This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataqualitytest coverage has become one of the most critical challenges facing modern data engineering teams, particularly as organizations adopt the increasingly popular Medallion data architecture. Imagine releasing software that has only been partially tested—no development team would accept such risk.
DataQualityTesting: A Shared Resource for Modern Data Teams In today’s AI-driven landscape, where data is king, every role in the modern data and analytics ecosystem shares one fundamental responsibility: ensuring that incorrect data never reaches business customers.
A Guide to the Six Types of DataQuality Dashboards Poor-qualitydata can derail operations, misguide strategies, and erode the trust of both customers and stakeholders. However, not all dataquality dashboards are created equal. These dimensions provide a best practice grouping for assessing dataquality.
The Race For DataQuality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. It sounds great, but how do you prove the data is correct at each layer? How do you ensure dataquality in every layer ?
In software engineering, test coverage is non-negotiable. So why do most data teams still ship data without knowing what’s tested—and what isn’t? You’ll see how a structured approach to datatest coverage can catch issues before stakeholders do.
The DataQuality Revolution Starts with One Person (Yes, That’s You!) Picture this: You’re sitting in yet another meeting where someone asks, “Can we trust this data?” Start Small, Think Customer Here’s where most dataquality initiatives go wrong: they try to boil the ocean.
TL;DR: Functional, Idempotent, Tested, Two-stage (FITT) data architecture has saved our sanity—no more 3 AM pipeline debugging sessions. Each transformation becomes a mathematical function that you can reason about, test, and trust. Want to test a change safely? Re-run it on yesterday’s data and compare outputs.
Whats the overall dataquality score? Most data scientists spend 15-30 minutes manually exploring each new dataset—loading it into pandas, running.info() ,describe() , and.isnull().sum() sum() , then creating visualizations to understand missing data patterns. Perfect for on-demand dataquality checks.
Announcing DataOps DataQuality TestGen 3.0: Open-Source, Generative DataQuality Software. It assesses your data, deploys production testing, monitors progress, and helps you build a constituency within your company for lasting change. New Quality Dashboard & Score Explorer.
In this exciting webinar , Christopher Bergh discussed various types of dataquality dashboards, emphasizing that effective dashboards make data health visible and drive targeted improvements by relying on concrete, actionable tests. Each type serves a unique role in driving changes in dataquality.
This blog was co-authored by DeNA Co., Among these, the healthcare & medical business handles particularly sensitive data. Prevent the inclusion of invalid values in categorical data and process data without any data loss. The challenge Dataqualitytests require performing 1,300 tests on 10 TB of data monthly.
A Drug Launch Case Study in the Amazing Efficiency of a Data Team Using DataOps How a Small Team Powered the Multi-Billion Dollar Acquisition of a Pharma Startup When launching a groundbreaking pharmaceutical product, the stakes and the rewards couldnt be higher. data engineers delivered over 100 lines of code and 1.5
Scaling Data Reliability: The Definitive Guide to Test Coverage for Data Engineers The parallels between software development and data analytics have never been more apparent. Let us show you how to implement full-coverage automatic data checks on every table, column, tool, and step in your delivery process.
The Hidden Crisis in Data Usability … and How DataOps DataQuality TestGen Can Help Fix It In many data organizations, there’s a silent crisis: data usability is broken. Whether you work in dataquality or engineering, you’ve probably said one of these things: “That’s the way the data came to us.”
These aren’t just any data points—they are the backbone of your operations, the foundation of your decision-making, and often the difference between business success and failure. Identifying CDEs is a vital step in data governance because it changes how organizations handle dataquality.
Is Your Team in Denial of DataQuality? Here’s How to Tell In many organizations, dataquality problems fester in the shadowsignored, rationalized, or swept aside with confident-sounding statements that mask a deeper dysfunction. That’s not testing; that’s wishful thinking. Is your team ready?
When you understand distributions, you can spot dataquality issues instantly. When you know hypothesis testing, you know whether your A/B test results actually mean something. Hypothesis testing gives you the framework to make valid and provable claims. Learn t-tests, chi-square tests, and confidence intervals.
We’ve identified two distinct types of data teams: process-centric and data-centric. Understanding this framework offers valuable insights into team efficiency, operational excellence, and dataquality. Process-centric data teams focus their energies predominantly on orchestrating and automating workflows.
At the moment, I was flying home from a dataquality conference. He slacked back data. An embedded test had failed. And I was tempted, so tempted, as the clock kept ticking, to disable the test and let it go. Then it dawned on me that this test wasnt even ours. These tests werent easy to define or implement.
Identify pioneer cases – The team identified the pioneer use cases that onboard the data solution first, to validate its business value. The first use case helps predict test results during the car assembly process. Reuse of consumer-based data saves cost in extract, transform, and load (ETL) implementation and system maintenance.
Step 5: Run Your API To launch the server, use uvicorn like this: uvicorn app.main:app --reload Visit: [link] You’ll see an interactive Swagger UI where you can test the API. That keeps the API responsive and avoids delays.
No Python, No SQL Templates, No YAML: Why Your Open Source DataQuality Tool Should Generate 80% Of Your DataQualityTests Automatically As a data engineer, ensuring dataquality is both essential and overwhelming. Everyone wants to write more tests, yet they somehow never get it done.
random_state=42) Preprocessing the data and making it suitable for the PCA algorithm is as important as applying the algorithm itself. Meanwhile, the transform method is utilized on the testdata, which applies the same transformation "learned" from the training data to the test set.
The Code node examines data types, calculates distributions, identifies correlations, and detects patterns that inform AI recommendations. Next Steps: Scaling AI-Assisted Data Science // 1.
Why DataQuality Isnt Worth The Effort : DataQuality Coffee With Uncle Chip Dataquality has become one of the most discussed challenges in modern data teams, yet it remains one of the most thankless and frustrating responsibilities. How Does Open Source DataOps DataQuality TestGen Help?
Key activities during this phase include: Exploratory Data Analysis (EDA) : Use visualizations and summary statistics to understand distributions, relationships, and anomalies. Data audit : Identify variable types (e.g., numeric, categorical, text), check for missing or inconsistent values, and assess overall dataquality.
How it helps : When youre tweaking hyperparameters and testing different algorithms, keeping track of what worked becomes impossible without proper tooling. Great Expectations: DataQuality Assurance What it solves : Great Expectations is for data validation and quality assurance for ML pipelines How it helps : Bad data breaks models.
Like an Olympic athlete training for the gold, your data needs a continuous, iterative process to maintain peak performance. We covered how DataQualityTesting, Observability, and Scorecards turn dataquality into a dynamic process, helping you build accuracy, consistency, and trust at each layerBronze, Silver, and Gold.
The Gartner presentation, How Can You Leverage Technologies to Solve DataQuality Challenges? by Melody Chien, underscores the critical role of dataquality in modern business operations. Poor dataquality, on average, costs organizations $12.9 million annually , or 7% of their total revenue.
Many enterprises encounter bottlenecks related to dataquality, model deployment, and infrastructure requirements that hinder scaling efforts. The post Scaling AI Solutions with Cloudera: A Deep Dive into AI Inference and Solution Patterns appeared first on Cloudera Blog.
A data catalog providing automated data profiling does just this and, when tied in with data lineage, your organization can easily see metadatas pathway back to all sources feeding your AI model. Monitoring sales revenue data will provide you with regional patterns and anomalies globally.
As data lakes increasingly handle sensitive business data and transactional workloads, maintaining strong dataquality, governance, and compliance becomes vital to maintaining trust and regulatory alignment. This comparison will help guide you in making informed decisions on enhancing your data lake environments.
Self-managing Iceberg tables with large volumes of data poses several challenges, including managing concurrent transactions, processing real-time data streams, handling small file proliferation, maintaining dataquality and governance, and ensuring compliance. AWS Lake Formation and AWS Glue Data Catalog.
Fortunately, Teradata offers integrations to many modular tools that facilitate routine processes allowing data engineers to focus on high-value tasks such as governance, dataquality, and efficiency. schema.yml`: YAML file defining metadata, tests, and descriptions for the models in this directory.
Attempting to build advanced analytics or AI capabilities on shaky data foundations is akin to constructing a skyscraper on quicksand—it may look impressive at first, but it simply won’t stand the test of time. The Solution: Data Strategy as well as AI It is tempting to think that the answer to succesful AI is to implement more AI!
Welcome to the DataQuality Coffee Series with Uncle Chip Pull up a chair, pour yourself a fresh cup, and get ready to talk shopbecause its time for DataQuality Coffee with Uncle Chip. This video series is where decades of data experience meet real-world challenges, a dash of humor, and zero fluff.
Conclusion: Key Takeaways for Data Teams Embracing AI Web Scrapers You can’t overstate the damage poor dataquality causes. AI’s Role in Cleaning and Structuring Data There are many ways AI helps clean up large datasets, especially in eliminating duplicates, correcting formats, and filling in gaps. businesses over $3.1
Oh, yeah, SQL is also heavily tested, especially for analyst and mid-level data science roles. Behavioral questions test how you think and communicate. Tie your answers to data and metrics (e.g., Underestimating SQL Mistake: Not practicing SQL enough, because “it’s easy compared to Python or machine learning”.
“Today’s CIOs inherit highly customized ERPs and struggle to lead change management efforts, especially with systems that [are the] backbone of all the enterprise’s operations,” wrote Isaac Sacolick, founder and president of StarCIO, a digital transformation consultancy, in a recent blog post.
DataQuality When You Dont Understand the Data : DataQuality Coffee With Uncle Chip #3 Lets be honestdata quality feels impossible when you dont understand the data. Thats the crux of the issue: you cant test for what you dont understand. Thats where DataOps DataQuality TestGen comes in.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Amazon SageMaker Catalog serves as a central repository hub to store both technical and business catalog information of the data product.
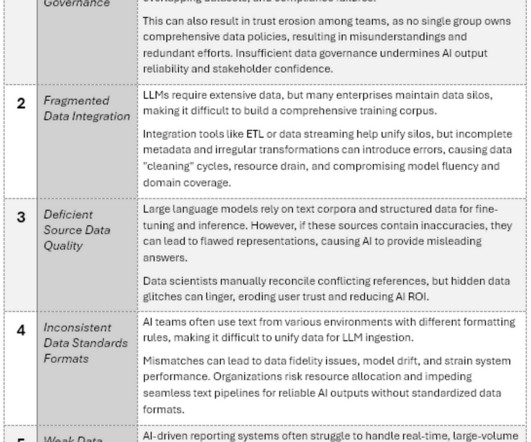
Unleashing GenAIEnsuring DataQuality at Scale (Part1) Transitioning from isolated repository systems to consolidated AI LLM pipelines Photo by Joshua Sortino on Unsplash Introduction This blog is based on insights from articles in Database Trends and Applications, Feb/Mar 2025 ( DBTA Journal ).
Data Observability and DataQualityTesting Certification Series We are excited to invite you to a free four-part webinar series that will elevate your understanding and skills in Data Observation and DataQualityTesting. Don’t miss this opportunity to transform your data practices.
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content