This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Clean your data to ensure dataquality. Correct any dataquality issues to make the data most applicable to your task. This includes removing invalid or meaningless entries, adjusting data fields to accommodate multiple values, fixing inconsistencies, etc. Maximize the usability of your data.
We rather see it as a new paradigm that is revolutionizing enterprise data integration and knowledgediscovery. Ontotext was founded in 2000 with the Semantic Web in its genes and we had the chance to be part of the community of its pioneers. We can’t imagine looking at the Semantic Web as an artifact.
Consider using data catalogs for this purpose. Clean data to ensure dataquality. Correct any dataquality issues to make the data most applicable to your task. This includes removing invalid or meaningless entries, adjusting data fields to accommodate multiple values, fixing inconsistencies, etc.
The added contextual richness promotes comprehensive analysis and knowledge creation and sharing that was previously unachievable. It’s common for enterprises to have multiple data systems and heterogenous data sets using varying terminology for similar concepts. Unlock the full potential of your data!
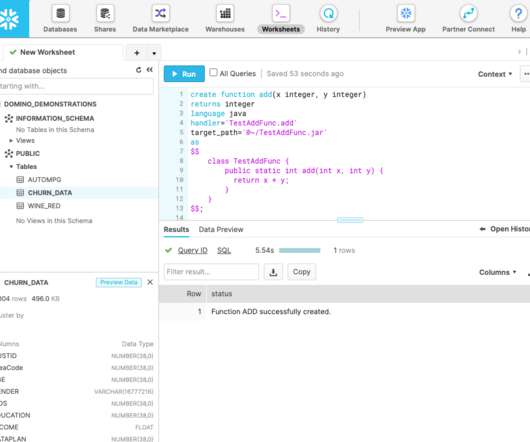
The recently announced partnership between Domino Data Lab and Snowflake enhanced this experience with the integration of Snowflake’s Snowpark and Java UDFs in Domino. Snowpark is a new developer experience, which enables data scientists to leverage their favourite tools and deploy code directly within Snowflake. Why Snowflake UDFs.
In an engaging narrative built on the premise that most organizations are not ready for a knowledge graph, Lance talked about the usual pitfalls when building such a solution. According to him, “failing to ensure dataquality in capturing and structuring knowledge, turns any knowledge graph into a piece of abstract art”.
Graphs boost knowledgediscovery and efficient data-driven analytics to understand a company’s relationship with customers and personalize marketing, products, and services. Linked Data, subscriptions, purchased datasets, etc.).
Capturing data, converting it into the right insights, and integrating those insights quickly and efficiently into business decisions and processes is generating a significant competitive advantage for those who do it right.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content