This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As an essential part of ETL, as data is being consolidated, we will notice that data from different sources are structured in different formats. It might be required to enhance, sanitize, and prepare data so that data is fit for consumption by the SQL engine. What is a datatransformation?
The data scientists and IT professionals were starting to get frustrated, when suddenly, a magical fairy appeared out of nowhere. The fairy was carrying a DataOps wand, and she waved it over the messy data, transforming it into a clean and organized dataset.
You can now use your tool of choice, including Tableau, to quickly derive business insights from your data while using standardized definitions and decentralized ownership. Refer to the detailed blog post on how you can use this to connect through various other tools. Get started with our technical documentation.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments.
Its EssentialVerifying DataTransformations (Part4) Uncovering the leading problems in datatransformation workflowsand practical ways to detect and preventthem In Parts 13 of this series of blogs, categories of datatransformations were identified as among the top causes of data quality defects in data pipeline workflows.
Common challenges and practical mitigation strategies for reliable datatransformations. Photo by Mika Baumeister on Unsplash Introduction Datatransformations are important processes in data engineering, enabling organizations to structure, enrich, and integrate data for analytics , reporting, and operational decision-making.
Managing tests of complex datatransformations when automated data testing tools lack important features? Photo by Marvin Meyer on Unsplash Introduction Datatransformations are at the core of modern business intelligence, blending and converting disparate datasets into coherent, reliable outputs.
When we announced the GA of Cloudera Data Engineering back in September of last year, a key vision we had was to simplify the automation of datatransformation pipelines at scale. Typically users need to ingest data, transform it into optimal format with quality checks, and optimize querying of the data by visual analytics tool.
Building a Data Culture Within a Finance Department. Our finance users tell us that their first exposure to the Alation Data Catalog often comes soon after the launch of organization-wide datatransformation efforts. After all, finance is one of the greatest consumers of data within a business.
This means there are no unintended data errors, and it corresponds to its appropriate designation (e.g., Here, it all comes down to the datatransformation error rate. Data time-to-value: evaluates how long it takes you to gain insights from a data set. date, month, and year).
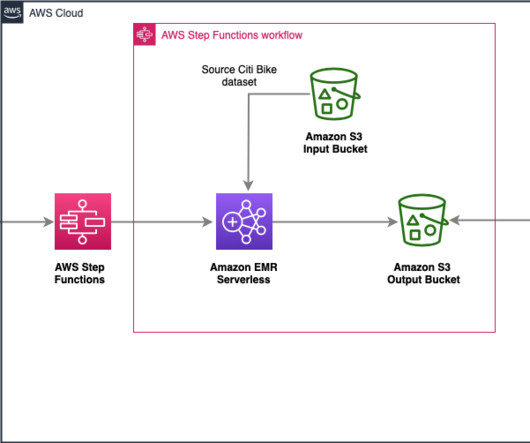
Prerequisites Before you get started, make sure you have the following prerequisites: An AWS account An IAM user with administrator access An S3 bucket Solution Architecture To automate the complete process, we use the following architecture, which integrates Step Functions for orchestration and Amazon EMR Serverless for datatransformations.
DataOps establishes a process hub that automates data production and analytics development workflows so that the data team is more efficient, innovative and less prone to error. In this blog, we’ll explore the role of the DataOps Engineer in driving the data organization to higher levels of productivity.
Use our 14-days free trial today & transform your supply chain! Welcome To The Future Of Logistics We’re on the cusp of big datatransforming the nature of logistics. Big data in logistics can improve financial efficiency, provide transparency to the supply chain, and enable proactive strategic decision-making.
Once the connection is established with the success message, you now view your project’s subscribed data directly within Tableau and build dashboards. See the Amazon DataZone and Tableau blog post for step-by-step instructions. Joel has led datatransformation projects on fraud analytics, claims automation, and Master Data Management.
With the ability to browse metadata, you can understand the structure and schema of the data source, identify relevant tables and fields, and discover useful data assets you may not be aware of.
This allows data analysts and data scientists to rapidly construct the necessary data preparation steps to meet their business needs. We use the new data preparation authoring capabilities to create recipes that meet our specific business needs for datatransformations. For Data format , select Parquet.
Open the secret blog-glue-snowflake-credentials. For AWS Secret , choose the secret blog-glue-snowflake-credentials. For IAM Role , choose the role that has access to the target S3 location where the job is writing to and the source location from where it’s loading the Snowflake data and also to run the AWS Glue job.
This blog post dives into the strategic considerations and steps involved in migrating from Solr to OpenSearch. For the updateRequestProcessorChain , OpenSearch provides the ingest pipeline , allowing the enrichment or transformation of data before indexing. Migration from Solr to OpenSearch is becoming a common pattern.
Airflow has been adopted by many Cloudera Data Platform (CDP) customers in the public cloud as the next generation orchestration service to setup and operationalize complex data pipelines. The post Introducing Self-Service, No-Code Airflow Authoring UI in Cloudera Data Engineering appeared first on Cloudera Blog.
Here are a few examples that we have seen of how this can be done: Batch ETL with Azure Data Factory and Azure Databricks: In this pattern, Azure Data Factory is used to orchestrate and schedule batch ETL processes. Azure Blob Storage serves as the data lake to store raw data. Azure Machine Learning).
This blog post is co-written with James Sun from Snowflake. Customers rely on data from different sources such as mobile applications, clickstream events from websites, historical data, and more to deduce meaningful patterns to optimize their products, services, and processes. Choose Airflow version 2.6.3. Choose Next.
There are countless examples of big datatransforming many different industries. There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. This is something that you can learn more about in just about any technology blog.
We’re excited to announce the general availability of the open source adapters for dbt for all the engines in CDP — Apache Hive , Apache Impala , and Apache Spark, with added support for Apache Livy and Cloudera Data Engineering. The Open Data Lakehouse . Cloudera builds dbt adaptors for all engines in the open data lakehouse.
Through this series of blog posts, we’ll discuss how to best scale and branch out an analytics solution using a knowledge graph technology stack. For the use case that this blog will explore, we have picked a perfect blend of the exciting and the fairly boring – building compliance. How to make sense of all that? But with robots.
GSK’s DataOps journey paralleled their datatransformation journey. GSK has been in the process of investing in and building out its data and analytics capabilities and shifting the R&D organization to a software engineering mindset.
Your data strategy, evolving amid lessons and advances, now helps underpin that command, accelerating your agency’s trajectory right through the inevitable speed bumps. . Learn how we can help you power public sector datatransformation.
In the second blog of the Universal Data Distribution blog series , we explored how Cloudera DataFlow for the Public Cloud (CDF-PC) can help you implement use cases like data lakehouse and data warehouse ingest, cybersecurity, and log optimization, as well as IoT and streaming data collection.
The DataOps Engineering skillset includes hybrid and cloud platforms, orchestration, data architecture, data integration, datatransformation, CI/CD, real-time messaging, and containers. The capabilities unlocked by DataOps impacts everyone that uses data analytics — all the way to the top levels of the organization.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible datatransforms in Python and SQL. dbt is predominantly used by data warehouses (such as Amazon Redshift ) customers who are looking to keep their datatransform logic separate from storage and engine.
If you have ever built your own custom GraphQL API layer, the code typically resolves each part of a GraphQL query as it traverses downwards as a separate isolated data fetching step. This leads to lots of small data fetches to/from GraphDB over the network. Custom code also tends to over-fetch data that is not required.
By leveraging Hive to apply Ranger FGAC, Spark obtains secure access to the data in a protected staging area. Since Spark has direct access to the staged data, any Spark APIs can be used, from complex datatransformations to data science and machine learning. . so stay tuned! .
Data holds incredible untapped potential for Australian organisations across industries, regardless of individual business goals, and all organisations are at different points in their datatransformation journey with some achieving success faster than others. .
cd /home/ec2-user/SageMaker BASE_S3_PATH="s3://aws-blogs-artifacts-public/artifacts/BDB-4265" aws s3 cp "${BASE_S3_PATH}/0_create_tables_with_metadata.ipynb"./ Under Actions , choose Open Jupyter Navigate to Jupyter console, select New , and then choose Console. aws s3 cp "${BASE_S3_PATH}/1_text_to_sql_for_athena.ipynb"./
This will take at least two blog posts to cover, but I will summarize them here: Compare data load & transformations with CSV files vs a Fabric lakehouse using the SQL Server connector: Loading 20 million fact rows from CSV files vs a Fabric lakehouse, using Power Query. Same comparison with deployed Power BI model.
In our last three blogs, we covered how Dataiku’s visual flow can help enhance collaboration and visibility, differences in how you work with datasets , and one of the key tools to accelerate datatransformations: recipes. Welcome back to part four of the Alteryx to Dataiku series!
Predict – Data Engineering (Apache Spark). CDP Data Engineering (1) – a service purpose-built for data engineers focused on deploying and orchestrating datatransformation using Spark at scale. 3) Data Visualization is in Tech Preview on AWS and Azure. New Services.
This is a guest blog post co-written with SangSu Park and JaeHong Ahn from SOCAR. As companies continue to expand their digital footprint, the importance of real-time data processing and analysis cannot be overstated. The following diagram shows an example of datatransformations in the handler component.
Continuing from my previous blog post about how awesome and easy it is to develop web-based applications backed by Cloudera Operational Database (COD), I started a small project to integrate COD with another CDP cloud experience, Cloudera Machine Learning (CML). . b) Basic datatransformation. Go to runner.py and run it.
This enabled new use-cases with customers that were using a mix of Spark and Hive to perform datatransformations. . Along with delivering the world’s first true hybrid data cloud, stay tuned for product announcements that will drive even more business value with innovative data ops and engineering capabilities.
This integration empowers developers and data scientists alike with advanced capabilities for code completion, generation, and troubleshooting. Whether you’re tackling datatransformation challenges or refining intricate machine learning models, our Copilot is designed to be your reliable partner in innovation.
Solutions to Reign in the Chaos Implementing Data Observability Platforms: Tools like DataKitchen’s DataOps Observability provide an overarching view of the entire Data Journey. They enable continuous monitoring of datatransformations and integrations, offering invaluable insights into data lineage and changes.
We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways data teams are tackling the challenges of this new world to help their companies and their customers thrive.
ELT tools such as IBM® DataStage® facilitate fast and secure transformations through parallel processing engines. In 2023, the average enterprise receives hundreds of disparate data streams, making efficient and accurate datatransformations crucial for traditional and new AI model development.
With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized data catalog. It enables you to visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your data lakes. Select Visual ETL in the central pane.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content