This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
“Big data is at the foundation of all the megatrends that are happening.” – Chris Lynch, big data expert. We live in a world saturated with data. Zettabytes of data are floating around in our digital universe, just waiting to be analyzed and explored, according to AnalyticsWeek. Wondering which datascience book to read?
Savvy data scientists are already applying artificial intelligence and machine learning to accelerate the scope and scale of data-driven decisions in strategic organizations. These datascience teams are seeing tremendous results—millions of dollars saved, new customers acquired, and new innovations that create a competitive advantage.
Data is the most significant asset of any organization. However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture.
In a world focused on buzzword-driven models and algorithms, you’d be forgiven for forgetting about the unreasonable importance of data preparation and quality: your models are only as good as the data you feed them. Why is high-quality and accessible data foundational? Re-analyzing existing data is often very bad.”
Read the complete blog below for a more detailed description of the vendors and their capabilities. This is not surprising given that DataOps enables enterprise data teams to generate significant business value from their data. Testing and Data Observability. Reflow — A system for incremental data processing in the cloud.
Organizational data is often fragmented across multiple lines of business, leading to inconsistent and sometimes duplicate datasets. This fragmentation can delay decision-making and erode trust in available data. This solution enhances governance and simplifies access to unstructured data assets across the organization.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. In addition, organizations rely on an increasingly diverse array of digital systems, data fragmentation has become a significant challenge.
However, they are used as a prominent component of agentic AI. As we look to identify uses for AI Agents, we will find many opportunities. You can use these agents through a process called chaining, where you break down complex tasks into manageable tasks that agents can perform as part of an automated workflow.
The data mesh design pattern breaks giant, monolithic enterprise data architectures into subsystems or domains, each managed by a dedicated team. DataOps helps the data mesh deliver greater business agility by enabling decentralized domains to work in concert. . But first, let’s define the data mesh design pattern.
In enterprises, we’ve seen everything from wholesale adoption to policies that severely restrict or even forbid the use of generative AI. Our survey focused on how companies use generative AI, what bottlenecks they see in adoption, and what skills gaps need to be addressed. What’s the reality? Only 4% pointed to lower head counts.
Introduction Are you a data scientist looking for an exciting and informative read? My latest blog post is jam-packed with fun and innovative experiments that I conducted with ChatGPT over the weekend. In this experiment, I put ChatGPT to the test and challenged it to […] The post How to Use ChatGPT as a Data Scientist?
In this blog post, well dive into the various scenarios for how Cohere Rerank 3.5 OpenSearch Service offers robust search capabilities, including URI searches for simple queries and request body searches using a domain-specific language for complex queries. OpenSearch Service natively supports BM25. See Cohere Rerank 3.5
In June 2021, we asked the recipients of our Data & AI Newsletter to respond to a survey about compensation. The results gave us insight into what our subscribers are paid, where they’re located, what industries they work for, what their concerns are, and what sorts of career development opportunities they’re pursuing.
In contrast, many production AI systems rely on feedback loops that require the same technical skills used during initial development. This distinction assumes a slightly different definition of debugging than is often used in software development. Proper AI product monitoring is essential to this outcome. I/O validation.
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. They aren’t using analytics and AI tools in isolation.
It is appealing to migrate from self-managed OpenSearch and Elasticsearch clusters in legacy versions to Amazon OpenSearch Service to enjoy the ease of use, native integration with AWS services, and rich features from the open-source environment ( OpenSearch is now part of Linux Foundation ). to OpenSearch 2.x),
It is important to realize that the usual “hype cycle” rules prevail in such cases as this. Third, any commitment to a disruptive technology (including data-intensive and AI implementations) must start with a business strategy. These changes may include requirements drift, data drift, model drift, or concept drift.
Below is our third post (3 of 5) on combining data mesh with DataOps to foster greater innovation while addressing the challenges of a decentralized architecture. We’ve talked about data mesh in organizational terms (see our first post, “ What is a Data Mesh? ”) and how team structure supports agility. Source: Thoughtworks.
Previously, we discussed the top 19 big data books you need to read, followed by our rundown of the world’s top business intelligence books as well as our list of the best SQL books for beginners and intermediates. Data visualization, or ‘data viz’ as it’s commonly known, is the graphic presentation of data.
I recently saw an informal online survey that asked users which types of data (tabular, text, images, or “other”) are being used in their organization’s analytics applications. The results showed that (among those surveyed) approximately 90% of enterprise analytics applications are being built on tabular data.
Using business intelligence and analytics effectively is the crucial difference between companies that succeed and companies that fail in the modern environment. The main use of business intelligence is to help business units, managers, top executives, and other operational workers make better-informed decisions backed up with accurate data.
The need to integrate diverse data sources has grown exponentially, but there are several common challenges when integrating and analyzing data from multiple sources, services, and applications. First, you need to create and maintain independent connections to the same data source for different services.
Visualizing the data and interacting on a single screen is no longer a luxury but a business necessity. A professional dashboard maker enables you to access data on a single screen, easily share results, save time, and increase productivity. That’s why we welcome you to the world of interactive dashboards.
As organizations strive to become more data-driven, Forrester recommends 5 actions to take to move from one stage of insights-driven business maturity to another. . Intermediates: Build on your successes and work to scale your IDB capabilities across the enterprise using agile and adaptive DevOps, DataOps, and ModelOps processes. .
DataOps addresses a broad set of usecases because it applies workflow process automation to the end-to-end data-analytics lifecycle. These benefits are hugely important for data professionals, but if you made a pitch like this to a typical executive, you probably wouldn’t generate much enthusiasm.
If a company can usedata to identify compounds more quickly and accelerate the development process, it can monetize its drug pipeline more effectively. DataOps automation provides a way to boost innovation and improve collaboration related to data in pharmaceutical research and development (R&D).
“You can have data without information, but you cannot have information without data.” – Daniel Keys Moran. When you think of big data, you usually think of applications related to banking, healthcare analytics , or manufacturing. However, the usage of data analytics isn’t limited to only these fields. Discover 10.
Container technology has changed the way datascience gets done. The original container usecase for datascience focused on what I call, “environment management”. Container orchestration has the following benefits in datascience work: Remove central IT bottlenecks in the MLOps life cycle.
Enterprise data is brought into data lakes and data warehouses to carry out analytical, reporting, and datascienceusecasesusing AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. We use Anthropic’s Claude 2.1 We use Anthropic’s Claude 2.1
What is it, how does it work, what can it do, and what are the risks of using it? Maybe it’s surprising that ChatGPT can write software, maybe it isn’t; we’ve had over a year to get used to GitHub Copilot, which was based on an earlier version of GPT. A quick scan of the web will show you lots of things that ChatGPT can do.
Below is our fourth post (4 of 5) on combining data mesh with DataOps to foster innovation while addressing the challenges of a decentralized architecture. We’ve covered the basic ideas behind data mesh and some of the difficulties that must be managed. Below is a discussion of a data mesh implementation in the pharmaceutical space.
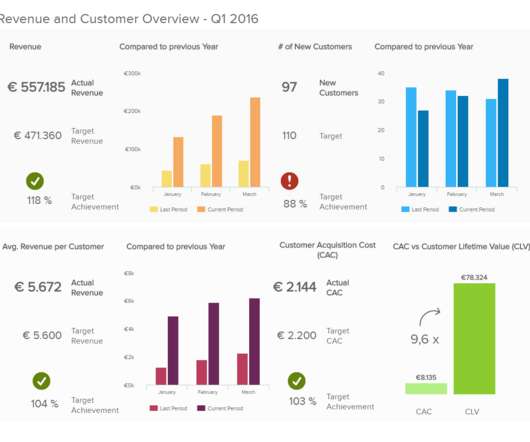
1) What Is Data Interpretation? 2) How To Interpret Data? 3) Why Data Interpretation Is Important? 4) Data Analysis & Interpretation Problems. 5) Data Interpretation Techniques & Methods. 6) The Use of Dashboards For Data Interpretation. What Is Data Interpretation? Table of Contents.
The SEC had charged the two firms with making misleading statements about their use of AI for investment advice, and the companies paid $400,000 in the settlement. Beyond regulatory problems, companies overstating their AI use could expose themselves to shareholder lawsuits and a loss in customer trust, Shargel adds.
The term ‘big data’ alone has become something of a buzzword in recent times – and for good reason. By implementing the right reporting tools and understanding how to analyze as well as to measure your data accurately, you will be able to make the kind of data driven decisions that will drive your business forward.
In the multiverse of datascience, the tool options continue to expand and evolve. While there are certainly engineers and scientists who may be entrenched in one camp or another (the R camp vs. Python, for example, or SAS vs. MATLAB), there has been a growing trend towards dispersion of datascience tools. Snowflake ).
Microsoft has added generative artificial intelligence and other enhanced features to its quantum-computing platform as part of a larger strategy to deliver the game-changing technology to a broader range of users — in this case, the scientific community.
At its Microsoft Ignite 2024 show in Chicago this week, Microsoft and industry partner experts showed off the power of small language models (SLMs) with a new set of fine-tuned, pre-trained AI models using industry-specific data. The company notes that customers can also use the models to configure agents in Microsoft Copilot Studio.
In today’s data-driven world, the ability to seamlessly integrate and utilize diverse data sources is critical for gaining actionable insights and driving innovation. Usecase Consider a large ecommerce company that relies heavily on data-driven insights to optimize its operations, marketing strategies, and customer experiences.
Use Predictive Analytics for Fact-Based Decisions! It must be based on historical data, facts and clear insight into trends and patterns in the market, the competition and customer buying behavior. Like every other business, your organization must plan for success. billion USD in 2022 and is expected to reach $38 billion USD by 2028.
These features combine to make spaCy better than ever at processing large volumes of text and tuning your configuration to match your specific usecase in a way that provides better accuracy. That blog can be found here. ", "David joined Domino Data Lab in February 2020." Bench-marking data from [link].
In 2017, The Economist declared that data, rather than oil, had become the world’s most valuable resource. Organizations across every industry have been and continue to invest heavily in data and analytics. But like oil, data and analytics have their dark side. The paper determined the technique not fit for clinical use.
Have you ever asked a data scientist if they wanted their code to run faster? While deep learning is an excellent use of the processing power of a graphics card, it is not the only use. of respondents reported to use CNN’s. You would probably get a more varied response asking if the earth is flat. In fact only 43.2%
Only through hands-on experimentation can we discern truly useful new algorithmic capabilities from hype. These fleshed-out web applications are representative end products of datascience work. There are many uses for interactive applications in the machine learning development lifecycle.
Data organizations don’t always have the budget or schedule required for DataOps when conceived as a top-to-bottom, enterprise-wide transformational change. DataOps can and should be implemented in small steps that complement and build upon existing workflows and data pipelines. Figure 1: The four phases of Lean DataOps. production).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



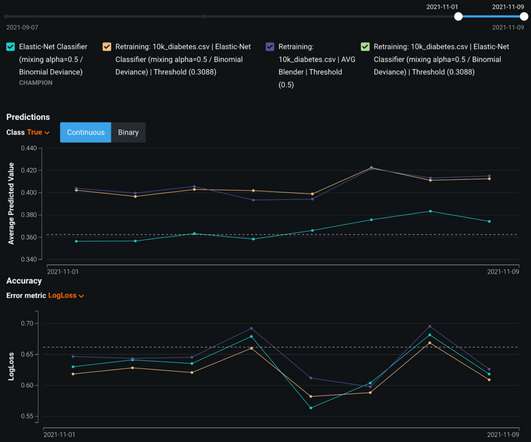














































Let's personalize your content