This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Other organizations are just discovering how to apply AI to accelerate experimentation time frames and find the best models to produce results. Bureau of Labor Statistics predicts that the employment of data scientists will grow 36 percent by 2031, 1 much faster than the average for all occupations. Read the blog. Read the blog.
This post is a primer on the delightful world of testing and experimentation (A/B, Multivariate, and a new term from me: Experience Testing). Experimentation and testing help us figure out we are wrong, quickly and repeatedly and if you think about it that is a great thing for our customers, and for our employers. Counter claims?
— Thank you to Ann Emery, Depict Data Studio, and her Simple Spreadsheets class for inviting us to talk to them about the use of statistics in nonprofit program evaluation! But then we realized that much of the time, statistics just don’t have much of a role in nonprofit work. Why Nonprofits Shouldn’t Use Statistics.
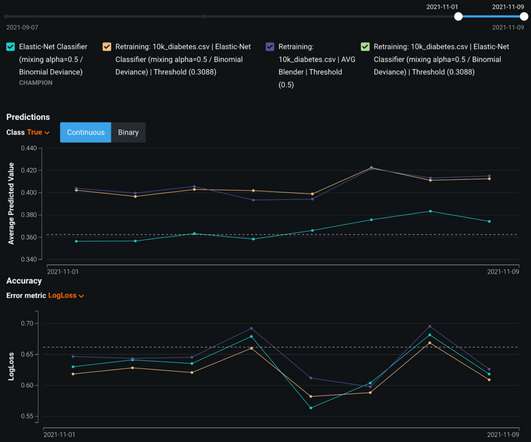
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. This blog post discusses such a comprehensive approach that is used at Youtube. Indeed, such an approach is tractable and often used.
For example, imagine a fantasy football site is considering displaying advanced player statistics. A ramp-up strategy may mitigate the risk of upsetting the site’s loyal users who perhaps have strong preferences for the current statistics that are shown. One reason to do ramp-up is to mitigate the risk of never before seen arms.
Some of that uncertainty is the result of statistical inference, i.e., using a finite sample of observations for estimation. But there are other kinds of uncertainty, at least as important, that are not statistical in nature. Among these, only statistical uncertainty has formal recognition.
Update: This blog post is overwhelmingly for those who want to become Analysts ("Business" in the matrix above). So in addition to becoming good at Omniture, Google Analytics, Baidu Analytics , pick one other tool from the Experimentation, Voice of Customer, Competitive Intelligence buckets of Web Analytics 2.0. Pick two blogs.
This is an example of Simpon’s paradox , a statistical phenomenon in which a trend that is present when data is put into groups reverses or disappears when the data is combined. It’s time to introduce a new statistical term. Everyone wants to get more out of their data, but how exactly to do that can leave you scratching your head.
Common elements of DataOps strategies include: Collaboration between data managers, developers and consumers A development environment conducive to experimentation Rapid deployment and iteration Automated testing Very low error rates. Issue detected?
In every Apache Flink release, there are exciting new experimental features. You can find valuable statistics you can’t normally find elsewhere, including the Apache Flink Dashboard. You can find more details about recent releases from the Apache Flink blog and release notes: Amazon Managed Service for Apache Flink 1.19
And it can look up an author and make statistical observations about their interests. ChatGPT offers users a paid account that costs $20/month, which is good enough for experimenters, though there is a limit on the number of requests you can make. Personal conversation, though he may also have said this in his blog.
Not actually being a machine learning problem: Value-at-Risk modeling is the classic example here—VaR isn’t a prediction of anything, it’s a statistical summation of simulation results. As discussed, we massively accelerate that process of experimentation.
In this blog post, we would like to present some examples of actual cases in which noise reduction had a significant effect in real-world applications, and in which powerful features were obtained. The first baseline model we created used spectrograms of speech waveform data, statistical features, and spectrogram images.
” Given the statistics—82% of surveyed respondents in a 2023 Statista study cited managing cloud spend as a significant challenge—it’s a legitimate concern. Teams are comfortable with experimentation and skilled in using data to inform business decisions.
Machine learning projects are inherently different from traditional IT projects in that they are significantly more heuristic and experimental, requiring skills spanning multiple domains, including statistical analysis, data analysis and application development. Four Options for Integrating Machine Learning with IoT.
Advanced Data Discovery ensures data democratization by enabling users to drastically reduce the time and cost of analysis and experimentation. Plug n’ Play Predictive Analysis enables business users to explore power of predictive analytics without indepth understanding of statistics and data science.
As a statistical model, LLM inherently is random. Experimentation is important, but be explicit when you do. So, we’ve learned our lesson. AI will solve it We’ve seen a massive increase in interest in LLMs and ‘AI’ But LLM without guide rails could lead to unbridled hallucinations. Start with “why?”
But what if users don't immediately uptake the new experimental version? This blog post provides details for how we can make inferences without waiting for complete uptake. This blog post provides details for how we can make inferences without waiting for complete uptake. What if their uptake rate is not uniform?
It has been such an amazing journey to write the book, and for it to come up almost exactly a year after I started this blog. Experimentation & Testing (A/B, Multivariate, you name it). The book, like this blog, rips up that definition and provides a expanded and more realistic business focused world view. There I said it.
Experimentation on networks A/B testing is a standard method of measuring the effect of changes by randomizing samples into different treatment groups. However, the downside of using a larger unit of randomization is that we lose experimental power. This simulation is based on the actual user network of GCP.
This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. Data Exploration and Innovation: The flexibility of Presto has encouraged data exploration and experimentation at Uber. Enterprise Management Associates (EMA).
This blog post explores how this problem arises in applications at Google, and how we can 'mind our units' through analysis and logging. To figure this out, let's consider an appropriate experimental design. In other words, the teacher is our second kind of unit, the unit of experimentation. However, this is not always the case.
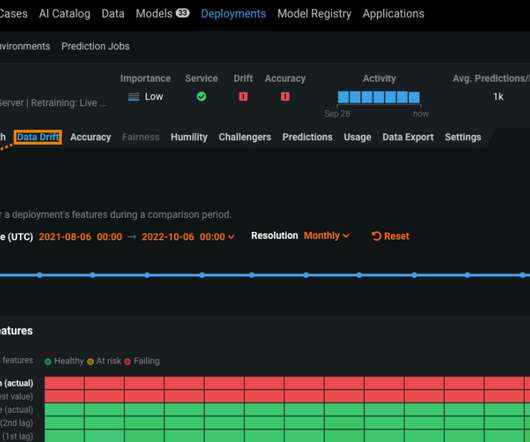
You might think that overall, the model’s features drifted relatively little in production, but in reality, the model’s drift statistics might be fluctuating quite a bit up and down. Prior to using DataRobot, the customer was conducting tedious experimentation to track and investigate drift patterns.
Strip plots in the flesh: NPR looks at school funding The LA Times on pop music’s evolution Eurostat’s key European statistics Jittered Strip Plot. Choosing the right number of bins can have an impact on how any of these charts look, but a bit of experimentation usually leads to a reasonable answer. SUBSCRIBE TO OUR BLOG.
In an ideal world, experimentation through randomization of the treatment assignment allows the identification and consistent estimation of causal effects. Identification We now discuss formally the statistical problem of causal inference. We start by describing the problem using standard statistical notation.
How can he make it easy to see statistics, and do calculations, on discovered commonalities, across structured and unstructured data? It would enable faster experimentation with easy, protected, and governed access to a variety of data. Stay tuned for the next blog post that will dive deeper into this topic!
LLMs like ChatGPT are trained on massive amounts of text data, allowing them to recognize patterns and statistical relationships within language. Meet watsonx Explore AI topics The post Getting ready for artificial general intelligence with examples appeared first on IBM Blog.
A geo experiment is an experiment where the experimental units are defined by geographic regions. Statistical power is traditionally given in terms of a probability function, but often a more intuitive way of describing power is by stating the expected precision of our estimates. They are non-overlapping geo-targetable regions.
We’re not going to engage in this debate but in this blog post we do focus on science. It is important to make clear distinctions among each of these, and to advance the state of knowledge through concerted observation, modeling and experimentation. Note also that this account does not involve ambiguity due to statistical uncertainty.
On this blog, you’ve seen numerous attempts by me to remedy the dilemma. Ignore the metrics produced as an experimental exercise nine months ago. The dilemma of how to simplify this complexity, to create sighted business and analytics leaders, has lingered with me for quite some time.
Technical environments and IDEs must be disposable so that experimental costs can be kept to a minimum. Quality must be monitored continuously to catch unexpected variation cases and produce statistics on its operation. Subscribe to Alation's Blog. Disposable environments. Simplicity. Analytics is manufacturing. Author Bio.
Nimit Mehta: I think that 2024 is going to be a buckle-down year, but, at the same time, we’ll see a rapid explosion of experimentation. These are not statistical inferences. So, this is a big driver for the outcome because when you are saving money for the business, you can measure it and see its value. What is a customer?
Since you're reading a blog on advanced analytics, I'm going to assume that you have been exposed to the magical and amazing awesomeness of experimentation and testing. And yet, chances are you really don’t know anyone directly who uses experimentation as a part of their regular business practice. Wah wah wah waaah.
Recall from my previous blog post that all financial models are at the mercy of the Trinity of Errors , namely: errors in model specifications, errors in model parameter estimates, and errors resulting from the failure of a model to adapt to structural changes in its environment. The interval [-a, a] is called a 90% confidence interval.
1]" Statistics, as a discipline, was largely developed in a small data world. More people than ever are using statistical analysis packages and dashboards, explicitly or more often implicitly, to develop and test hypotheses. Data was expensive to gather, and therefore decisions to collect data were generally well-considered.
by MICHAEL FORTE Large-scale live experimentation is a big part of online product development. In fact, this blog has published posts on this very topic. This means a small and growing product has to use experimentation differently and very carefully. This blog post is about experimentation in this regime.
Here you'll find all my blog posts categorized into a structure that will hopefully make it easy for you to discover new content, find answers to your questions, or simply wallow in some excellent analytics narratives. Blogging Experience Articles. + Podcast: Measuring Rich Media (Ajax, Flash / Flex, RSS & Blogs).
You've probably seen these rules sneak into my blog posts. With 55k RSS Subscribers and 110k Visits a month, this blog could make a few dollars with AdSense or Display ads or annoying interstitials offers. I've talked about the long tail on this blog, especially in context for Search. Via incredible daily utility.
Part of it is fueled by a vocal minority genuinely upset that 10 years on we are still not a statistically powered bunch doing complicated analysis that is shifting paradigms. In this blog post let me share with you some ground truths from my own humble experience. Part of it fueled by some Consultants. Don't fall for the FUD.
Unlike experimentation in some other areas, LSOS experiments present a surprising challenge to statisticians — even though we operate in the realm of “big data”, the statistical uncertainty in our experiments can be substantial. We must therefore maintain statistical rigor in quantifying experimental uncertainty.
Finale Doshi-Velez, Been Kim (2017-02-28) ; see also the Domino blog article about TCAV. They also require advanced skills in statistics, experimental design, causal inference, and so on – more than most data science teams will have. Use of influence functions goes back to the 1970s in robust statistics. 2018-06-21).
Like this blog, the newsletter is geared towards being instantly actionable (rather than just theory-smart, which is pretty cool too). Hypothesis development and design of experimentation. Ok, maybe statistical modeling smells like an analytical skill. Pattern recognition and understanding trends. Strategic thinking skills.
In this post we explore why some standard statistical techniques to reduce variance are often ineffective in this “data-rich, information-poor” realm. Despite a very large number of experimental units, the experiments conducted by LSOS cannot presume statistical significance of all effects they deem practically significant.
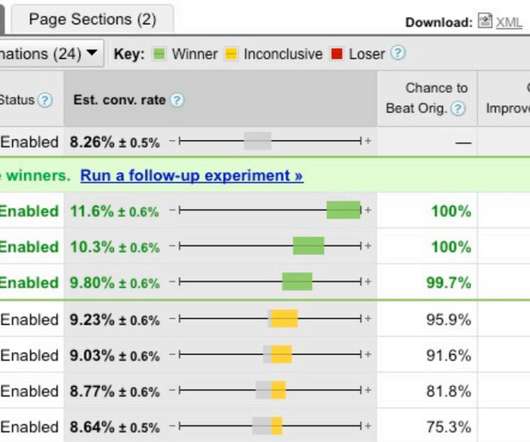
I mean developing and inserting a subtle collection of gentle nudges that can help increase the conversion rate by a statistically significant amount. Yes, that additional $6 mil is not as hard to accomplished for an imaginative focused team – in fact you can get that from implementing half of the recommendations in this blog post.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content