This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In traditional software engineering, precedent has been established for the transition of responsibility from development teams to maintenance, user operations, and site reliability teams. New features in an existing product often follow a similar progression.
This raw, historical archive is essential for traceability and allows data engineers to load new data into the lakehouse incrementally through batch uploads or real-time streaming. The Medallion architecture offers several benefits, making it an attractive choice for data engineering teams.
A recent flourish of posts and papers has outlined the broader topic, listed attack vectors and vulnerabilities, started to propose defensive solutions, and provided the necessary framework for this post. Inversion can also be an example of an “exploratory reverse-engineering” attack. they can train their own surrogate model.
DataOps involves collaboration between data engineers, data scientists, and IT operations teams to create a more efficient and effective data pipeline, from the collection of raw data to the delivery of insights and results. Query> Why have data teams not historically adopted DataOps?
Business intelligence is moving away from the traditional engineering model: analysis, design, construction, testing, and implementation. To fully utilize agile business analytics, we will go through a basic agile framework in regards to BI implementation and management. Agile Business Intelligence & Analytics Methodology.
Yet, among all this, one area that hasn’t been studied is the data engineering role. We thought it would be interesting to look at how data engineers are doing under these circumstances. We surveyed 600 data engineers , including 100 managers, to understand how they are faring and feeling about the work that they are doing.
By providing a standardized framework for data representation, open table formats break down data silos, enhance data quality, and accelerate analytics at scale. Iceberg implements features such as table versioning and concurrency control through the lineage of these snapshots. These are useful for flexible data lifecycle management.
This is part of our series of blog posts on recent enhancements to Impala. We’ll discuss the architecture and features of Impala that enable low latencies on small queries and share some practical tips on how to understand the performance of your queries. Impala is architected to be the Speed-of-Thought query engine for your data.
Amazon EMR provides a big data environment for data processing, interactive analysis, and machine learning using open source frameworks such as Apache Spark, Apache Hive, and Presto. cd /home/ec2-user/SageMaker BASE_S3_PATH="s3://aws-blogs-artifacts-public/artifacts/BDB-4265" aws s3 cp "${BASE_S3_PATH}/0_create_tables_with_metadata.ipynb"./
Engineered to be the “Swiss Army Knife” of data development, these processes prepare your organization to face the challenges of digital age data, wherever and whenever they appear. Through the 5 pillars that we just presented above, we also covered some techniques and tips that should be followed to ensure a successful process.
4) Product Metrics Framework. As a PM, collecting information about your product performance, its features, the market adoption, etc., A common technique to break down the different types of key product metrics is using the AARRR framework , coined by venture capitalist Dave McClure. Table of Contents. is essential.
It adds tables to compute engines including Spark, Trino, PrestoDB, Flink, and Hive using a high-performance table format that works just like a SQL table. Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback. AWS Glue 3.0
This Domino Data Science Field Note covers a proposed definition of interpretability and distilled overview of the PDR framework. Yet, despite the complexity (or because of it), data scientists and researchers curate and use different languages, tools, packages, techniques, and frameworks to tackle the problem they are trying to solve.
AMPs enable data scientists to go from an idea to a fully working ML use case in a fraction of the time, with an end-to-end framework for building, deploying, and monitoring business-ready ML applications instantly. . The work of a machine learning model developer is highly complex. Built By Experts At The Leading Edge Of ML innovation.
Generative Adversarial Network (GAN) This machine learning framework consists of two neural networks competing for a win or for the best result. Combining techniques can reduce costs, while delivering appropriate performance, efficiency and accuracy. It uses a large volume of data and parameters to train the model.
In a recent blog, Cloudera Chief Technology Officer Ram Venkatesh described the evolution of a data lakehouse, as well as the benefits of using an open data lakehouse, especially the open Cloudera Data Platform (CDP). Analytical engines can be scaled up (or down) on demand, as per the requirements of your workload.
Enabling users with features and capabilities to make them better in their job. Is the sales team in place to understand the product, the target audience and establish the sales framework for pushing the product? In a recent blog post , we described the differences between customer reporting and data products.
This authority extends across realms such as business intelligence, data engineering, and machine learning thus limiting the tools and capabilities that can be used. A solution based on Apache Iceberg encompasses complete data management, featuring simple built-in table optimization capabilities within an existing storage solution.
By identifying these changes, the query engine can optimize the query to process only the relevant data, significantly reducing the processing time and resource requirements. Apache Hudi is an open source transactional data lake framework that greatly simplifies incremental data processing and the development of data pipelines.
Ethical hackers may also provide malware analysis, risk assessment, and other hacking tools and techniques to fix security weaknesses rather than cause harm. The red team simulates a real attackers’ tactics, techniques and procedures (TTPs) against the organization’s own system as a way to assess security risk.
Use case overview AnyCompany Travel and Hospitality wanted to build a data processing framework to seamlessly ingest and process data coming from operational databases (used by reservation and booking systems) in a data lake before applying machine learning (ML) techniques to provide a personalized experience to its users.
With only about 35% of machine learning models making into production in the enterprise ( IDC ), it’s no wonder that production machine learning has become one of the most important focus areas for data scientists and ML engineers alike. They can take many forms from Python-based rest APIs to R scripts to distributed frameworks like SparkML.
The US Environmentally-Extended Input-Output (USEEIO) is a lifecycle assessment (LCA) framework that traces economic and environmental flows of goods and services within the United States. This framework helps streamline and simplify the process for businesses to calculate Scope 3 emissions.
Addressing the Key Mandates of a Modern Model Risk Management Framework (MRM) When Leveraging Machine Learning . Given this context, how can financial institutions reap the benefits of modern machine learning approaches, while still being compliant to their MRM framework?
It also owns Google’s internal time series forecasting platform described in an earlier blog post. But even here, a greater concern is the time invested by data scientists (mostly at the development stage) in data analysis and cleaning, featureengineering, and model development. Our team does a lot of forecasting.
Machine Learning and AI provide powerful predictive engines that rely on historical data to fit the models. I am optimistic that what we’ll see over the next 5 years is a mass acceleration and adoption of simulation techniques that complement the continuing innovation in the Machine Learning space. .
They can have a lot of different features, mainly being a customizable interface, a certain level of interactivity as well as the possibility to pull data in real-time from multiple sources. Analytical: This type of dashboard is engineered to provide detailed data analyses pertaining to data trends (the what, the why, the how).
Generative AI uses advanced machine learning algorithms and techniques to analyze patterns and build statistical models. The quality of outputs depends heavily on training data, adjusting the model’s parameters and prompt engineering, so responsible data sourcing and bias mitigation are crucial. Garbage in, garbage out.
Yehoshua I've covered this topic in detail in this blog post: Multi-Channel Attribution: Definitions, Models and a Reality Check. Attribution modeling is a feature available only in Google Analytics Premium, a paid version. A Framework For Critical Thinking.
This blog series demystifies enterprise generative AI (gen AI) for business and technology leaders. It provides simple frameworks and guiding principles for your transformative artificial intelligence (AI) journey. In the previous blog , we discussed the differentiated approach by IBM to delivering enterprise-grade models.
In this blog, we provide a few examples that show how organizations put deep learning to work. Deep learning is a proven technique and a key driver for digital transformation. Users can download and experiment with the latest libraries and frameworks in customizable settings, and easily share projects with peers. Deeplearning4j.
I’ve previously discussed the risk of shadow data (those data stores you didn’t even know you had), and the team specifically dove into how versioning (a feature used to protect from accidental deletion) can unintentionally create shadow data. In this case, the engineer may want to create a data dump to use for testing.
In this post, we recount how we approached the task, describing initial stakeholder needs, the business and engineering contexts in which the challenge arose, and theoretical and pragmatic choices we made to implement our solution. The demand for time series forecasting at Google grew rapidly along with the company over its first decade.
Gartner states that “By 2022, 75% of new end-user solutions leveraging machine learning (ML) and AI techniques will be built with commercial instead of open source platforms” ¹. Learn more about the Cloudera Data Science Workbench for the end-to-end ML workflow at our bi-weekly webinar series featuring live expert demos and Q&A.
The cloud data lakehouse brings multiple processing engines (SQL, Spark, and others) and modern analytical tools (ML, data engineering, and business intelligence) together in a unified analytical environment. Consider this practice the most important function and foundation of your cloud security framework.
By interacting with Tableau’s features to re-label data columns and build derived metrics, Tableau users were effectively documenting and modeling data on their own, often without realizing it. As teams work with Kylo, it captures the basic, technical metadata in the core source foundational framework.
– In the webinar and Leadership Vision deck for Data and Analytics we called out AI engineering as a big trend. Can you remind where we can find the mentioned blog? So much hype compares electric vehicles to traditional engines. Can you provide a link to your blog, or will we get notice of your info posted through email?
Data scientists, analysts and ML engineers may move from one project to another, or they may leave the organization while new team members are brought on board. The Develop stage is where data scientists build and assess models based on a variety of different modeling techniques. Develop Stage. Deploy Stage. MLOps in the DSLC.
Once migration is complete, it’s important that your data scientists and engineers have the tools to search, assemble, and manipulate data sources through the following techniques and tools. A technique to automate changes in iterative passes. A technique to automate changes in iterative passes. Parametrization.
The RDF4J framework, and, by extension, GraphDB, offers a smart approach to this. At the lowest level, to the engine, there’s no difference between “data” and “SHACL shapes” — it’s all triples. Most data engineers are not Java developers. And besides Smaug, we have 1,000 other dragons.
Overall foundational pillars of the AWS security framework include the following: Compliance: AWS provides a range of compliance certifications and attestations that are relevant to the life sciences industry, including HIPAA, HITRUST and GxP. Data protection and privacy: Each AWS customer maintains ownership of their own data.
In a recent blog, Cloudera Chief Technology Officer Ram Venkatesh described the evolution of a data lakehouse, as well as the benefits of using an open data lakehouse, especially the open Cloudera Data Platform (CDP). Analytical engines can be scaled up (or down) on demand, as per the requirements of your workload.
This blog recaps Miner & Kasch ’s first Maryland Data Science Conference hosted at UMBC and dives into the Deep Learning on Imagery and Text talk presented by Florian Muellerklein and Bryan Wilkinson. Introduction. The conference was not without hiccups. You can see a complete list of talks see here. Deep Learning on Imagery and Text.
They should do this by integrating mitigation techniques and policies, such as monitoring, patching, and vulnerability reporting. This danger looms greater than ever today thanks to machine learning techniques that are fundamentally changing the way software is made. Developing a better world.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












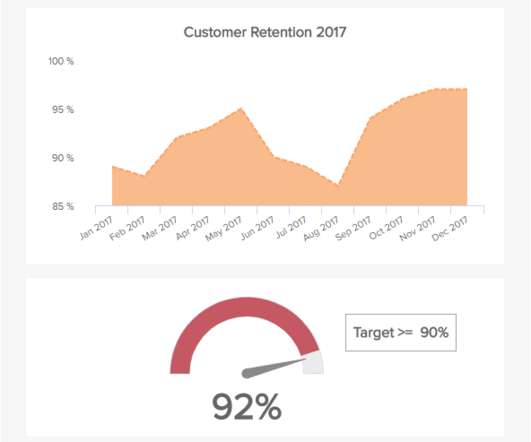











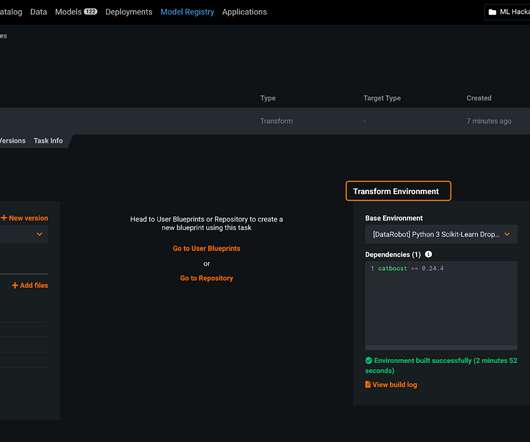












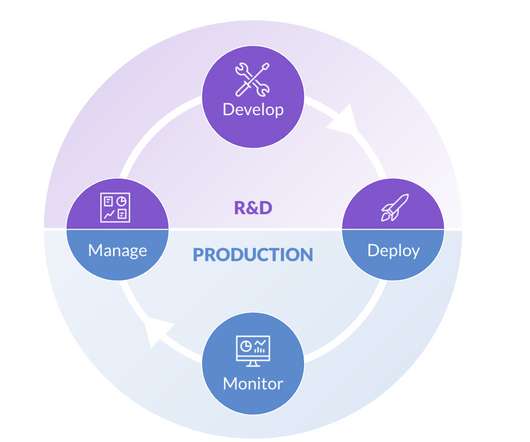














Let's personalize your content