This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
Enterprise data is brought into data lakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Run the following Shell script commands in the console to copy the Jupyter Notebooks.
In the beginning, CDP ran only on AWS with a set of services that supported a handful of use cases and workload types: CDP DataWarehouse: a kubernetes-based service that allows business analysts to deploy datawarehouses with secure, self-service access to enterprise data. That Was Then. New Services.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible datatransforms in Python and SQL. dbt is predominantly used by datawarehouses (such as Amazon Redshift ) customers who are looking to keep their datatransform logic separate from storage and engine.
Data operations (or data production) is a series of pipeline procedures that take raw data, progress through a series of processing and transformation steps, and output finished products in the form of dashboards, predictions, datawarehouses or whatever the business requires. Their product is the data.
There are countless examples of big datatransforming many different industries. There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. This is something that you can learn more about in just about any technology blog.
With quality data at their disposal, organizations can form datawarehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. Here, it all comes down to the datatransformation error rate.
We’re excited to announce the general availability of the open source adapters for dbt for all the engines in CDP — Apache Hive , Apache Impala , and Apache Spark, with added support for Apache Livy and Cloudera Data Engineering. The Open Data Lakehouse . Cloudera builds dbt adaptors for all engines in the open data lakehouse.
The general availability covers Iceberg running within some of the key data services in CDP, including Cloudera DataWarehouse ( CDW ), Cloudera Data Engineering ( CDE ), and Cloudera Machine Learning ( CML ). Cloudera Data Engineering (Spark 3) with Airflow enabled. Cloudera Machine Learning .
It is comprised of commodity cloud object storage, open data and open table formats, and high-performance open-source query engines. To help organizations scale AI workloads, we recently announced IBM watsonx.data , a data store built on an open data lakehouse architecture and part of the watsonx AI and data platform.
Amazon AppFlow , a fully managed data integration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery. Architecture Let’s review the architecture to transfer data from Google BigQuery to Amazon S3 using Amazon AppFlow.
Azure Synapse Analytics Pipelines: Azure Synapse Analytics (formerly SQL DataWarehouse) provides data exploration, data preparation, data management, and data warehousing capabilities. It provides data prep, management, and enterprise data warehousing tools. It does the job.
Cloudera users can securely connect Rill to a source of event stream data, such as Cloudera DataFlow , model data into Rill’s cloud-based Druid service, and share live operational dashboards within minutes via Rill’s interactive metrics dashboard or any connected BI solution. Cloudera DataWarehouse). Apache Hive.
With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized data catalog. It enables you to visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your data lakes. Select Visual ETL in the central pane.
In our latest demo, we highlight how we’re piloting a modern analytic solution using Snowflake’s scalable cloud datawarehouse in combination with Matillion and ThoughtSpot, through Snowflake’s Partner Connect service offering. Creation of a dynamic report, allowing users to drill down on a 360-degree searchable dashboard.
These tools empower analysts and data scientists to easily collaborate on the same data, with their choice of tools and analytic engines. No more lock-in, unnecessary datatransformations, or data movement across tools and clouds just to extract insights out of the data.
In the second blog of the Universal Data Distribution blog series , we explored how Cloudera DataFlow for the Public Cloud (CDF-PC) can help you implement use cases like data lakehouse and datawarehouse ingest, cybersecurity, and log optimization, as well as IoT and streaming data collection.
However, our legacy datawarehouse-based solution was not equipped for this challenge. However, with a minimum data freshness of 10 minutes, this architecture inherently didn’t align with the near real-time fraud detection use case.
Datatransforms businesses. That’s where the data lifecycle comes into play. Managing data and its flow, from the edge to the cloud, is one of the most important tasks in the process of gaining data intelligence. . The firm also worked on creating a solid pipeline from the datawarehouse to the data lake.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
In legacy analytical systems such as enterprise datawarehouses, the scalability challenges of a system were primarily associated with computational scalability, i.e., the ability of a data platform to handle larger volumes of data in an agile and cost-efficient way. Introduction.
AWS Glue , a serverless data integration and extract, transform, and load (ETL) service, has revolutionized this process, making it more accessible and efficient. AWS Glue eliminates complexities and costs, allowing organizations to perform data integration tasks in minutes, boosting efficiency.
Provision resources with AWS CloudFormation For the initial setup, you launch an AWS CloudFormation stack to create an S3 bucket to store data, IAM roles for data access, and the AWS Glue crawler and Data Catalog components. This will enable both the CDC steps and the datatransformation steps for the Jira data.
As we review datatransformation and modernization strategies with our clients, we find many are investigating Snowflake as a datawarehouse solution due to its ease of use, speed, and increased flexibility over a traditional datawarehouse offering.
How to scale AL and ML with built-in governance A fit-for-purpose data store built on an open lakehouse architecture allows you to scale AI and ML while providing built-in governance tools. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and business intelligence.
You can’t talk about data analytics without talking about data modeling. The reasons for this are simple: Before you can start analyzing data, huge datasets like data lakes must be modeled or transformed to be usable. This design philosophy was adapted from our friends at Fishtown Analytics.).
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of datawarehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. Amazon Redshift enables you to run complex SQL analytics at scale and performance on terabytes to petabytes of structured and unstructured data, and make the insights widely available through popular business intelligence (BI) and analytics tools.
This was, without a question, a significant departure from traditional analytic environments, which often meant vendor-lock in and the inability to work with data at scale. Another unexpected challenge was the introduction of Spark as a processing framework for big data.
In this blog, I will cover: What is watsonx.ai? Capabilities within the Prompt Lab include: Summarize: Transform text with domain-specific content into personalized overviews and capture key points (e.g., It is supported by querying, governance, and open data formats to access and share data across the hybrid cloud.
In Gartner’s Top 10 Data and Analytics Trends for 2021, trend No. Advanced datatransformation with Custom Code. With enhanced live model connection parameters, you can now leverage one live data model for multiple customers who use the same schema structure in your datawarehouse.
Datatransformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset.
As Cussatt put it, “datatransformation isn’t about the IT, but about enabling the mission to be able to serve the veterans.” Enterprise cloud offerings such as Cloudera DataWarehouse (CDW), a solution to evolving beyond shadow IT, deliver a hybrid cloud, multifunction data platform that centrally integrates information. .
The datawarehouse and analytical data stores moved to the cloud and disaggregated into the data mesh. Today, the brightest minds in our industry are targeting the massive proliferation of data volumes and the accompanying but hard-to-find value locked within all that data. Subscribe to Alation's Blog.
Attempting to learn more about the role of big data (here taken to datasets of high volume, velocity, and variety) within business intelligence today, can sometimes create more confusion than it alleviates, as vital terms are used interchangeably instead of distinctly.
Data analysts and engineers use dbt to transform, test, and document data in the cloud datawarehouse. Yet every dbt transformation contains vital metadata that is not captured – until now. DataTransformation in the Modern Data Stack. How did the datatransform exactly?
Apache Hudi is an open source transactional data lake framework that greatly simplifies incremental data processing and the development of data pipelines. Besides demonstrating with Hudi here, we will follow up with other OTF tables with other blogs. For Stack name , enter a stack name (for example, rsv2-emr-hudi-blog ).
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This datatransformation tool enables data analysts and engineers to transform, test and document data in the cloud datawarehouse. Curious to learn how the data catalog can power your data strategy?
Organizations have spent a lot of time and money trying to harmonize data across diverse platforms , including cleansing, uploading metadata, converting code, defining business glossaries, tracking datatransformations and so on. And there’s control of that landscape to facilitate insight and collaboration and limit risk.
. With Db2 Warehouse’s fully managed cloud deployment on AWS, enjoy no overhead, indexing, or tuning and automated maintenance. Whether it’s for ad hoc analytics, datatransformation, data sharing, data lake modernization or ML and gen AI, you have the flexibility to choose.
This solution decouples the ETL and analytics workloads from our transactional data source Amazon Aurora, and uses Amazon Redshift as the datawarehouse solution to build a data mart. We use Amazon Redshift as the datawarehouse to implement the data mart solution. Under Transforms , choose SQL Query.
For many organizations, a centralized data platform will fall short as it gives data teams much less autonomy over managing increasingly diverse and voluminous datasets. A centralized data engineering team focuses on building a governed self-serviced infrastructure, while domain teams use the services to build full-stack data products.
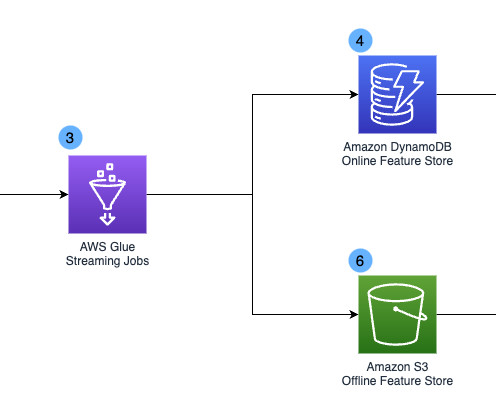
Data ingestion – Steps 1 and 2 use AWS DMS, which connects to the source database and moves full and incremental data (CDC) to Amazon S3 in Parquet format. Datatransformation – Steps 3 and 4 represent an EMR Serverless Spark application (Amazon EMR 6.9 For Name , enter emr-delta-blog. For Type , choose Spark.
Get hands-on experience with the data cloud. Gain experience and understanding of how to drive better business decisions with your data. Our fifth video will demonstrate datatransformation and orchestration with Matillion into Snowflake. Learn about current trends.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content