This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments.
Common challenges and practical mitigation strategies for reliable datatransformations. Photo by Mika Baumeister on Unsplash Introduction Datatransformations are important processes in data engineering, enabling organizations to structure, enrich, and integrate data for analytics , reporting, and operational decision-making.
Managing tests of complex datatransformations when automated datatesting tools lack important features? Photo by Marvin Meyer on Unsplash Introduction Datatransformations are at the core of modern business intelligence, blending and converting disparate datasets into coherent, reliable outputs.
Amazon DataZone recently announced the expansion of data analysis and visualization options for your project-subscribed data within Amazon DataZone using the Amazon Athena JDBC driver. Refer to the detailed blog post on how you can use this to connect through various other tools. Get started with our technical documentation.
With this launch of JDBC connectivity, Amazon DataZone expands its support for data users, including analysts and scientists, allowing them to work in their preferred environments—whether it’s SQL Workbench, Domino, or Amazon-native solutions—while ensuring secure, governed access within Amazon DataZone. Choose Test connection.
Its EssentialVerifying DataTransformations (Part4) Uncovering the leading problems in datatransformation workflowsand practical ways to detect and preventthem In Parts 13 of this series of blogs, categories of datatransformations were identified as among the top causes of data quality defects in data pipeline workflows.
DataOps establishes a process hub that automates data production and analytics development workflows so that the data team is more efficient, innovative and less prone to error. In this blog, we’ll explore the role of the DataOps Engineer in driving the data organization to higher levels of productivity. Create tests.
GSK had been pursuing DataOps capabilities such as automation, containerization, automated testing and monitoring, and reusability, for several years. DataOps provides the “continuous delivery equivalent for Machine Learning and enables teams to manage the complexities around continuous training, A/B testing, and deploying without downtime.
Your Chance: Want to test a professional logistics analytics software? Use our 14-days free trial today & transform your supply chain! Your Chance: Want to test a professional logistics analytics software? Use our 14-days free trial today & transform your supply chain! Now’s the time to strike.
Also known as data validation, integrity refers to the structural testing of data to ensure that the data complies with procedures. This means there are no unintended data errors, and it corresponds to its appropriate designation (e.g., Here, it all comes down to the datatransformation error rate.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and testdata sources. This approach simplifies your data journey and helps you meet your security requirements.
Here are a few examples that we have seen of how this can be done: Batch ETL with Azure Data Factory and Azure Databricks: In this pattern, Azure Data Factory is used to orchestrate and schedule batch ETL processes. Azure Blob Storage serves as the data lake to store raw data. Azure Machine Learning).
Extrinsic Control Deficit: Many of these changes stem from tools and processes beyond the immediate control of the data team. Unregulated ETL/ELT Processes: The absence of stringent data quality tests in ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) processes further exacerbates the problem.
DataOps Observability can help you ensure that your complex data pipelines and processes are accurate and that they deliver as designed. Observability also validates that your datatransformations, models, and reports are performing as expected. to monitor your data operations. without replacing staff or systems?to
We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways data teams are tackling the challenges of this new world to help their companies and their customers thrive. Data integrity: A process and a state.
This blog post dives into the strategic considerations and steps involved in migrating from Solr to OpenSearch. For example, the following creates a collection called test with one shard and no replicas. Multiple processor stages can be chained to form a pipeline for datatransformation.
DataOps Engineers implement the continuous deployment of data analytics. They give data scientists tools to instantiate development sandboxes on demand. They automate the data operations pipeline and create platforms used to test and monitor data from ingestion to published charts and graphs.
We’re excited to announce the general availability of the open source adapters for dbt for all the engines in CDP — Apache Hive , Apache Impala , and Apache Spark, with added support for Apache Livy and Cloudera Data Engineering. This variety can result in a lack of standardization, leading to data duplication and inconsistency.
Developers need to onboard new data sources, chain multiple datatransformation steps together, and explore data as it travels through the flow. This allows developers to make changes to their processing logic on the fly while running some testdata through their flow and validating that their changes work as intended.
Airflow has been adopted by many Cloudera Data Platform (CDP) customers in the public cloud as the next generation orchestration service to setup and operationalize complex data pipelines. With this Technical Preview release, any CDE customer can test drive the new authoring interface by setting up the latest CDE service.
DataOps Observability can help you ensure that your complex data pipelines and processes are accurate and that they deliver as designed. Observability also validates that your datatransformations, models, and reports are performing as expected. to monitor your data operations. without replacing staff or systems?to
The goal of DataOps Observability is to provide visibility of every journey that data takes from source to customer value across every tool, environment, data store, data and analytic team, and customer so that problems are detected, localized and raised immediately. A data journey spans and tracks multiple pipelines.
We just announced the general availability of Cloudera DataFlow Designer , bringing self-service data flow development to all CDP Public Cloud customers. In our previous DataFlow Designer blog post , we introduced you to the new user interface and highlighted its key capabilities.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible datatransforms in Python and SQL. dbt is predominantly used by data warehouses (such as Amazon Redshift ) customers who are looking to keep their datatransform logic separate from storage and engine.
This blog post is co-written with James Sun from Snowflake. Customers rely on data from different sources such as mobile applications, clickstream events from websites, historical data, and more to deduce meaningful patterns to optimize their products, services, and processes. Provide a name of your choice for the environment.
Predict – Data Engineering (Apache Spark). CDP Data Engineering (1) – a service purpose-built for data engineers focused on deploying and orchestrating datatransformation using Spark at scale. 3) Data Visualization is in Tech Preview on AWS and Azure. New Services.
This enabled new use-cases with customers that were using a mix of Spark and Hive to perform datatransformations. . Along with delivering the world’s first true hybrid data cloud, stay tuned for product announcements that will drive even more business value with innovative data ops and engineering capabilities.
This integration empowers developers and data scientists alike with advanced capabilities for code completion, generation, and troubleshooting. Whether you’re tackling datatransformation challenges or refining intricate machine learning models, our Copilot is designed to be your reliable partner in innovation.
Modak Nabu relies on a framework of “Botworks”, a series of micro-jobs to accomplish various datatransformation steps from ingestion to profiling, and indexing. Cloudera Data Engineering within CDP provides : Fully managed Spark-on-Kubernetes service that hides the complexity running production DE workloads at scale.
Continuing from my previous blog post about how awesome and easy it is to develop web-based applications backed by Cloudera Operational Database (COD), I started a small project to integrate COD with another CDP cloud experience, Cloudera Machine Learning (CML). . Now, let’s start testing our model! b) Basic datatransformation.
Be sure test cases represent the diversity of app users. As an AI product manager, here are some important data-related questions you should ask yourself: What is the problem you’re trying to solve? What datatransformations are needed from your data scientists to prepare the data? The perfect fit.
cd /home/ec2-user/SageMaker BASE_S3_PATH="s3://aws-blogs-artifacts-public/artifacts/BDB-4265" aws s3 cp "${BASE_S3_PATH}/0_create_tables_with_metadata.ipynb"./ Prompt with no metadata For the first test, we used a basic prompt containing just the SQL generating instructions and no table metadata.
Datatransforms businesses. That’s where the data lifecycle comes into play. Managing data and its flow, from the edge to the cloud, is one of the most important tasks in the process of gaining data intelligence. . The post Connecting the Data Lifecycle appeared first on Cloudera Blog.
The general availability covers Iceberg running within some of the key data services in CDP, including Cloudera Data Warehouse ( CDW ), Cloudera Data Engineering ( CDE ), and Cloudera Machine Learning ( CML ). In this first blog, we shared with you how to use Apache Iceberg in Cloudera Data Platform to build an open lakehouse.
These tools empower analysts and data scientists to easily collaborate on the same data, with their choice of tools and analytic engines. No more lock-in, unnecessary datatransformations, or data movement across tools and clouds just to extract insights out of the data.
Cloudera Data Warehouse). Efficient batch data processing. Complex datatransformations. Together Cloudera and Rill Data are dedicated to building and maintaining the data infrastructure that best supports our customers with cost-performant queries, resilience, and distributed real-time metrics. .
The Test and Development queue have fixed resource limits. YuniKorn, thus empowers Apache Spark to become an enterprise-grade essential platform for users, offering a robust platform for a variety of applications ranging from large scale datatransformation to analytics to machine learning. Acknowledgments.
Detailed Data and Model Lineage Tracking*: Ensures comprehensive tracking and documentation of datatransformations and model lifecycle events, enhancing reproducibility and auditability. The post Deploy and Scale AI Applications With Cloudera AI Inference Service appeared first on Cloudera Blog.
Jessicamouth 2964 Queensland Load the dataset First, create a new table in your Redshift Serverless endpoint and copy the testdata into it by doing the following: Open the Query Editor V2 and log in using the admin user name and details defined when the endpoint was created.
As we review datatransformation and modernization strategies with our clients, we find many are investigating Snowflake as a data warehouse solution due to its ease of use, speed, and increased flexibility over a traditional data warehouse offering. Validate and test through the entire migration. Sirius can help.
In perhaps a preview of things to come next year, we decided to test how a Data Catalog might work with Tableau on the same data. You can check out a self service data prep flow from catalog to viz in this recorded version here. Rita Sallam Introduces the Data Prep Rodeo. Subscribe to Alation's Blog.
To accomplish this interchange, the method uses data mining and machine learning and it contains components like a data dictionary to define the fields used by the model, and datatransformation to map user data and make it easier for the system to mine that data. Simple interpretation of models in English.
Datatransformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset.
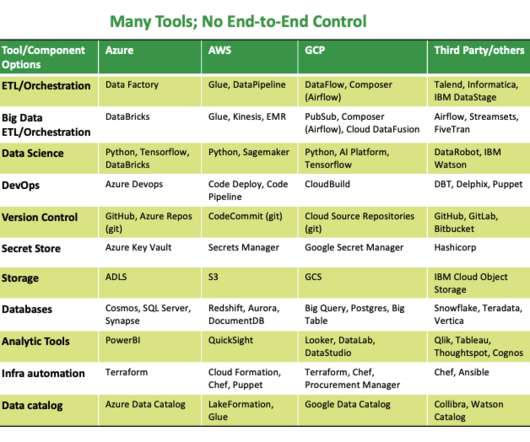
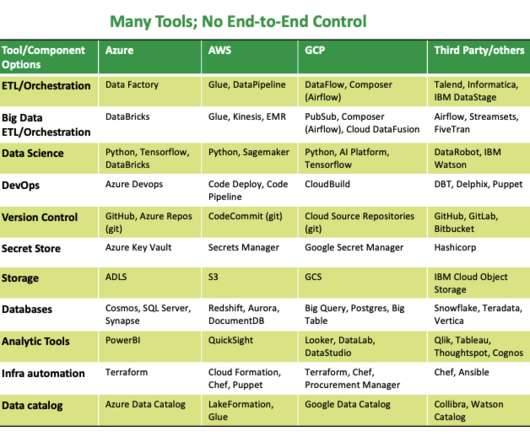
Building a data-driven business includes choosing the right software and implementing best practices around its use. Every year when budget time rolls around, many organizations find themselves asking the same question: “what are we going to do about our data?” This is a summary article. New year, same questions.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content