This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A Drug Launch Case Study in the Amazing Efficiency of a Data Team Using DataOps How a Small Team Powered the Multi-Billion Dollar Acquisition of a Pharma Startup When launching a groundbreaking pharmaceutical product, the stakes and the rewards couldnt be higher. data engineers delivered over 100 lines of code and 1.5
A DataOps Approach to DataQuality The Growing Complexity of DataQualityDataquality issues are widespread, affecting organizations across industries, from manufacturing to healthcare and financial services. 73% of data practitioners do not trust their data (IDC).
Amazon SageMaker Lakehouse , now generally available, unifies all your data across Amazon Simple Storage Service (Amazon S3) datalakes and Amazon Redshift data warehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. Having confidence in your data is key.
Datalakes are centralized repositories that can store all structured and unstructured data at any desired scale. The power of the datalake lies in the fact that it often is a cost-effective way to store data. The power of the datalake lies in the fact that it often is a cost-effective way to store data.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Some customers build custom in-house data parity frameworks to validate data during migration.
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate datalakes and data warehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt. The post What is a Data Mesh?
Observability in DataOps refers to the ability to monitor and understand the performance and behavior of data-related systems and processes, and to use that information to improve the quality and speed of data-driven decision making. Query> An AI, Chat GPT wrote this blog post, why should I read it? .
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Ensuring that data is available, secure, correct, and fit for purpose is neither simple nor cheap. Companies end up paying outside consultants enormous fees while still having to suffer the effects of poor dataquality and lengthy cycle time. . For example, DataOps can be used to automate data integration.
Poor-qualitydata can lead to incorrect insights, bad decisions, and lost opportunities. AWS Glue DataQuality measures and monitors the quality of your dataset. It supports both dataquality at rest and dataquality in AWS Glue extract, transform, and load (ETL) pipelines.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
These formats, exemplified by Apache Iceberg, Apache Hudi, and Delta Lake, addresses persistent challenges in traditional datalake structures by offering an advanced combination of flexibility, performance, and governance capabilities. For more information, refer to What are deletion vectors?
The core issue plaguing many organizations is the presence of out-of-control databases or datalakes characterized by: Unrestrained Data Changes: Numerous users and tools incessantly alter data, leading to a tumultuous environment. Monitor freshness, schema changes, volume, and column health are standard.
You will need to continually return to your business dashboard to make sure that it’s working, the data is accurate and it’s still answering the right questions in the most effective way. Testing will eliminate lots of dataquality challenges and bring a test-first approach through your agile cycle.
This blog post is co-written with Raj Samineni from ATPCO. In today’s data-driven world, companies across industries recognize the immense value of data in making decisions, driving innovation, and building new products to serve their customers. Choose the Amazon DataZone blueprint you want to enable.
One of the bank’s key challenges related to strict cybersecurity requirements is to implement field level encryption for personally identifiable information (PII), Payment Card Industry (PCI), and data that is classified as high privacy risk (HPR). Only users with required permissions are allowed to access data in clear text.
Data: the foundation of your foundation model Dataquality matters. An AI model trained on biased or toxic data will naturally tend to produce biased or toxic outputs. When objectionable data is identified, we remove it, retrain the model, and repeat. Data curation is a task that’s never truly finished.
Part Two of the Digital Transformation Journey … In our last blog on driving digital transformation , we explored how enterprise architecture (EA) and business process (BP) modeling are pivotal factors in a viable digital transformation strategy. With automation, dataquality is systemically assured.
Lastly, active data governance simplifies stewardship tasks of all kinds. Tehnical stewards have the tools to monitor dataquality, access, and access control. A compliance steward is empowered to monitor sensitive data and usage sharing policies at scale. The Data Swamp Problem. Subscribe to Alation's Blog.
Figure 2: Example data pipeline with DataOps automation. In this project, I automated data extraction from SFTP, the public websites, and the email attachments. The automated orchestration published the data to an AWS S3 DataLake. All the code, Talend job, and the BI report are version controlled using Git.
Many customers need an ACID transaction (atomic, consistent, isolated, durable) datalake that can log change data capture (CDC) from operational data sources. There is also demand for merging real-time data into batch data. Delta Lake framework provides these two capabilities. Choose Create role.
For state and local agencies, data silos create compounding problems: Inaccessible or hard-to-access data creates barriers to data-driven decision making. Legacy data sharing involves proliferating copies of data, creating data management, and security challenges. Forrester ). Gartner ).
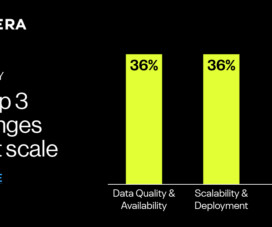
Among the most common challenges to achieving AI adoption at scale were dataquality and availability (36%), scalability and deployment (36%), integration with existing systems and processes (35%), and change management and organizational culture (34%).
And where data was available, the ability to access and interpret it proved problematic. Big data can grow too big fast. Left unchecked, datalakes became data swamps. Some datalake implementations required expensive ‘cleansing pumps’ to make them navigable again. Subscribe to Alation's Blog.
After countless open-source innovations ushered in the Big Data era, including the first commercial distribution of HDFS (Apache Hadoop Distributed File System), commonly referred to as Hadoop, the two companies joined forces, giving birth to an entire ecosystem of technology and tech companies. We hope to see you there.
Data observability provides insight into the condition and evolution of the data resources from source through the delivery of the data products. Barr Moses of Monte Carlo presents it as a combination of data flow, dataquality, data governance, and data lineage. Source: IDC .
Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source datalake.
Thoughtworks says data mesh is key to moving beyond a monolithic datalake. Spoiler alert: data fabric and data mesh are independent design concepts that are, in fact, quite complementary. Thoughtworks says data mesh is key to moving beyond a monolithic datalake 2. Gartner on Data Fabric.
Griffin is an open source dataquality solution for big data, which supports both batch and streaming mode. In today’s data-driven landscape, where organizations deal with petabytes of data, the need for automated data validation frameworks has become increasingly critical.
A data lakehouse is an emerging data management architecture that improves efficiency and converges data warehouse and datalake capabilities driven by a need to improve efficiency and obtain critical insights faster. Let’s start with why data lakehouses are becoming increasingly important.
analyst Sumit Pal, in “Exploring Lakehouse Architecture and Use Cases,” published January 11, 2022: “Data lakehouses integrate and unify the capabilities of data warehouses and datalakes, aiming to support AI, BI, ML, and data engineering on a single platform.” According to Gartner, Inc.
As organizations become data-driven and awash in an overwhelming amount of data from multiple data sources (AI, IOT, ML, etc.), organizations will need to get a better handle on dataquality and focus on data management processes and practices. To stay up to date, click here to subscribe.
In addition to the tracking of relationships and quality metrics, DataOps Observability journeys allow users to establish baselines?concrete concrete expectations for run schedules, run durations, dataquality, and upstream and downstream dependencies. And she’ll know when newer data will arrive.
Since its uniquely metadata-driven, the abstraction layer of a data fabric makes it easier to model, integrate and query any data sources, build data pipelines, and integrate data in real-time. This improves data engineering productivity and time-to-value for data consumers. What’s a data mesh?
Figure 1 illustrates the typical metadata subjects contained in a data catalog. Figure 1 – Data Catalog Metadata Subjects. Datasets are the files and tables that data workers need to find and access. They may reside in a datalake, warehouse, master data repository, or any other shared data resource.
However, companies are still struggling to manage data effectively, to implement GenAI applications that deliver proven business value. The post OReilly Releases First Chapters of a New Book about Logical Data Management appeared first on Data Management Blog - Data Integration and Modern Data Management Articles, Analysis and Information.
Improved Decision Making : Well-modeled data provides insights that drive informed decision-making across various business domains, resulting in enhanced strategic planning. Reduced Data Redundancy : By eliminating data duplication, it optimizes storage and enhances dataquality, reducing errors and discrepancies.
This is especially beneficial when teams need to increase data product velocity with trust and dataquality, reduce communication costs, and help data solutions align with business objectives. In most enterprises, data is needed and produced by many business units but owned and trusted by no one.
With in-place table migration, you can rapidly convert to Iceberg tables since there is no need to regenerate data files. Newly generated metadata will then point to source data files as illustrated in the diagram below. . Dataquality using table rollback. Only metadata will be regenerated.
Previously, there were three types of data structures in telco: . Entity data sets — i.e. marketing datalakes . Optimization Data lakehouse is the platform wherein the data assets reside. The post Modern Data Architecture for Telecommunications appeared first on Cloudera Blog.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content