This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
A Drug Launch Case Study in the Amazing Efficiency of a Data Team Using DataOps How a Small Team Powered the Multi-Billion Dollar Acquisition of a Pharma Startup When launching a groundbreaking pharmaceutical product, the stakes and the rewards couldnt be higher. data engineers delivered over 100 lines of code and 1.5
They made us realise that building systems, processes and procedures to ensure quality is built in at the outset is far more cost effective than correcting mistakes once made. How about dataquality? Redman and David Sammon, propose an interesting (and simple) exercise to measure dataquality.
The refresh was long past its deadline, the projects key data engineer was on vacation, and I was playing backup. At the moment, I was flying home from a dataquality conference. And they caught a major problem: the new records we received from one source were completely out of sync with our other data. Where was I?
Data teams struggle to find a unified approach that enables effortless discovery, understanding, and assurance of dataquality and security across various sources. Collaboration is seamless, with straightforward publishing and subscribing workflows, fostering a more connected and efficient work environment.
Due to the volume, velocity, and variety of data being ingested in data lakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your data lake. Data confidentiality and dataquality are the two essential themes for data governance.
Poor-qualitydata can lead to incorrect insights, bad decisions, and lost opportunities. AWS Glue DataQuality measures and monitors the quality of your dataset. It supports both dataquality at rest and dataquality in AWS Glue extract, transform, and load (ETL) pipelines.
It’s the preferred choice when customers need more control and customization over the data integration process or require complex transformations. This flexibility makes Glue ETL suitable for scenarios where data must be transformed or enriched before analysis. The status and statistics of the CDC load are published into CloudWatch.
Our next book is dedicated to anyone who wants to start a career as a data scientist and is looking to get all the knowledge and skills in a way that is accessible and well-structured. Originally published in 2018, the book has a second edition that was released in January of 2022. 4) “SQL Performance Explained” by Markus Winand.
Here at Smart Data Collective, we never cease to be amazed about the advances in data analytics. We have been publishing content on data analytics since 2008, but surprising new discoveries in big data are still made every year. One of the biggest trends shaping the future of data analytics is drone surveying.
He is the President of Knowledge Integrity, Inc and an expert in master data management, dataquality, and business intelligence. His articles on TDWI deal with advice for analysts, customer data profiling, master data management technology, and machine learning. . It is published by Robert S.
This blog post is co-written with Hardeep Randhawa and Abhay Kumar from HPE. Dataquality checks When the files land in the processing zone, the Step Functions workflow invokes another Lambda function that converts the raw files to CSV format followed by stringent dataquality checks.
Data intelligence software is continuously evolving to enable organizations to efficiently and effectively advance new data initiatives. With a variety of providers and offerings addressing data intelligence and governance needs, it can be easy to feel overwhelmed in selecting the right solution for your enterprise.
The medical insurance company wasn’t hacked, but its customers’ data was compromised through a third-party vendor’s employee. In the 2020 O’Reilly DataQuality survey only 20% of respondents say their organizations publish information about data provenance or data lineage internally.
You will need to continually return to your business dashboard to make sure that it’s working, the data is accurate and it’s still answering the right questions in the most effective way. Testing will eliminate lots of dataquality challenges and bring a test-first approach through your agile cycle.
Automated data enrichment : To create the knowledge catalog, you need automated data stewardship services. These services include the ability to auto-discover and classify data, to detect sensitive information, to analyze dataquality, to link business terms to technical metadata and to publishdata to the knowledge catalog.
This blog post is co-written with Raj Samineni from ATPCO. In today’s data-driven world, companies across industries recognize the immense value of data in making decisions, driving innovation, and building new products to serve their customers. Publishdata assets. Create and configure an Amazon DataZone domain.
At Workiva, they recognized that they are only as good as their data, so they centered their initial DataOps efforts around lowering errors. Hodges commented, “Our first focus was to up our game around dataquality and lowering errors in production. Organizations should be optimizing and driving their data teams with data.” .
Figure 2: Example data pipeline with DataOps automation. In this project, I automated data extraction from SFTP, the public websites, and the email attachments. The automated orchestration published the data to an AWS S3 Data Lake. All the code, Talend job, and the BI report are version controlled using Git.
As a result, the data may be compromised, rendering faulty analyses and insights. To marry the epidemiological data to the population data it will require a tremendous amount of data intelligence about the: Source of the data; Currency of the data; Quality of the data; and.
Sun has a PhD from MIT and continued to publish academic research papers during his time at Microsoft, in addition to teaching at Seattle and Washington universities. In a recent blog post, Sun described how Microsoft researchers conducted experiments to compare the performance of different AI models for use in Dynamics 365.
There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. This is something that you can learn more about in just about any technology blog. We would like to talk about data visualization and its role in the big data movement.
According to a recent TechJury survey: Data analytics makes decision-making 5x faster for businesses. The top three business intelligence trends are data visualization, dataquality management, and self-service business intelligence (BI). 7 out of 10 business rate data discovery as very important.
In this blog we take a closer look at the recently published BARC study “Sound Decisions in Dynamic Times.” The improvement in dataquality follows with 53%. This finding is in line with what US-based FP&A expert Brian Kalish recently stated in his guest blog on data analysis : Data is abundant.
In fact, the Foundry’s recently published Cloud Computing Study (2022) found that 84% of organizations have at least one application, or a portion of their computing infrastructure already in the cloud. This has increased the difficulty for IT to provide the governance, compliance, risks, and dataquality management required.
Griffin is an open source dataquality solution for big data, which supports both batch and streaming mode. In today’s data-driven landscape, where organizations deal with petabytes of data, the need for automated data validation frameworks has become increasingly critical.
It also helps enterprises put these strategic capabilities into action by: Understanding their business, technology and data architectures and their inter-relationships, aligning them with their goals and defining the people, processes and technologies required to achieve compliance.
If he is to take Gartner’s advice to heart, Marcus will have to add a set of tasks to his team’s daily data engineering tasks. When these enablers are implemented, such as through DataKitchen products, teams will work faster, produce higher-quality results, and will be happier. Learn More Implement DataOps Data Engineering yourself.
These formats, exemplified by Apache Iceberg, Apache Hudi, and Delta Lake, addresses persistent challenges in traditional data lake structures by offering an advanced combination of flexibility, performance, and governance capabilities. Auto generated keys Traditionally, Hudi required explicit configuration of primary keys for every table.
Given the importance of data in the world today, organizations face the dual challenges of managing large-scale, continuously incoming data while vetting its quality and reliability. AWS Glue is a serverless data integration service that you can use to effectively monitor and manage dataquality through AWS Glue DataQuality.
What are the metrics that matter? Gartner attempted to list every metric under the sun in their recent report , “T oolkit: Delivery Metrics for DataOps, Self-Service Analytics, ModelOps, and MLOps, ” published February 7, 2023. For example, Gartner’s DataOps metrics can be categorized into Velocity, Efficiency, and Quality.
Since its uniquely metadata-driven, the abstraction layer of a data fabric makes it easier to model, integrate and query any data sources, build data pipelines, and integrate data in real-time. This improves data engineering productivity and time-to-value for data consumers. What’s a data mesh?
If you read my blog regularly then you know I rarely write about IT vendors. If I am moved to write research about a vendor, I’ll write it and publish it behind our pay wall, in the assumption the advice is valuable. This acquisition followed another with Mulesoft, a data integration vendor. That’s the way it is.
As a data analyst or data scientist, we would all love to be able to do all these things, and much more. This is the promise of the modern data lakehouse architecture. Schema evolution: With fast-moving data and real-time data ingestion, we need new ways to keep up with dataquality, consistency, accuracy, and overall integrity.
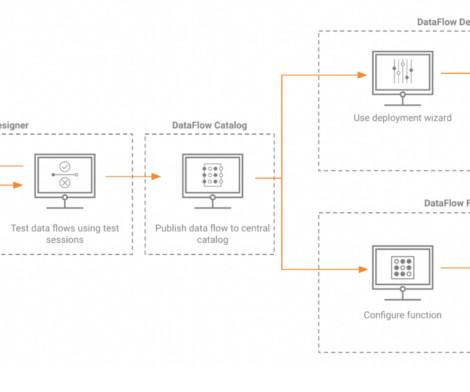
Dataquality issue? Good luck auditing data lineage and definitions where policies were never enforced. The new DataFlow Designer is more than just a new UI — it is a paradigm shift in the process of data flow development. Security breach? Massive cloud consumption bill you can’t account for?
We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways data teams are tackling the challenges of this new world to help their companies and their customers thrive. billion market by 2025.
It has been over a decade since the Federal Reserve Board (FRB) and the Office of the Comptroller of the Currency (OCC) published its seminal guidance focused on Model Risk Management ( SR 11-7 & OCC Bulletin 2011-12 , respectively). To reference SR 11-7: .
Improved Decision Making : Well-modeled data provides insights that drive informed decision-making across various business domains, resulting in enhanced strategic planning. Reduced Data Redundancy : By eliminating data duplication, it optimizes storage and enhances dataquality, reducing errors and discrepancies.
Data governance policy should be owned by the top of the organization so data governance is given appropriate attention — including defining what’s a potential risk and what is poor dataquality.” It comes down to the question: What is the value of your data? Subscribe to Alation's Blog.
If you are an Analyst or a Marketer or a Website Owner or a Website User it is critical that you read this short blog post – your data will make so much more sense after are done. Email providers like hotmail (! :) or gmail.com, ecommerce websites like amazon.com or crutchfield.com, banks, even blogging platforms!
Background: “Apathy is the enemy of dataquality”. I began work on dataquality in the late 1980s at the great Bell Laboratories. This led me to conclude, by about 2000, that apathy was the number one enemy of dataquality. I especially wanted to identify industries that were ripe for dataquality.
The data mesh approach distributes data ownership and decentralizes data architecture, paving the way for enhanced agility and scalability. With distributed ownership there is a need for effective governance to ensure the success of any data initiative. Business Glossaries – what is the business meaning of our data?
Along with raw data entries in these statements, additional financial ratios such as year-on-year changes in return on assets or book-to-market value are useful machine learning features as well. The dataset used in the following example was published in the Journal of Accounting Research. See DataRobot in Action. Request a Demo.
This feature significantly increases the productivity of the data stewards who provide business context to data by ensuring dataquality, usefulness and protection for broader consumption. The post Metadata enrichment – highly scalable data classification and data discovery appeared first on Journey to AI Blog.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content