This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around datalakes. We talked about enterprise data warehouses in the past, so let’s contrast them with datalakes. Both data warehouses and datalakes are used when storing big data.
A Drug Launch Case Study in the Amazing Efficiency of a Data Team Using DataOps How a Small Team Powered the Multi-Billion Dollar Acquisition of a Pharma Startup When launching a groundbreaking pharmaceutical product, the stakes and the rewards couldnt be higher. It is necessary to have more than a datalake and a database.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Choose Next to create your stack.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. and later supports the Apache Iceberg framework for datalakes. AWS Glue 3.0 The following diagram illustrates the solution architecture.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Many organizations operate datalakes spanning multiple cloud data stores. In these cases, you may want an integrated query layer to seamlessly run analytical queries across these diverse cloud stores and streamline your data analytics processes. Upload the data file to the S3 bucket created by the CloudFormation stack.
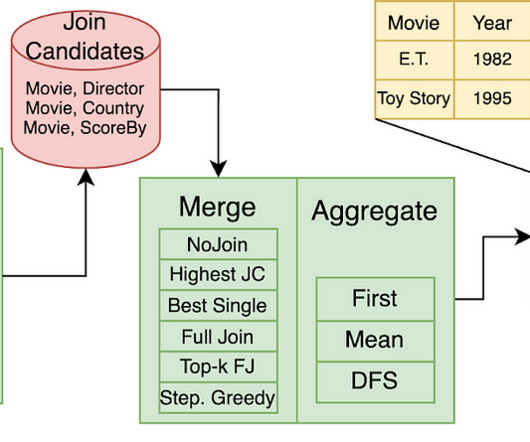
In this series of blog posts, we have been exploring the problem of augmenting a table using information contained in a datalake (a large collection of datasets).
Datalakes have been gaining popularity for storing vast amounts of data from diverse sources in a scalable and cost-effective way. As the number of data consumers grows, datalake administrators often need to implement fine-grained access controls for different user profiles.
Over the years, organizations have invested in creating purpose-built, cloud-based datalakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple datalakes, each built on different technology stacks.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
Amazon Redshift enables you to directly access data stored in Amazon Simple Storage Service (Amazon S3) using SQL queries and join data across your data warehouse and datalake. With Amazon Redshift, you can query the data in your S3 datalake using a central AWS Glue metastore from your Redshift data warehouse.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient data analytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. 5 seconds $0.08 8 seconds $0.07 8 seconds $0.02 107 seconds $0.25
Observability in DataOps refers to the ability to monitor and understand the performance and behavior of data-related systems and processes, and to use that information to improve the quality and speed of data-driven decision making. Query> An AI, Chat GPT wrote this blog post, why should I read it? .
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
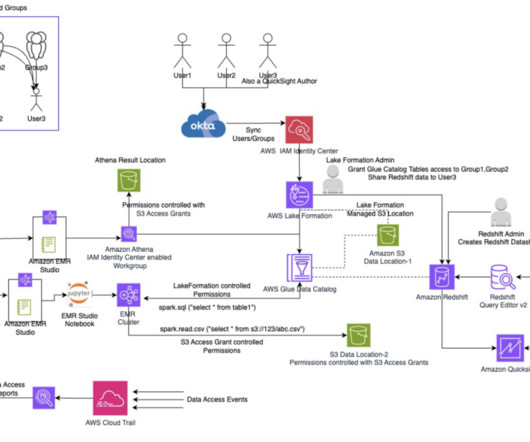
This led to inefficiencies in data governance and access control. AWS Lake Formation is a service that streamlines and centralizes the datalake creation and management process. The Solution: How BMW CDH solved data duplication The CDH is a company-wide datalake built on Amazon Simple Storage Service (Amazon S3).
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
When you build your transactional datalake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 datalake to optimize the production environment. availability. Note the configuration parameters s3.write.tags.write-tag-name write.tags.write-tag-name and s3.delete.tags.delete-tag-name
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Amazon SageMaker Lakehouse , now generally available, unifies all your data across Amazon Simple Storage Service (Amazon S3) datalakes and Amazon Redshift data warehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. The tools to transform your business are here.
Cloud computing has made it much easier to integrate data sets, but that’s only the beginning. Creating a datalake has become much easier, but that’s only ten percent of the job of delivering analytics to users. It often takes months to progress from a datalake to the final delivery of insights.
With this integration, you can now seamlessly query your governed datalake assets in Amazon DataZone using popular business intelligence (BI) and analytics tools, including partner solutions like Tableau. Refer to the detailed blog post on how you can use this to connect through various other tools.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt. The post What is a Data Mesh?
Data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. This leads to having data across many instances of data warehouses and datalakes using a modern data architecture in separate AWS accounts.
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications. For InitialRunFlag , choose Setup.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
This book is not available until January 2022, but considering all the hype around the data mesh, we expect it to be a best seller. In the book, author Zhamak Dehghani reveals that, despite the time, money, and effort poured into them, data warehouses and datalakes fail when applied at the scale and speed of today’s organizations.
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
In today’s world, customers manage vast amounts of data in their Amazon Simple Storage Service (Amazon S3) datalakes, which requires convoluted data pipelines to continuously understand the changes in the data layout and make them available to consuming systems. Review and update the crawler settings.
This blog post is co-written with Ori Nakar from Imperva. Events and many other security data types are stored in Imperva’s Threat Research Multi-Region datalake. Imperva harnesses data to improve their business outcomes. Imperva’s datalake has a few dozen different datasets, in the scale of petabytes.
The rise of distributed data architectures like Data Mesh will combine with DataOps automation to give rise to Hub-Spoke architectures that deftly blend the benefits of centralization and decentralization. For example, a Hub-Spoke architecture could integrate data from a multitude of sources into a datalake.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. For more information, see Changing the default settings for your datalake.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
Instead of having a giant, unwieldy datalake , the data mesh breaks up the data and workflow assets into controllable and composable domains with inherent interdependencies. Domains are built from raw data and/or the output of other domains.
In the ever-evolving landscape of data management, two key concepts have emerged as essential components for organizations seeking to harness the power of their data: data marts and datalakes. Understanding the distinctions […]
Grant access to User1 in Lake Formation Sign in to the Lake Formation console, choose Datalake permissions in the navigation pane, and grant access to the user group on the database oktank_tipblog_temp and table customer. csv("s3://tip-blog-s3-s3ag/input/*").show() csv("s3://tip-blog-s3-s3ag/input/*").write.mode("overwrite").parquet("s3://tip-blog-s3-s3ag/input/")
This is a guest blog post co-authored with Atul Khare and Bhupender Panwar from Salesforce. The Normalized Parquet Logs are stored in an Amazon Simple Storage Service (Amazon S3) datalake and cataloged into Hive Metastore (HMS) on an Amazon Relational Database Service (Amazon RDS) instance based on S3 event notifications.
However, you can use the same file name as long as it’s from different auto-copy jobs: job_customerA_sales – s3://redshift-blogs/sales/customerA/2022-10-15-sales.csv job_customerB_sales – s3://redshift-blogs/sales/customerB/2022-10-15-sales.csv Do not update file contents. Do not overwrite existing files.
DataOps automation replaces the non-value-add work performed by the data team and the outside dollars spent on consultants with an automated framework that executes efficiently and at a high level of quality. Focusing on the processes that operate on data enables the team to automate workflows and build a factory that produces insights.
Open table formats are emerging in the rapidly evolving domain of big data management, fundamentally altering the landscape of data storage and analysis. By providing a standardized framework for data representation, open table formats break down data silos, enhance data quality, and accelerate analytics at scale.
One of the most important innovations in data management is open table formats, specifically Apache Iceberg , which fundamentally transforms the way data teams manage operational metadata in the datalake. Try Cloudera’s open data lakehouse on AWS for 5 days for free here , or try Snowflake for free for 30 days here.
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Run the following Shell script commands in the console to copy the Jupyter Notebooks.
“Data mesh” is a new data analytics paradigm proposed by Zhamak Dehghani, one that is designed to move organizations from monolithic architectures such as the data warehouse and the datalake to more decentralized architectures. As long-time supporters of logical.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content