This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Announcing DataOps DataQuality TestGen 3.0: Open-Source, Generative DataQuality Software. You don’t have to imagine — start using it today: [link] Introducing DataQuality Scoring in Open Source DataOps DataQuality TestGen 3.0! DataOps just got more intelligent.
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
By adding the Octopai platform, Cloudera customers will benefit from: Enhanced Data Discovery: Octopai’s automated data discovery enables instantaneous search and location of desired data across multiple systems. This guarantees dataquality and automates the laborious, manual processes required to maintain data reliability.
When an organization’s data governance and metadata management programs work in harmony, then everything is easier. Data governance is a complex but critical practice. There’s always more data to handle, much of it unstructured; more data sources, like IoT, more points of integration, and more regulatory compliance requirements.
Metadata management is key to wringing all the value possible from data assets. However, most organizations don’t use all the data at their disposal to reach deeper conclusions about how to drive revenue, achieve regulatory compliance or accomplish other strategic objectives. What Is Metadata? Harvest data.
What Is Metadata? Metadata is information about data. A clothing catalog or dictionary are both examples of metadata repositories. Indeed, a popular online catalog, like Amazon, offers rich metadata around products to guide shoppers: ratings, reviews, and product details are all examples of metadata.
It addresses many of the shortcomings of traditional data lakes by providing features such as ACID transactions, schema evolution, row-level updates and deletes, and time travel. In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient.
Not Every Graph is a Knowledge Graph: Schemas and Semantic Metadata Matter. To be able to automate these operations and maintain sufficient dataquality, enterprises have started implementing the so-called data fabrics , that employ diverse metadata sourced from different systems. Such examples are provenance (e.g.
Untapped data, if mined, represents tremendous potential for your organization. While there has been a lot of talk about big data over the years, the real hero in unlocking the value of enterprise data is metadata , or the data about the data. Metadata Is the Heart of Data Intelligence.
Metadata is an important part of data governance, and as a result, most nascent data governance programs are rife with project plans for assessing and documenting metadata. But in many scenarios, it seems that the underlying driver of metadata collection projects is that it’s just something you do for data governance.
Data teams struggle to find a unified approach that enables effortless discovery, understanding, and assurance of dataquality and security across various sources. Having confidence in your data is key. Automate data profiling and dataquality recommendations, monitor dataquality rules, and receive alerts.
Aptly named, metadata management is the process in which BI and Analytics teams manage metadata, which is the data that describes other data. In other words, data is the context and metadata is the content. Without metadata, BI teams are unable to understand the data’s full story.
If the data is not easily gathered, managed and analyzed, it can overwhelm and complicate decision-makers. Data insight techniques provide a comprehensive set of tools, data analysis and quality assurance features to allow users to identify errors, enhance dataquality, and boost productivity.’
Some customers build custom in-house data parity frameworks to validate data during migration. Others use open source dataquality products for data parity use cases. This takes away important person hours from the actual migration effort into building and maintaining a data parity framework.
These formats, exemplified by Apache Iceberg, Apache Hudi, and Delta Lake, addresses persistent challenges in traditional data lake structures by offering an advanced combination of flexibility, performance, and governance capabilities. These are useful for flexible data lifecycle management.
We have identified the top ten sites, videos, or podcasts online that deal with data lineage. Our list of Top 10 Data Lineage Podcasts, Blogs, and Websites To Follow in 2021. Data Engineering Podcast. This podcast centers around data management and investigates a different aspect of this field each week.
I have developed a few rules to help drive quick wins and facilitate success in data-intensive and AI ( e.g., Generative AI and ChatGPT) deployments. Love thy data: data are never perfect, but all the data may produce value, though not immediately. The latter is essential for Generative AI implementations.
Discoverable – users have access to a catalog or metadata management tool which renders the domain discoverable and accessible. Secure and permissioned – data is protected from unauthorized users. Governed – designed with dataquality and management workflows that empower data usage. The post What is a Data Mesh?
If you are not observing and reacting to the data, the model will accept every variant and it may end up one of the more than 50% of models, according to Gartner , that never make it to production because there are no clear insights and the results have nothing to do with the original intent of the model.
To marry the epidemiological data to the population data it will require a tremendous amount of data intelligence about the: Source of the data; Currency of the data; Quality of the data; and. Unraveling Data Complexities with Metadata Management. Data lineage to support impact analysis.
Metadata management performs a critical role within the modern data management stack. It helps blur data silos, and empowers data and analytics teams to better understand the context and quality of data. This, in turn, builds trust in data and the decision-making to follow. Improve data discovery.
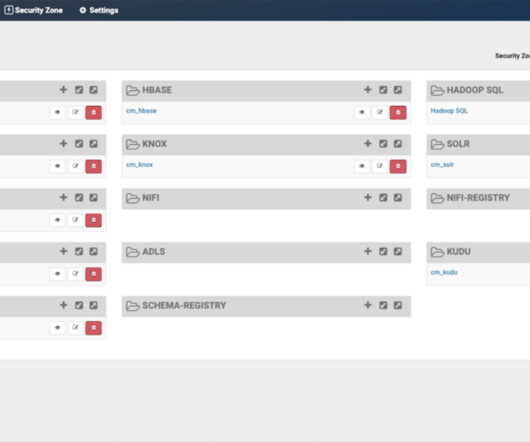
In this article, we will walk you through the process of implementing fine grained access control for the data governance framework within the Cloudera platform. In a good data governance strategy, it is important to define roles that allow the business to limit the level of access that users can have to their strategic data assets.
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
Like the proverbial man looking for his keys under the streetlight , when it comes to enterprise data, if you only look at where the light is already shining, you can end up missing a lot. The data you’ve collected and saved over the years isn’t free. Analyze your metadata. Real-time, cloud-based data ingestion and storage.
Data intelligence software is continuously evolving to enable organizations to efficiently and effectively advance new data initiatives. With a variety of providers and offerings addressing data intelligence and governance needs, it can be easy to feel overwhelmed in selecting the right solution for your enterprise.
Alation and Soda are excited to announce a new partnership, which will bring powerful data-quality capabilities into the data catalog. Soda’s data observability platform empowers data teams to discover and collaboratively resolve data issues quickly. Do we have end-to-end data pipeline control?
Metadata is an important part of data governance, and as a result, most nascent data governance programs are rife with project plans for assessing and documenting metadata. But in many scenarios, it seems that the underlying driver of metadata collection projects is that it’s just something you do for data governance.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Data is the new oil and organizations of all stripes are tapping this resource to fuel growth. However, dataquality and consistency are one of the top barriers faced by organizations in their quest to become more data-driven. Unlock qualitydata with IBM. and its leading data observability offerings.
In a sea of questionable data, how do you know what to trust? Dataquality tells you the answer. It signals what data is trustworthy, reliable, and safe to use. It empowers engineers to oversee data pipelines that deliver trusted data to the wider organization. Today, as part of its 2022.2
Metadata enrichment is about scaling the onboarding of new data into a governed data landscape by taking data and applying the appropriate business terms, data classes and quality assessments so it can be discovered, governed and utilized effectively. Scalability and elasticity. Public API.
This happens through the process of semantic annotation , where documents are tagged with relevant concepts and enriched with metadata , i.e., references that link the content to concepts, described in a knowledge graph. When “reading” unstructured text, AI systems first need to transform it into machine-readable sets of facts.
Part Two of the Digital Transformation Journey … In our last blog on driving digital transformation , we explored how enterprise architecture (EA) and business process (BP) modeling are pivotal factors in a viable digital transformation strategy. With automation, dataquality is systemically assured.
The results of our new research show that organizations are still trying to master data governance, including adjusting their strategies to address changing priorities and overcoming challenges related to data discovery, preparation, quality and traceability. Most have only data governance operations.
These layers help teams delineate different stages of data processing, storage, and access, offering a structured approach to data management. In the context of Data in Place, validating dataquality automatically with Business Domain Tests is imperative for ensuring the trustworthiness of your data assets.
It’s the preferred choice when customers need more control and customization over the data integration process or require complex transformations. This flexibility makes Glue ETL suitable for scenarios where data must be transformed or enriched before analysis. In the navigation pane, under Data catalog , choose Zero-ETL integrations.
Analysis, however, requires enterprises to find and collect metadata. This data about data is valuable. In fact, Gartner’s “Market Guide for Active Metadata Management” points to “ active metadata management ” as the key to continuous data analysis – which supports smarter human usage and more valuable insights.
An understanding of the data’s origins and history helps answer questions about the origin of data in a Key Performance Indicator (KPI) reports, including: How the report tables and columns are defined in the metadata? Who are the data owners? Data lineage offers proof that the data provided is reflected accurately.
At DataKitchen, we think of this is a ‘meta-orchestration’ of the code and tools acting upon the data. Data Pipeline Observability: Optimizes pipelines by monitoring dataquality, detecting issues, tracing data lineage, and identifying anomalies using live and historical metadata.
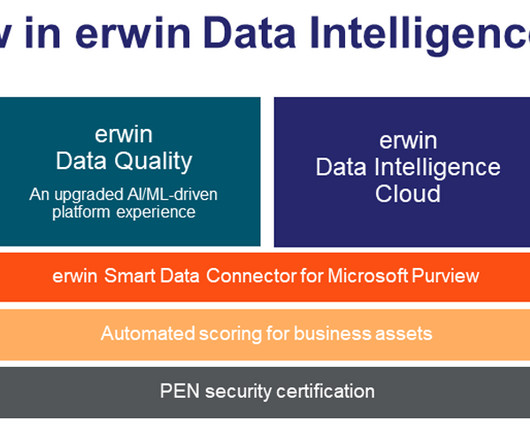
Added dataquality capability ready for an AI era Dataquality has never been more important than as we head into this next AI-focused era. erwin DataQuality is the dataquality heart of erwin Data Intelligence. erwin DataQuality is the dataquality heart of erwin Data Intelligence.
Based on business rules, additional dataquality tests check the dimensional model after the ETL job completes. While implementing a DataOps solution, we make sure that the pipeline has enough automated tests to ensure dataquality and reduce the fear of failure. Monitoring Job Metadata.
Automated data enrichment : To create the knowledge catalog, you need automated data stewardship services. These services include the ability to auto-discover and classify data, to detect sensitive information, to analyze dataquality, to link business terms to technical metadata and to publish data to the knowledge catalog.
In 2017, Anthem reported a data breach that exposed thousands of its Medicare members. The medical insurance company wasn’t hacked, but its customers’ data was compromised through a third-party vendor’s employee. 86% of Experian survey respondents’, for instance, are prioritizing moving their data to the cloud in 2022.
Observability for your most secure data For your most sensitive, protected data, we understand even the metadata and telemetry about your workloads must be kept under close watch, and it must stay within your secured environment. The post Introducing Cloudera Observability Premium appeared first on Cloudera Blog.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content