This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Reading Time: 2 minutes The data lakehouse has emerged as a powerful and popular data architecture, combining the scale of data lakes with the management features of data warehouses. It promises a unified platform for storing and analyzing structured and unstructureddata, particularly for.
One of the main goals of a digital transformation is to empower everyone within an organization to make smarter, data-driven decisions. Before we dig into what your enterprise dataintegration will do for your organization, let’s touch briefly on the challenges that collecting all of an enterprise’s data can entail.
Read the complete blog below for a more detailed description of the vendors and their capabilities. This is not surprising given that DataOps enables enterprise data teams to generate significant business value from their data. QuerySurge – Continuously detect data issues in your delivery pipelines.
There is no disputing the fact that the collection and analysis of massive amounts of unstructureddata has been a huge breakthrough. This is something that you can learn more about in just about any technology blog. We would like to talk about data visualization and its role in the big data movement.
They also face increasing regulatory pressure because of global data regulations , such as the European Union’s General Data Protection Regulation (GDPR) and the new California Consumer Privacy Act (CCPA), that went into effect last week on Jan. Data modeling captures how the business uses data and provides context to the data source.
Now generally available, the M&E data lakehouse comes with industry use-case specific features that the company calls accelerators, including real-time personalization, said Steve Sobel, the company’s global head of communications, in a blog post.
In the era of big data, data lakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructureddata, offering a flexible and scalable environment for data ingestion from multiple sources.
Therefore, the right approach to data modeling is one that allows users to view any data from anywhere – a data governance and management best practice we dub “any-squared” (Any 2 ). The Advantages of NoSQL Data Modeling. SQL or NoSQL?
Organizations don’t know what they have anymore and so can’t fully capitalize on it — the majority of data generated goes unused in decision making. And second, for the data that is used, 80% is semi- or unstructured. Both obstacles can be overcome using modern data architectures, specifically data fabric and data lakehouse.
A data lake is a centralized repository that you can use to store all your structured and unstructureddata at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Choose Next to create your stack.
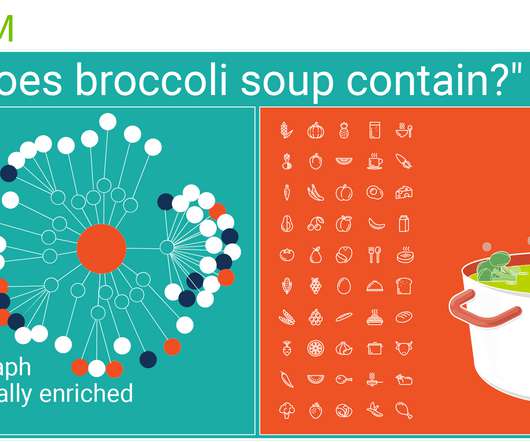
What lies behind building a “nest” from irregularly shaped, ambiguous and dynamic “strings” of human knowledge, in other words of unstructureddata? To do that Edamam, together with Ontotext, worked to develop a knowledge graph with semantically enriched nutrition data.
Improved data accessibility: By providing self-service data access and analytics, modern data architecture empowers business users and data analysts to analyze and visualize data, enabling faster decision-making and response to regulatory requirements.
Challenges in Developing Reliable LLMs Organizations venturing into LLM development encounter several hurdles: Data Location: Critical data often resides in spreadsheets, characterized by a blend of text, logic, and mathematics.
IT should be involved to ensure governance, knowledge transfer, dataintegrity, and the actual implementation. The post Your Effective Roadmap To Implement A Successful Business Intelligence Strategy appeared first on BI Blog | Data Visualization & Analytics Blog | datapine. Because it is that important.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Introduction. To learn more about the CDF platform, please visit [link].
We live in a world of data: there’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways organizations tackle the challenges of this new world to help their companies and their customers thrive. Data modeling: Create relationships between data.
However, some practical data management issues contribute to a growing need for enterprise data governance, including: Increasing data volumes that challenge the traditional enterprise’s ability to store, manage and ultimately find data. Reducing the IT bottleneck that creates barriers to data accessibility.
We’ve seen a demand to design applications that enable data to be portable across cloud environments and give you the ability to derive insights from one or more data sources. With these connectors, you can bring the data from Azure Blob Storage and Azure Data Lake Storage separately to Amazon S3.
We know very well that the FAIR principles are influenced by the Linked Data Principles, which play a significant role at the core of knowledge graphs. In particular, in situations where storing personal data in one place would be problematic, knowledge graphs enable easy linking and querying of data, taking a step in this direction.
IBM, a pioneer in data analytics and AI, offers watsonx.data, among other technologies, that makes possible to seamlessly access and ingest massive sets of structured and unstructureddata. AWS’s secure and scalable environment ensures dataintegrity while providing the computational power needed for advanced analytics.
It ensures compliance with regulatory requirements while shifting non-sensitive data and workloads to the cloud. Its built-in intelligence automates common data management and dataintegration tasks, improves the overall effectiveness of data governance, and permits a holistic view of data across the cloud and on-premises environments.
Ring 3 uses the capabilities of Ring 1 and Ring 2, including the dataintegration capabilities of the platform for terminology standardization and person matching. The introduction of Generative AI offers to take this solution pattern a notch further, particularly with its ability to better handle unstructureddata.
In the current industry landscape, data lakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructureddata. This approach ensures you have the most up-to-date data available for real-time analytics.
Open source frameworks such as Apache Impala, Apache Hive and Apache Spark offer a highly scalable programming model that is capable of processing massive volumes of structured and unstructureddata by means of parallel execution on a large number of commodity computing nodes. .
We’ve seen that there is a demand to design applications that enable data to be portable across cloud environments and give you the ability to derive insights from one or more data sources. With this connector, you can bring the data from Google Cloud Storage to Amazon S3.
Ontotext worked with a global research-based biopharmaceutical company to solve the problem of inefficient search across dispersed and vast sources of unstructureddata. They were facing three different data silos of half a million documents full of clinical study data.
So, KGF 2023 proved to be a breath of fresh air for anyone interested in topics like data mesh and data fabric , knowledge graphs, text analysis , large language model (LLM) integrations, retrieval augmented generation (RAG), chatbots, semantic dataintegration , and ontology building.
We offer two different PowerPacks – Agile DataIntegration and High-Performance Tagging. The Agile DataIntegration PowerPack bundle The other bundle is the Agile DataIntegration PowerPack. It helps enterprises unite different data silos and allows them to manage all digital assets from one place.
In today’s data-driven world, businesses are drowning in a sea of information. Traditional dataintegration methods struggle to bridge these gaps, hampered by high costs, data quality concerns, and inconsistencies. This is the power of Zenia Graph’s services and solution powered by Ontotext GraphDB.
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Data analytics on operational data at near-real time is becoming a common need. a new version of AWS Glue that accelerates dataintegration workloads in AWS.
At the same time, there are more demands for data to be used in real-time and for businesses to have a better understanding of it. In addition, there is a growing trend of automating dataintegration and management processes. All this makes it difficult to navigate the enterprise data landscape and stay ahead of the competition.
Both approaches were typically monolithic and centralized architectures organized around mechanical functions of data ingestion, processing, cleansing, aggregation, and serving. Learn more about the benefits of data fabric and IBM Cloud Pak for Data.
As organizations are utilizing different platforms, the ability to jump from traditional relational databases to NoSQL databases that are ideal for scalability and handling large amounts of unstructureddata is paramount. These enhancements also help reduce redundancy and improve data consistency. can help solve! Register Now!
For efficient drug discovery, linked data is key. The actual process of dataintegration and the subsequent maintenance of knowledge requires a lot of time and effort. With knowledge graphs, automated reasoning becomes even more of a possibility.
It supports a variety of storage engines that can handle raw files, structured data (tables), and unstructureddata. It also supports a number of frameworks that can process data in parallel, in batch or in streams, in a variety of languages. The foundation of this end-to-end AML solution is Cloudera Enterprise.
Achieving this advantage is dependent on their ability to capture, connect, integrate, and convert data into insight for business decisions and processes. This is the goal of a “data-driven” organization. We call this the “ Bad Data Tax ”.
Data within a data fabric is defined using metadata and may be stored in a data lake, a low-cost storage environment that houses large stores of structured, semi-structured and unstructureddata for business analytics, machine learning and other broad applications. Security Data security is a high priority.
Because Alex can use a data catalog to search all data assets across the company, she has access to the most relevant and up-to-date information. She can search structured or unstructureddata, visualizations and dashboards, machine learning models, and database connections. Everybody wins with a data catalog.
To overcome these issues, Orca decided to build a data lake. A data lake is a centralized data repository that enables organizations to store and manage large volumes of structured and unstructureddata, eliminating data silos and facilitating advanced analytics and ML on the entire data.
From a technological perspective, RED combines a sophisticated knowledge graph with large language models (LLM) for improved natural language processing (NLP), dataintegration, search and information discovery, built on top of the metaphactory platform. Let’s have a quick look under the bonnet.
This example combines three types of unrelated data: Legal entity data: Two companies with completely unrelated business lines (coffee and waste management) merged together; Unstructureddata: Fraudulent promotion campaigns took place through press releases and a fake stock-picking robot.
Let’s discuss what data classification is, the processes for classifying data, data types, and the steps to follow for data classification: What is Data Classification? Either completed manually or using automation, the data classification process is based on the data’s context, content, and user discretion.
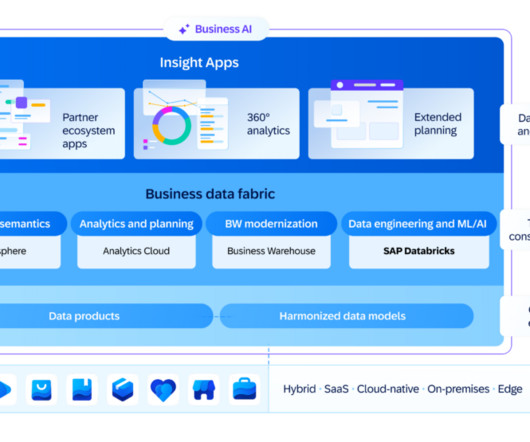
SAP has recently started to emphasize the business aspect in its messaging (see related BARC blog post in German ), a strategy it is continuing with BDC. Instead, the Databricks object store provides an industry-standard and more cost-efficient solution for storing data.
Let’s explore how BI tools can help you get the most out of Big Data—and ultimately drive your business forward. What Exactly is Big Data? Simply put, it’s the large volume of structured and unstructureddata that your business generates every day. million terabytes of data are created each day, according to Statista.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content