This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon Image 1 Introduction In this article, I will use the YouTube Trends database and Python programming language to train a language model that generates text using learning tools, which will be used for the task of making youtube video articles or for your blogs. […].
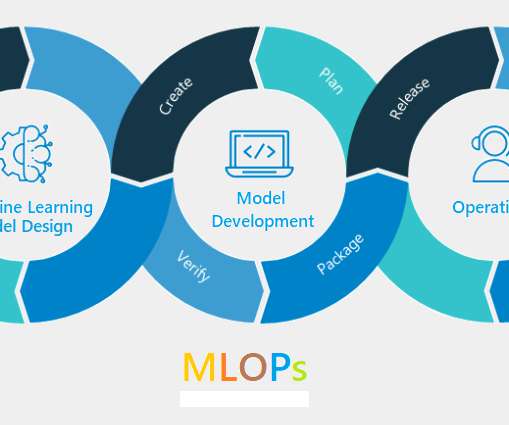
This article was published as a part of the DataScience Blogathon. Introduction This article is part of blog series on Machine Learning Operations(MLOps). In the previous articles, we have gone through the introduction, MLOps pipeline, model training, model testing, model packaging, and model registering.
This article was published as a part of the DataScience Blogathon Dear readers, In this blog, let’s build our own custom CNN(Convolutional Neural Network) model all from scratch by training and testing it with our custom image dataset.
This article was published as a part of the DataScience Blogathon. This is the 2nd blog of the MLOps series. Introduction This article is part of an ongoing blog series on Machine Learning Operations(MLOps). The post Workflow of MLOps: Part 2 | Model Building appeared first on Analytics Vidhya.
Especially if you’re in software development or datascience. A portfolio of your projects, blog posts, and open-source contributions can set you apart from other candidates. With advanced large […] The post 10 Exciting Projects on Large Language Models(LLM) appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Objective In this blog, we will learn how to Fine-tune a Pre-trained BERT model for the Sentiment analysis task. The post Fine-tune BERT Model for Sentiment Analysis in Google Colab appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Overview In this blog, I will be briefly explaining the concepts. The post MLOps – Operationalizing Machine Learning Models in Production appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon In this blog, we’ll go over everything you need to know about Logistic Regression to get started and build a model in Python. The post Guide for building an End-to-End Logistic Regression Model appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Hello There, This blog has an example of an ensemble of. The post Ensemble Deep Learning | An Ensemble of deep learning models! appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction This article is part of an ongoing blog series on. The post Part 14: Step by Step Guide to Master NLP – Basics of Topic Modelling appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Hope you all are doing Good !!! Welcome to my blog! The post Automated Spam E-mail Detection Model(Using common NLP tasks) appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction This article is part of an ongoing blog series on. The post Part 18: Step by Step Guide to Master NLP – Topic Modelling using LDA (Probabilistic Approach) appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction This article is part of an ongoing blog series on. The post Part- 19: Step by Step Guide to Master NLP – Topic Modelling using LDA (Matrix Factorization Approach) appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction This article is part of an ongoing blog series on. The post Part 17: Step by Step Guide to Master NLP – Topic Modelling using pLSA appeared first on Analytics Vidhya.
Introduction Data Scientists have an important role in the modern machine-learning world. Leveraging ML pipelines can save them time, money, and effort and ensure that their models make accurate predictions and insights. This blog will look at the value ML pipelines bring to datascience projects and discuss why they should be adopted.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction This article is part of an ongoing blog series on. The post Part 16 : Step by Step Guide to Master NLP – Topic Modelling using LSA appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Dear readers, In this blog, we will build a random forest classifier(RFClassifier) model to detect breast cancer using this dataset from Kaggle.
Datascience has become an extremely rewarding career choice for people interested in extracting, manipulating, and generating insights out of large volumes of data. To fully leverage the power of datascience, scientists often need to obtain skills in databases, statistical programming tools, and data visualizations.
Apply fair and private models, white-hat and forensic model debugging, and common sense to protect machine learning models from malicious actors. Like many others, I’ve known for some time that machine learning models themselves could pose security risks. This is like a denial-of-service (DOS) attack on your model itself.
Savvy data scientists are already applying artificial intelligence and machine learning to accelerate the scope and scale of data-driven decisions in strategic organizations. These datascience teams are seeing tremendous results—millions of dollars saved, new customers acquired, and new innovations that create a competitive advantage.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction In this blog, we’ll be discussing Ensemble Stacking through theory. The post Ensemble Stacking for Machine Learning and Deep Learning appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction In this blog, let’s explore how to train a state-of-the-art text classifier by using the models and data from the famous HuggingFace Transformers library.
In the multiverse of datascience, the tool options continue to expand and evolve. While there are certainly engineers and scientists who may be entrenched in one camp or another (the R camp vs. Python, for example, or SAS vs. MATLAB), there has been a growing trend towards dispersion of datascience tools.
Introduction The demand for data to feed machine learning models, datascience research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, data pipelines are necessary.
This article was published as a part of the DataScience Blogathon. In our previous blog, we have studied Audio classification using ANN and build a model from scratch. Hello, and welcome to a wonderful article on audio classification. Almost […].
Read the complete blog below for a more detailed description of the vendors and their capabilities. This is not surprising given that DataOps enables enterprise data teams to generate significant business value from their data. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers.
An exploration of three types of errors inherent in all financial models. At Hedged Capital , an AI-first financial trading and advisory firm, we use probabilistic models to trade the financial markets. All financial models are wrong. Clearly, a map will not be able to capture the richness of the terrain it models.
Microsoft has updated the DataScience Certification exam. Those blog posts were for the old exam which focused on the legacy Azure Machine Learning Studio interface and general datascience knowledge. The Microsoft DataScience Certification exam DP 100 has been updated. DP 100 Updated!
Sign Up for the Cloud DataScience Newsletter. Amazon Athena and Aurora add support for ML in SQL Queries You can now invoke Machine Learning models right from your SQL Queries. Amazon AutoML now provides details on all iterations Previously, Amazon’s AutoML only provided details on the best model discovered.
Introduction Join upcoming DataHour sessions for valuable insights and knowledge on data-tech careers. This blog post introduces the series, covering various subjects in datascience and its applications across industries. Who can Attend these Upcoming DataHour Sessions?
In a world focused on buzzword-driven models and algorithms, you’d be forgiven for forgetting about the unreasonable importance of data preparation and quality: your models are only as good as the data you feed them. Why is high-quality and accessible data foundational?
Summary: APIs will get better at transferring model components from one application to another and transferring pipelines to production. If we can crack the nut of enabling a wider workforce to build AI solutions, we can start to realize the promise of datascience. Pretrained models and feature reuse, for example.
Introduction Have you heard of Llama 3, the open-source powerhouse in large language models? This blog will guide you through using Llama […] The post Instantly Access Llama 3 on Groq With These Methods appeared first on Analytics Vidhya. It’s causing quite a stir in the tech community!
Experimentation: It’s just not possible to create a product by building, evaluating, and deploying a single model. In reality, many candidate models (frequently hundreds or even thousands) are created during the development process. Modelling: The model is often misconstrued as the most important component of an AI product.
All models require testing and auditing throughout their deployment and, because models are continually learning, there is always an element of risk that they will drift from their original standards. As such, model governance needs to be applied to each model for as long as it’s being used. What Is Model Governance?
The blog discusses five platforms designed for data scientists with specialized capabilities in managing large datasets, models, workflows, and collaboration beyond what GitHub offers.
Container technology has changed the way datascience gets done. The original container use case for datascience focused on what I call, “environment management”. Configuring software environments is a constant chore, especially in the open source software space, the space in which most data scientists work.
It focuses on building your first model with Azure Machine Learning. See the Course Launch page for blog posts on other courses. The post Building Your First Model with Azure Machine Learning appeared first on DataScience 101. The first course in the Mastering Azure Machine Learning series has launched.
Fitting Prophet models with complex seasonalities for electricity demand forecasting. The entirely custom front-end to one of our prototype applications with a probabilistic model of NPC real estate. These fleshed-out web applications are representative end products of datascience work.
Are you interested in DataScience? This blog will help you kickstart or advance your datascience career. You'll learn about the most popular programming languages data scientists use to clean, analyze, visualize, and modeldata.
If you can’t wait, check out this DataKitchen white paper, Build a Data Mesh Factory with DataOps. Data Teams: A Unified Management Model for Successful Data-Focused Teams, by Jesse Anderson. If your data nerd leads a team of data nerds, big data projects, or aspires to one day, “Data Teams” is the book for them. ??
Citizens expect efficient services, The post Empowering the Public Sector with Data: A New Model for a Modern Age appeared first on Data Management Blog - Data Integration and Modern Data Management Articles, Analysis and Information. In this dynamic environment, time is everything.
Journey Sciences (using graph and linked datamodeling). You can read more details about each of these developments in my MapR blog. Context-based customer engagement through IoT (knowing the knowable via ubiquitous sensors).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















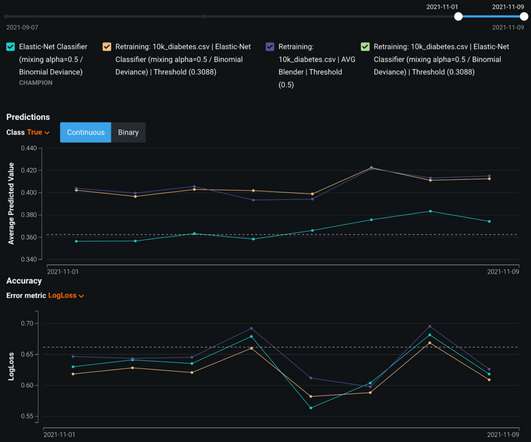






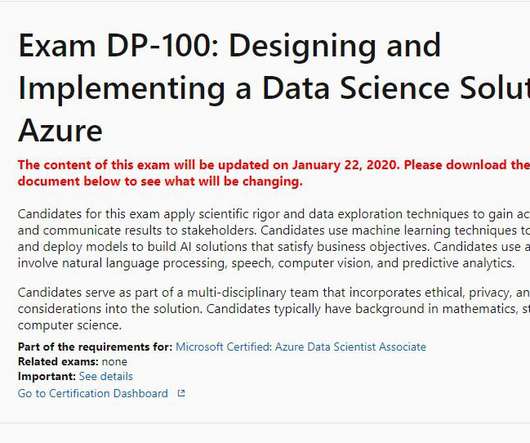























Let's personalize your content