This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enterprise data is brought into data lakes and data warehouses to carry out analytical, reporting, and datascience use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Table metadata is fetched from AWS Glue. The generated Athena SQL query is run.
Its static snapshot and lack of detailed metadata limit modern applicability. While impressive in volume, it offers minimal metadata and prioritizes click-through rate (CTR) over recommendation logic. However, the data is notoriously sparse, with a steep drop-off in interaction for most users and products.
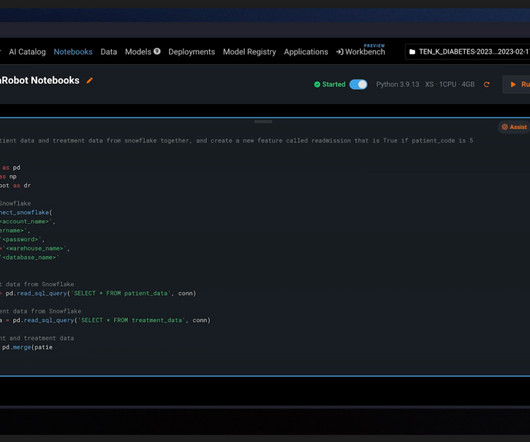
Install them with: pip install pypdf langchain If you want to manage dependencies neatly, create a requirements.txt file with: pypdf langchain requests And run: pip install -r requirements.txt Step 1: Set Up the PDF Parser(parser.py) The core class CustomPDFParser uses PyPDF to extract text and metadata from each PDF page.
mlruns This command uses an SQLite database for metadata storage and saves artifacts in the mlruns directory. This format includes the model and its metadata. Metadata has the models framework, version, and dependencies. Launching the MLFlow UI The MLFlow UI is a web-based tool for visualizing experiments and models.
Preprocessing steps like cleaning formatting, extracting metadata, and creating document summaries improve retrieval accuracy. For example, a marketing content generator that produces blog posts, social media content, and email campaigns based on product information and target audience.
SageMaker Lakehouse enables seamless data access directly in the new SageMaker Unified Studio and provides the flexibility to access and query your data with all Apache Iceberg-compatible tools on a single copy of analytics data. Having confidence in your data is key. The tools to transform your business are here.
They establish quality metrics, set thresholds, and collaborate with upstream systems to identify and address the root causes of data issues. Data Governance Teams: Data Governance professionals employ quality testing as a means to enhance data catalogs with high-quality metadata.
`customer_demographics.sql`: Model for transforming customer demographic data. schema.yml`: YAML file defining metadata, tests, and descriptions for the models in this directory. sources: Contains source configuration files for the raw data sources. stg_customers.sql`: Staging model for transforming raw customer data.
The post My Reflections on the Gartner Hype Cycle for Data Management, 2024 appeared first on Data Management Blog - Data Integration and Modern Data Management Articles, Analysis and Information. Gartner Hype Cycle methodology provides a view of how.
The post Denodo on Deepseek R1: Opportunities & Considerations for GenAI Initiatives appeared first on Data Management Blog - Data Integration and Modern Data Management Articles, Analysis and Information. Denodo applauds the release of Deepseek R1 and the ingenuity.
In addition to big data workloads, Ozone is also fully integrated with authorization and data governance providers namely Apache Ranger & Apache Atlas in the CDP stack. While we walk through the steps one by one from data ingestion to analysis, we will also demonstrate how Ozone can serve as an ‘S3’ compatible object store.
If you include the title of this blog, you were just presented with 13 examples of heteronyms in the preceding paragraphs. This is accomplished through tags, annotations, and metadata (TAM). Smart content includes labeled (tagged, annotated) metadata (TAM). What you have just experienced is a plethora of heteronyms.
These rules are not necessarily “Rocket Science” (despite the name of this blog site), but they are common business sense for most business-disruptive technology implementations in enterprises. Love thy data: data are never perfect, but all the data may produce value, though not immediately.
Reading Time: 3 minutes While cleaning up our archive recently, I found an old article published in 1976 about data dictionary/directory systems (DD/DS). Nowadays, we no longer use the term DD/DS, but “data catalog” or simply “metadata system”. It was written by L.
The domain also includes code that acts upon the data, including tools, pipelines, and other artifacts that drive analytics execution. The domain requires a team that creates/updates/runs the domain, and we can’t forget metadata: catalogs, lineage, test results, processing history, etc., ….
Like the proverbial man looking for his keys under the streetlight , when it comes to enterprise data, if you only look at where the light is already shining, you can end up missing a lot. The data you’ve collected and saved over the years isn’t free. Analyze your metadata. Real-time, cloud-based data ingestion and storage.
Ultimately, there will be an interoperable toolset for running the data team , just like a more focused toolset (ELT/DataScience/BI) for acting upon data. And the tools for acting on data are consolidating: Tableau does data prep, Altreyx does datascience, Qlik joined with Talend, etc.
That is not a totally clear separation and distinction, but it might help to clarify their different applications of datascience. Data scientists work with business users to define and learn the rules by which precursor analytics models produce high-accuracy early warnings.
Traditionally, developing appropriate datascience code and interpreting the results to solve a use-case is manually done by data scientists. The integration allows you to generate intelligent datascience code that reflects your use case. Data scientists still need to review and evaluate these results.
In the previous blog post in this series, we walked through the steps for leveraging Deep Learning in your Cloudera Machine Learning (CML) projects. RAPIDS brings the power of GPU compute to standard DataScience operations, be it exploratory data analysis, feature engineering or model building. Introduction.
Reading Time: 2 minutes As the volume, variety, and velocity of data continue to surge, organizations still struggle to gain meaningful insights. This is where active metadata comes in. Listen to “Why is Active Metadata Management Essential?” What is Active Metadata? ” on Spreaker.
In an earlier blog, I defined a data catalog as “a collection of metadata, combined with data management and search tools, that helps analysts and other data users to find the data that they need, serves as an inventory of available data, and provides information to evaluate fitness data for intended uses.”.
This is a guest blog post co-written with Sumesh M R from Cargotec and Tero Karttunen from Knowit Finland. They chose AWS Glue as their preferred data integration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed.
This is part of our series of blog posts on recent enhancements to Impala. Apache Impala is synonymous with high-performance processing of extremely large datasets, but what if our data isn’t huge? Datascience experiment result and performance analysis, for example, calculating model lift. Metadata Caching.
Execution of this mission requires the contribution of several groups: data center/IT, data engineering, datascience, data visualization, and data governance. Each of the roles mentioned above views the world through a preferred set of tools: Data Center/IT – Servers, storage, software.
Cloudera has been supporting data lakehouse use cases for many years now, using open source engines on open data and table formats, allowing for easy use of data engineering, datascience, data warehousing, and machine learning on the same data, on premises, or in any cloud.
CDP One democratizes insights so companies can achieve faster time to business insights to create data-driven innovation. It is a simple, yet powerful, cloud service that will accelerate datascience programs with built-in enterprise security and machine learning (ML). Accelerated DataScience at CWT.
This includes capturing of the metadata, tracking provenance and documenting the model lifecycle. It drives a complete governance solution without the excessive costs of switching from your current datascience platform. The post AI Governance: Break open the black box appeared first on Journey to AI Blog.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient data analytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. This concept makes Iceberg extremely versatile. SparkActions.get().expireSnapshots(iceTable).expireOlderThan(TimeUnit.DAYS.toMillis(7)).execute()
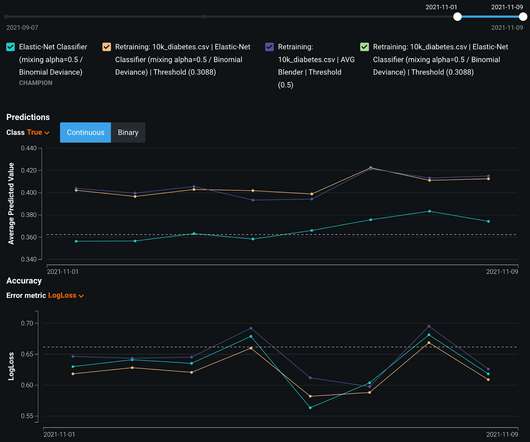
These and many other questions are now on top of the agenda of every datascience team. To quantify how well your models are doing, DataRobot provides you with a comprehensive set of datascience metrics — from the standards (Log Loss, RMSE) to the more specific (SMAPE, Tweedie Deviance). Learn More About DataRobot MLOps.
The data lifecycle model ingests data using Kafka, enriches that data with Spark-based batch process, performs deep data analytics using Hive and Impala, and finally uses that data for datascience using Cloudera DataScience Workbench to get deep insights. on roadmap).
This leads to the obvious question – how do you do data at scale ? Al needs machine learning (ML), ML needs datascience. Datascience needs analytics. And they all need lots of data. And that data is likely in clouds, in data centers and at the edge.
This blog explores the challenges associated with doing such work manually, discusses the benefits of using Pandas Profiling software to automate and standardize the process, and touches on the limitations of such tools in their ability to completely subsume the core tasks required of datascience professionals and statistical researchers.
Domino DataScience Field Notes provide highlights of datascience research, trends, techniques, and more, that support data scientists and datascience leaders accelerate their work or careers. . “In the same spirit as [Recht et al., ” They also were able to.
Cloudera DataScience Workbench (CDSW) makes secure, collaborative datascience at scale a reality for the enterprise and accelerates the delivery of new data products. save the built model container, along with metadata like who built or deployed it. Cloudera DataScience Workbench 1.4.x
Although the oil company has been producing massive amounts of data for a long time, with the rise of new cloud-based technologies and data becoming more and more relevant in business contexts, they needed a way to manage their information at an enterprise level and keep up with the new skills in the data industry.
Amazon’s Open Data Sponsorship Program allows organizations to host free of charge on AWS. Over the last decade, we’ve seen a surge in datascience frameworks coming to fruition, along with mass adoption by the datascience community. Data scientists have access to the Jupyter notebook hosted on SageMaker.
It unifies self-service datascience and data engineering in a single, portable service as part of an enterprise data cloud for multi-function analytics on data anywhere. As for the container labels, you can find more information about this in Metadata for Customer ML Runtime , within Cloudera documentation. .
Typically, on their own, data warehouses can be restricted by high storage costs that limit AI and ML model collaboration and deployments, while data lakes can result in low-performing datascience workloads. New insights and relationships are found in this combination. All of this supports the use of AI.
Gartner defines a data fabric as “a design concept that serves as an integrated layer of data and connecting processes. The data fabric architectural approach can simplify data access in an organization and facilitate self-service data consumption at scale. 2 “Exposing The Data Mesh Blind Side ” Forrester.
With in-place table migration, you can rapidly convert to Iceberg tables since there is no need to regenerate data files. Only metadata will be regenerated. Newly generated metadata will then point to source data files as illustrated in the diagram below. . Data quality using table rollback. Metadata management .
Data Mesh: A type of data platform architecture that embraces the ubiquity of data in the enterprise by leveraging a domain-oriented, self-serve design. A data mesh supports distributed, domain-specific data consumers and views data as a product, with each domain handling its own data pipelines.
Cloudera, a leader in big data analytics, provides a unified Data Platform for data management, AI, and analytics. Our customers run some of the world’s most innovative, largest, and most demanding datascience, data engineering, analytics, and AI use cases, including PB-size generative AI workloads.
Ozone is also highly available — the Ozone metadata is replicated by Apache Ratis, an implementation of the Raft consensus algorithm for high-performance replication. Since Ozone supports both Hadoop FileSystem interface and Amazon S3 interface, frameworks like Apache Spark, YARN, Hive, and Impala can automatically use Ozone to store data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content