This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data Quality Testing: A Shared Resource for Modern Data Teams In today’s AI-driven landscape, where data is king, every role in the modern data and analytics ecosystem shares one fundamental responsibility: ensuring that incorrect data never reaches business customers.
It must be based on historical data, facts and clear insight into trends and patterns in the market, the competition and customer buying behavior. According to CIO publications, the predictive analytics market was estimated at $12.5 billion USD in 2022 and is expected to reach $38 billion USD by 2028.
People who once understood the data have moved on. AI, predictivemodeling, real-time analyticsnone of these cutting-edge initiatives can succeed without clean, reliable data. But how do you build confidence in the data if you have no context, no SME on speed dial, and no time to write detailed tests?
Datascience has become an extremely rewarding career choice for people interested in extracting, manipulating, and generating insights out of large volumes of data. To fully leverage the power of datascience, scientists often need to obtain skills in databases, statistical programming tools, and data visualizations.
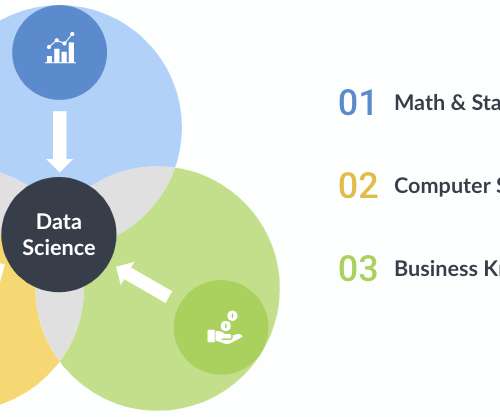
Datascience is an exciting, interdisciplinary field that is revolutionizing the way companies approach every facet of their business. DataScience — A Venn Diagram of Skills. Datascience encapsulates both old and new, traditional and cutting-edge. 3 Components of DataScience Skills.
Why is high-quality and accessible data foundational? The assumed value of data is a myth leading to inflated valuations of start-ups capturing said data. Generating data with a pre-specified analysis plan and running that analysis is good. Re-analyzing existing data is often very bad.”
The objective here is to brainstorm on potential security vulnerabilities and defenses in the context of popular, traditional predictivemodeling systems, such as linear and tree-based models trained on static data sets. If an attacker can receive many predictions from your model API or other endpoint (website, app, etc.),
by THOMAS OLAVSON Thomas leads a team at Google called "Operations DataScience" that helps Google scale its infrastructure capacity optimally. It also owns Google’s internal time series forecasting platform described in an earlier blog post. Our team does a lot of forecasting. Our team does a lot of forecasting.
Hotels try to predict the number of guests they can expect on any given night in order to adjust prices to maximize occupancy and increase revenue. There are plenty of big data examples used in real life, shaping our world, be it in the buying experience or managing customers’ data. And it’s completely free!
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
Citizen Data Scientists Can Use Assisted PredictiveModeling to Create, Share and Collaborate! Gartner has predicted that, ‘40% of datascience tasks will be automated, resulting in increased productivity and broader usage by citizen data scientists.’
This article presents a case study of how DataRobot was able to achieve high accuracy and low cost by actually using techniques learned through DataScience Competitions in the process of solving a DataRobot customer’s problem. Sensor Data Analysis Examples. The Best Way to Achieve Both Accuracy and Cost Control.
Producing insights from raw data is a time-consuming process. Predictivemodeling efforts rely on dataset profiles , whether consisting of summary statistics or descriptive charts. The Importance of Exploratory Analytics in the DataScience Lifecycle. imputation of missing values). ref: [link].
— Snowflake and DataRobot integration capability delivers automated production of clinical and population health datasets and AI risk detection models that accelerate the delivery of real-time predictive insight to clinicians and operational managers wherever it’s needed. Grasping the digital opportunity. Action to take.
Moreover, as most predictive analytics capabilities available today are in their infancy — they have simply not been used for long enough by enough companies on enough sources of data – so the material to build predictivemodels on was quite scarce. Last but not least, there is the human factor again.
While datascience and machine learning are related, they are very different fields. In a nutshell, datascience brings structure to big data while machine learning focuses on learning from the data itself. What is datascience? This post will dive deeper into the nuances of each field.
By combining profound airline operation expertise, datascience, and engine analytics to a predictive maintenance schedule, Lufthansa Technik can now ensure critical parts are on the ground (OTG) when needed, instead of the entire aircraft being OTG and not producing revenue.
In this blog we show what the changes in behavior of data are in high dimensions. In our next blog we discuss how we try to avoid these problems in applied data analysis of high dimensional data. Data Has Properties. Statistics developed in the last century are based on probability models (distributions).
Although the oil company has been producing massive amounts of data for a long time, with the rise of new cloud-based technologies and data becoming more and more relevant in business contexts, they needed a way to manage their information at an enterprise level and keep up with the new skills in the data industry.
To ensure maximum momentum and flawless service the Experian BIS Data Enrichment team decided to use the power of big data by utilizing Cloudera’s DataScience Workbench. The pipeline provides its clinicians fast access to real-time patient data and predictionmodels.
DataScience tools, algorithms, and practices are rapidly evolving to solve business problems on an unprecedented scale. This makes datascience one of the most exciting fields to be in. There are well-known barriers that slow down predictivemodeling or application development.
IBM Automation Decision Services is designed to enable organizations to combine prescriptive business rules with predictivemodels to help them make more informed operational decisions to improve customer experience and make organizations run more effectively.
In Talking Data , we delve into the rapidly evolving worlds of Natural Language Processing and Generation. Text data is proliferating at a staggering rate, and only advanced coding languages like Python and R will be able to pull insights out of these datasets at scale. NLP can be used on written text or speech data.
For data, this refinement includes doing some cleaning and manipulations that provide a better understanding of the information that we are dealing with. In a previous blog , we have covered how Pandas Profiling can supercharge the data exploration required to bring our data into a predictivemodelling phase.
In my previous articles PredictiveModelData Prep: An Art and Science and Data Prep Essentials for Automated Machine Learning, I shared foundational data preparation tips to help you successfully. by Jen Underwood. Read More.
How are you going to turn that data into a solution? There are many paths to consider: Visual representations that reveal patterns in the data and make it more human readable. Predictivemodels to take descriptive data and attempt to tell the future. In particular, data products require more C.L.I.C.
The technology research firm, Gartner has predicted that, ‘predictive and prescriptive analytics will attract 40% of net new enterprise investment in the overall business intelligence and analytics market.’ Access to Flexible, Intuitive PredictiveModeling. Forecasting. Classification. Hypothesis Testing. Correlation.
But Downer envisioned a partnership that would allow them to delve deeper into the data, unearthing more insights that could add value to operations. They combined forces with the experts at IBM to reach toward the expanding horizons of datascience. Downer was able to streamline modeling times with watsonx.ai
Investment in predictive analytics benefits everyone in the organization, including business users and team members, data scientists and the organization in general. Team members can bridge the gap of datascience skills so they don’t have to wait for IT or data scientists to help them produce a report or perform analytics.
Classical statistics, developed in the 20 th century for small datasets, do not work for data where the number of variables is much larger than the number of samples (Large P Small N, Curse of Dimensionality, or P >> N data). Points fall on the outer edges of the data distribution.
We were most interested in exploring if it was possible to predict the return rate on a new product based on historical return rates of products with similar features. Then we ran Kraken’s machine learning and predictivemodeling engine to get the results. It will be iterative.
Data scientist As companies embrace gen AI, they need data scientists to help drive better insights from customer and business data using analytics and AI. For most companies, AI systems rely on large datasets, which require the expertise of data scientists to navigate.
“These tools enable data literacy and digital transformation and increase team productivity and creativity, encouraging power users and those with average technology skills to dive into analytics ad use fact-based decision-making to improve market positioning.”
But while the company is united by purpose, there was a time when its teams were kept apart by a data platform that lacked the scalability and flexibility needed for collaboration and efficiency. Disparate data silos made real-time streaming analytics, datascience, and predictivemodeling nearly impossible.
As the entire Cloudera Data Platform is built on open source projects, we find it crucial to participate in and contribute back to the community. Applied ML Prototypes (AMPs) are fully built end-to-end datascience solutions that allow data scientists to go from an idea to a fully working machine learning model in a fraction of the time.
Use cases could include but are not limited to: optimizing healthcare processes to save lives, data analysis for emergency resource management, building smarter cities with datascience, using data and analytics to fight climate change, tackle the food crisis or prioritize actions against poverty, and more.
World-renowned technology analysis firm Gartner defines the role this way, ‘A citizen data scientist is a person who creates or generates models that leverage predictive or prescriptive analytics, but whose primary job function is outside of the field of statistics and analytics. ‘If Advanced data preparation.
The creation of no-code and low-code apps allows for simple foundations and construction to analyze data without customization or programming or datascience skills supports both developers, data scientists and power users of analytics by providing tools to simply and easily create complex components.
The Citizen Data Scientist phenomenon is in full swing and, while the approach has its detractors, the proof is in success, and many organizations are actively succeeding using the Citizen Data Scientist approach.
In the case of CDP Public Cloud, this includes virtual networking constructs and the data lake as provided by a combination of a Cloudera Shared Data Experience (SDX) and the underlying cloud storage. Each project consists of a declarative series of steps or operations that define the datascience workflow.
Without understanding the shift in workflow, responsibilities and how the use of data will change the enterprise, it is unlikely that the business will succeed in its Citizen Data Scientist initiative.
Smarten has announced the launch of PredictiveModel Mark-Up Language (PMML) Integration capability for its Smarten Augmented Analytics suite of products. Simply create the predictivemodel, using your favorite platform, export the model as a PMML file and import that model to Smarten.
ML is a computer science, datascience and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. AI studio The post Five machine learning types to know appeared first on IBM Blog. What is machine learning? Explore the watsonx.ai
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content