This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The market for datawarehouses is booming. While there is a lot of discussion about the merits of datawarehouses, not enough discussion centers around datalakes. We talked about enterprise datawarehouses in the past, so let’s contrast them with datalakes. DataWarehouse.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
Amazon SageMaker Lakehouse , now generally available, unifies all your data across Amazon Simple Storage Service (Amazon S3) datalakes and Amazon Redshift datawarehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. The tools to transform your business are here.
Reading Time: 3 minutes First we had datawarehouses, then came datalakes, and now the new kid on the block is the data lakehouse. But what is a data lakehouse and why should we develop one? In a way, the name describes what.
Amazon Redshift is a fast, fully managed petabyte-scale cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. and later supports the Apache Iceberg framework for datalakes. AWS Glue 3.0 The following diagram illustrates the solution architecture.
First-generation – expensive, proprietary enterprise datawarehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt. The post What is a Data Mesh?
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift. Do not overwrite existing files.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. The results demonstrate superior price performance of Cloudera DataWarehouse on the full set of 99 queries from the TPC-DS benchmark. Introduction.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient data analytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. They decided to focus on four runtime engines. 5 seconds $0.08
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
The amount of data being generated and stored every day has exploded. Companies of all kinds are sitting on stockpiles of data that could someday prove valuable. Until then though, they don’t necessarily want to spend the time and resources necessary to create a schema to house this data in a traditional datawarehouse.
This book is not available until January 2022, but considering all the hype around the data mesh, we expect it to be a best seller. In the book, author Zhamak Dehghani reveals that, despite the time, money, and effort poured into them, datawarehouses and datalakes fail when applied at the scale and speed of today’s organizations.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Cloud computing has made it much easier to integrate data sets, but that’s only the beginning. Creating a datalake has become much easier, but that’s only ten percent of the job of delivering analytics to users. It often takes months to progress from a datalake to the final delivery of insights.
Artificial Intelligence and machine learning are the future of every industry, especially data and analytics. AI and ML are the only ways to derive value from massive datalakes, cloud-native datawarehouses, and other huge stores of information. Use AI to tackle huge datasets.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, datawarehouse, and purpose-built stores with a unified governance model. Of those tables, some are larger (such as in terms of record volume) than others, and some are updated more frequently than others.
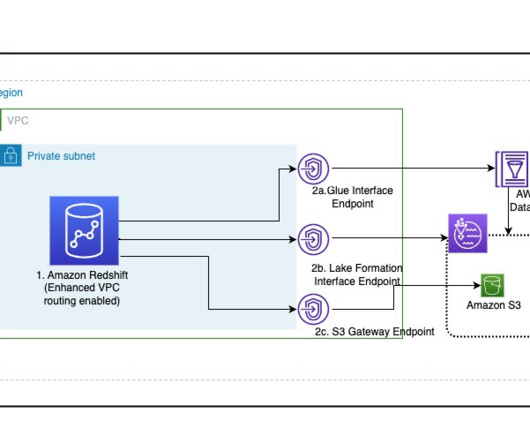
This leads to having data across many instances of datawarehouses and datalakes using a modern data architecture in separate AWS accounts. We recently announced the integration of Amazon Redshift data sharing with AWS Lake Formation.
When you build your transactional datalake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 datalake to optimize the production environment. availability. Note the configuration parameters s3.write.tags.write-tag-name write.tags.write-tag-name and s3.delete.tags.delete-tag-name
This post explores how to start using Delta Lake UniForm on Amazon Web Services (AWS). You can learn how to query Delta Lake native tables through UniForm from different datawarehouses or engines such as Amazon Redshift as an example of expanding data access to more engines. Open the Amazon EMR on EC2 console.
Enterprise data is brought into datalakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Run the following Shell script commands in the console to copy the Jupyter Notebooks.
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications. For InitialRunFlag , choose Setup.
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera DataWarehouse with Iceberg. We will publish follow up blogs for other data services. It allows us to independently upgrade the Virtual Warehouses and Database Catalogs.
New data is shared with users by updating reporting schema several times a day. The architecture takes purpose-built datawarehouses /marts and other forms of aggregation and star views tailored to analyst requirements. The DataOps Platform does not replace a datalake or the data hub. It’s that simple. .
This blog post is co-written with Ori Nakar from Imperva. Events and many other security data types are stored in Imperva’s Threat Research Multi-Region datalake. Imperva harnesses data to improve their business outcomes. Imperva’s datalake has a few dozen different datasets, in the scale of petabytes.
“Data mesh” is a new data analytics paradigm proposed by Zhamak Dehghani, one that is designed to move organizations from monolithic architectures such as the datawarehouse and the datalake to more decentralized architectures. As long-time supporters of logical.
“Data mesh” is a new data analytics paradigm proposed by Zhamak Dehghani, one that is designed to move organizations from monolithic architectures such as the datawarehouse and the datalake to more decentralized architectures. As long-time supporters of logical.
In a datawarehouse, a dimension is a structure that categorizes facts and measures in order to enable users to answer business questions. As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise datawarehouses. On datawarehouses and datalakes.
Datawarehouse vs. databases Traditional vs. Cloud Explained Cloud datawarehouses in your data stack A data-driven future powered by the cloud. We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Datawarehouse vs. databases.
How self-service data warehousing frees IT resources. Cloudera DataWarehouse (CDW) is a cloud service and an integral part of the newly released Cloudera Data Platform (CDP). Key features are: Highly scalable and performant open-source engines for BI and data warehousing workloads. Simplified provisioning.
If you’ve decided to implement a datalake, you might want to keep Gartner’s assessment in mind, which is that about 80% of all datalakes projects will actually fail. The post Data Virtualization: The Key to a Successful DataLakes appeared first on Data Virtualization blog.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. The rise of cloud has allowed datawarehouses to provide new capabilities such as cost-effective data storage at petabyte scale, highly scalable compute and storage, pay-as-you-go pricing and fully managed service delivery.
Many customers are extending their datawarehouse capabilities to their datalake with Amazon Redshift. They are looking to further enhance their security posture where they can enforce access policies on their datalakes based on Amazon Simple Storage Service (Amazon S3).
Now generally available, the M&E data lakehouse comes with industry use-case specific features that the company calls accelerators, including real-time personalization, said Steve Sobel, the company’s global head of communications, in a blog post. Features focus on media and entertainment firms.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible data transforms in Python and SQL. dbt is predominantly used by datawarehouses (such as Amazon Redshift ) customers who are looking to keep their data transform logic separate from storage and engine.
Modern data architectures deliver key functionality in terms of flexibility and scalability of data management. This form of architecture can handle data in all forms—structured, semi-structured, unstructured—blending capabilities from datawarehouses and datalakes into data lakehouses.
Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions. By running reports on historical data, a datawarehouse can clarify what systems and processes are working and what methods need improvement.
While many organizations understand the business need for a data and analytics cloud platform , few can quickly modernize their legacy datawarehouse due to a lack of skills, resources, and data literacy. Security DataLake. Learn more about our Security DataLake Solution.
We live in a world of data: there’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways Data Teams are tackling the challenges of this new world to help their companies and their customers thrive. The ETL process and datawarehouses.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission-critical, large-scale data analytics and AI use cases—including enterprise datawarehouses. Learn more about the Cloudera Open Data Lakehouse here.
If you’ve decided to implement a datalake, you might want to keep Gartner’s assessment in mind, which is that about 80% of all datalake projects will actually fail. The post Data Virtualization: The Key to a Successful DataLake appeared first on Data Virtualization blog.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content