSON data is really pervasive. However, it doesn’t make the cut when it comes to RDF databases. JSON can easily be treated as subject-predicate-object data. JSON supports fewer data types than RDF. JSON has become an industry standard.
ONTOTEXT ANSWER: Query optimization can be quite problematic. Inference vs querying. As a forward-chaining database , GraphDB materializes triples at load time. If you know you have a complex statement pattern that you will be querying often, why not precompute it with inference? Limiting data sizes.
Ontotext GraphDB stands out as a high-performing and scalable graph database, boasting robust RDF and SPARQL capabilities. GraphDB Cluster The GraphDB cluster ensures high availability through data replication among its nodes. The leader can execute both read and write queries. The followers can execute only read queries.
This provides a unified interface for querying all of your data sources in context and allows clients to fetch data from any number of data sources simultaneously, without needing to know which data comes from which source. Our friends from the GraphQL Federation have pledged their support. Trade Federation.
. ‘Don’t Reinvent the Wheel’ Data analysis is an example where time and effort are being spent over and over only for the data and development to be chucked into the ocean after the work is done. This is particularly true for the initial data preparation stage of any analysis work.
Or, there may even be a requirement that your data is compartmentalized so one attack only compromises some of your data. Logical separation – GraphDB (or any graph database, really) has a way to achieve this, using named graphs – also known as contexts. That roughly maps to a table/database concept from SQL.
But it has enriched us in terms of identifying key needs for those looking to build a simple prototype in order to demonstrate the power of semantic technology, linked data and knowledge graphs. Some of that journey has been recorded in a previous blog post. This training will not make a SPARQL master out of anyone.
of Ontotext’s GraphDB has lots of new bells and whistles that will ensure that it remains the market leader for semantic databases. This new version sees the release of essential plug-ins: data virtualization, a sophisticated ranking of semantic search results, new types of indexing and advanced graph analytics. Version 9.0
Ontotext’s GraphDB is an enterprise-ready semantic graph database (also called RDF triplestore as it stores data in RDF triples). It provides the core infrastructure for solutions where modeling agility, data integration, relationship exploration, cross-enterprise data publishing and consumption are critical.
According to an article in Harvard Business Review , cross-industry studies show that, on average, big enterprises actively use less than half of their structured data and sometimes about 1% of their unstructured data. The many data warehouse systems designed in the last 30 years present significant difficulties in that respect.
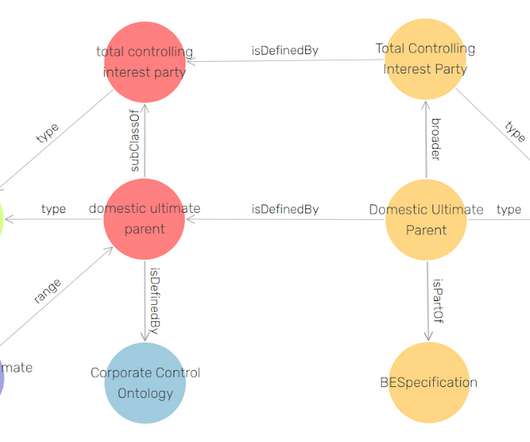
The Financial Industry Business Ontology (FIBO) is a standard that is being developed and published by the Enterprise Data Management Council that attempts to capture business domain knowledge using sophisticated knowledge representation techniques and linked open data technologies. In this way, FIBO can give meaning to any data (e.g.,
This is a really exciting feature as it increases the write scalability of RDF solutions when dealing with document-centric data. It allows us to store some of our data outside of GraphDB, but still query it from GraphDB’s SPARQL editor. Often, the data stored in an enterprise knowledge graph has two shape types.
The generation, transmission, distribution and sale of electrical power generates a lot of data needed across a variety of roles to address reporting requirements, changing regulations, advancing technology, rapid responses to extreme weather events and more. What are knowledge graphs and how can they help?
In this edition of GraphDB In Action, we present to you the work of three bright researchers who have set out to find solutions that allow meaningful analysis and interpretation of data, supported by Ontotext GraphDB. It was used with SPARQL in GraphDB to maintain semantic interoperability with external RDF namespaces.
We looked at the major challenges of electrical grids, the main standards guiding electricity data exchange and how these challenges could be addressed by applying Linked Data principles and knowledge graph (KG) technology to electricity data. Simply put, AI without data is like a human surviving without oxygen.
Ontotext’s GraphDB is an enterprise-ready semantic graph database (also called RDF triplestore because it stores data in RDF triples). It provides the core infrastructure for solutions where modelling agility, data integration, relationship exploration, cross-enterprise data publishing and consumption are critical. .
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content