This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In this blog post, we will explore the Decoder-Only Transformer architecture, which is a variation of the Transformer model primarily used for tasks like language translation and text generation.
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. In this blog, we will […] The post How to Implement a Data Pipeline Using Amazon Web Services?
I first learned about Emmanuel through articles on his blog. ) You need to collect relevant data for training, and deploy pipelines that will feed data to the model when it is in production. When I first met Emmanuel, three or four years ago, what impressed me wasn’t his expertise in building models—though he clearly had that.
Blogs Podcasts Whitepapers and Guides Tools and Calculators Webinars Sample Reports The Evolution of the CFO into the Chief Data Storyteller View Insight Now Our Favorite CFO Blogs The Venture CFO Blog Link: [link] Are you looking for blog posts for CFOs by CFOs? Then you have come to the right place.
COVID-19 is a huge data story in many ways, and food delivery analytics are a big part of that. Online food ordering in 2020 hit $115 billion globally and could reach nearly $127 billion in 2021 according to an April 2021 report.
In a world focused on buzzword-driven models and algorithms, you’d be forgiven for forgetting about the unreasonable importance of data preparation and quality: your models are only as good as the data you feed them. By Wansink’s own admission in the blog post, that’s not what happened in his lab.”
There’s a long history of language about moving data: we have had dataflow architectures, there's a great blog on visualization titled FlowingData , and Amazon Web Services has a service for moving data by the (literal) truckload. The data that’s flowing isn’t just the feed to the marketing contractor. Data flows can be very complex.
Figure 2: Data feeding the drug product lifecycle domains. The data engineer updates the Recipe (orchestration) that feeds the data lake if a data source needs to be added and modifies the Recipe that generates the data warehouse. Some data sets are used by multiple teams, but that introduces complexity. The new Recipes run, and BOOM!
Figure 2: During the product launch, data comes from various sources and feeds into regular and ad hoc reports and analytics. Visit our blog, Accelerating Drug Discovery and Development with DataOps. As figure 2 summarizes, the data team ingests data from hundreds of internal and third-party sources. It’s that simple. .
You can find my results on my Medium blog site. Oh, by the way, I asked the generative AI at Stable Diffusion to create some images to go with my short story (which you can find on my Medium blog ). LLMs are so responsive and grammatically correct (even over many paragraphs of text) that some people worry that it is sentient.
Artificial Intelligence requires feeding accurate information through a set of algorithms so a machine can make future decisions. It eliminates the requirement for feeding new codes every time we want them to learn a new thing. Visit our blog to find more information. If programmed well, computers do not make errors like humans.
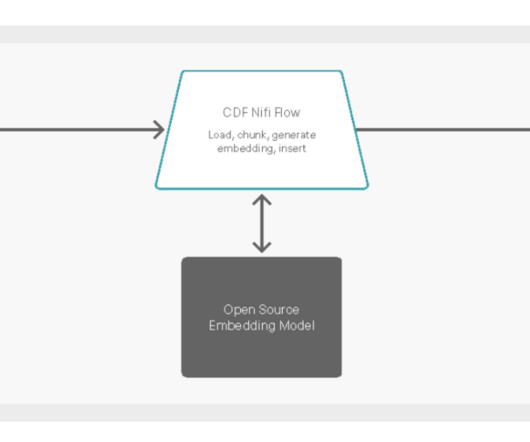
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. Introduction. Metadata Management: In legacy implementations, changes to Data Products (e.g., A Client Example.
jar,s3://blogpost-sparkoneks-us-east-1/blog/BLOG_TPCDS-TEST-3T-partitioned/, /home/hadoop/tpcds-kit/tools,parquet,3000,true, ,true,true],ActionOnFailure=CONTINUE --region Note the Hadoop catalog warehouse location and database name from the preceding step. For example, the following code uses an EMR 7.5 impl=org.apache.iceberg.aws.s3.S3FileIO,
You can share things like; Videos Blog posts Infographics Useful content from other brands Team photos. New visitors are going to check out your feed to see what you have been sharing. There are actually new machine learning tools that will create blog posts. Share a link on your Facebook on your Twitter feed.
As Dan Moore writes in his “ Letters to a new Developer ” blog, “Even as a new developer, you’re constantly making small creative decisions (naming a variable, for example). It is also the aspect most often neglected in the care and feeding of developers. This is part of what makes software development so fulfilling and fun.”
This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs. The Bronze layer is the initial landing zone for all incoming raw data, capturing it in its unprocessed, original form.
Blogs to Read as a CFO. Are you looking for blog posts for CFOs by CFOs? His blog talks about his experiences as a CFO and gives perspective from both start-up and mature companies. As such, it should come as no surprise that they have a blog tailored to CFOs. Whitepapers and Guides. Tools and Calculators. Sample Reports.
Data observability supports our ability to develop and keep data AI-ready Whether youre scaling up an AI practice within your organization or just getting started with your data and AI strategy, monitoring and observing the data pipelines that will feed your AI models should be among your top priorities.
In this three-part blog series, we will outline key elements of our state-of-the-art CDE service – covering motivations (in Part 1), key capabilities (in Part 2), and a step-by-step how-to-guide (in Part 3). Integration with ISV solutions via CDE APIs (latest partner integration blog here.
In a previous blog of this series, Turning Streams Into Data Products , we talked about the increased need for reducing the latency between data generation/ingestion and producing analytical results and insights from this data. This blog will be published in two parts. This is what we call the first-mile problem. The use case.
By feeding this unstructured data into an LLM, the institution can generate personalized financial advice, improve customer service, and detect potentially fraudulent activities. By feeding enterprise data into GenAI models, businesses can create highly contextual and relevant outputs.
Data ingestion monitoring, a critical aspect of Data Observability, plays a pivotal role by providing continuous updates and ensuring high-quality data feeds into your systems.
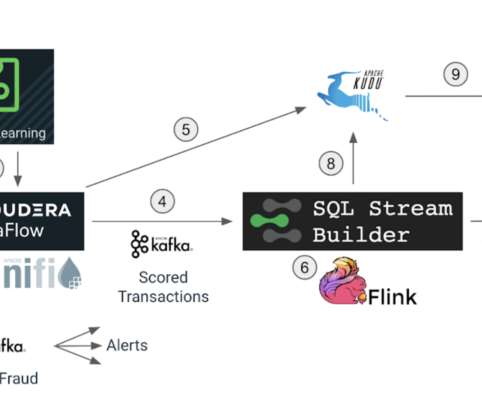
In part 1 of this blog we discussed how Cloudera DataFlow for the Public Cloud (CDF-PC), the universal data distribution service powered by Apache NiFi, can make it easy to acquire data from wherever it originates and move it efficiently to make it available to other applications in a streaming fashion. Use case recap. Apache Flink.
Set up an S3 bucket for full and CDC load data feeds To set up your S3 bucket, complete the following steps: Log in to your AWS account and choose a Region nearest to you. Make sure the name is unique (for example, delta-lake-cdc-blog- ). Give the role a name (for example, delta-lake-cdc-blog-role ). Choose Create role.
This ensures that the right, trusted data is able to be used to feed AI and analytics effectively. The post Laying the Foundation for Modern Data Architecture appeared first on Cloudera Blog. Modern data architectures deliver key functionality in terms of flexibility and scalability of data management.
Validation testing is a safeguard, ensuring that the data feeding into LLMs is of the highest quality. Feeding this unstructured data into LLMs without proper contextualization risks creating noise instead of clarity. Conclusion The journey toward deploying effective and reliable LLMs is challenging but offers significant rewards.
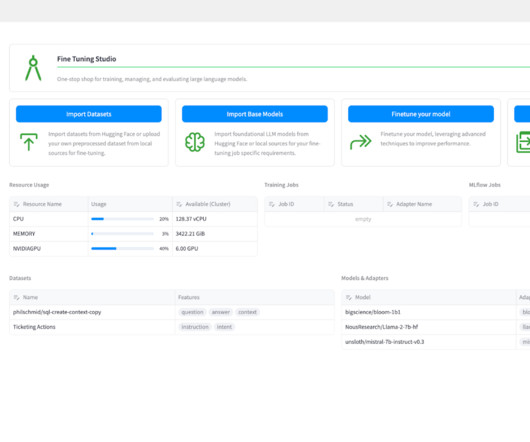
Fine Tuning Studio ships with powerful prompt templating features, so users can build and test the performance of different prompts to feed into different models and model adapters during training. The post Introducing Cloudera Fine Tuning Studio for Training, Evaluating, and Deploying LLMs with Cloudera AI appeared first on Cloudera Blog.
You should have an incredibly amazing blog for your company (more on this below). In addition to that they have amazing content like what you'll see at Patagonia Surfing , and they have a regularly updated awesome blog The Cleanest Line and so much more. Finally, I''ve never accepted ads on this blog. incredible 2.
This blog lays out some steps to help you incrementally advance efforts to be a more data-driven, customer-centric organization. Streaming market data, news feeds, or sending a budget alert can be introduced to a service without a complete overhaul. Data-fuelled innovation requires a pragmatic strategy. Embrace incremental progress.
Here, Cloudera Data Flow is leveraged to build a streaming pipeline which enables the collection, movement, curation, and augmentation of raw data feeds. These feeds are then enriched using external data sources (e.g., The post How a modern data platform supports government fraud detection appeared first on Cloudera Blog.
There are many ways to achieve scale in AI and machine learning (ML) — scale up, scale out, elastic scale. But taking a more granular approach to scaling your AI/ML projects can pay dividends. The best way to understand scale for an AI and ML platform is to look at each step in the lifecycle of a project.
The post Harness the Power of Pinecone with Cloudera’s New Applied Machine Learning Prototype appeared first on Cloudera Blog. We invite you to explore the improved functionalities of this latest AMP.
And this doesn’t even touch on the data generated by citizen services interfaces, machine or device-generated data such as video feeds, sensors, and communications data. The purpose of this blog isn’t to emphasize the cyber risk of dark data but to spotlight its implications. The list could go on and on.
In this blog post, we’ll discuss a few simple but highly effective ways to have a healthier relationship with social media. You’ll be amazed at how much more productive you’ll be when you’re not mindlessly scrolling through your feed for hours on end. Keep reading to learn more!
Why data monetization matters According to McKinsey in the Harvard Business Review , a single data product at a national US bank feeds 60 use cases in business applications, which eliminated $40M in losses and generates $60M incremental revenue annually.
By using AWS Glue to integrate data from Snowflake, Amazon S3, and SaaS applications, organizations can unlock new opportunities in generative artificial intelligence (AI) , machine learning (ML) , business intelligence (BI) , and self-service analytics or feed data to underlying applications. Open the secret blog-glue-snowflake-credentials.
This is part 4 in this blog series. This blog series follows the manufacturing and operations data lifecycle stages of an electric car manufacturer – typically experienced in large, data-driven manufacturing companies. The second blog dealt with creating and managing Data Enrichment pipelines. Here are the key stages: .
Among other shifting trends, we saw just how much the approach to data management is shifting, with data strategies moving to account for the data that feeds AI use cases and ultimately makes them trustworthy, and successful. The post A Look Back at the Gartner Data and Analytics Summit appeared first on Cloudera Blog.
James, thank you for the opportunity to guest blog in your series on Decision Optimization. For each scenario, a range of different decision strategies are automatically created, using techniques such as the global tree optimization approach James discussed in his last blog. A Guest Post by Neill Crossley, ACIB.
That means the text you feed into the model is going to be reduced to arrays of numbers, and those numbers are going to be as a vector on a map, albeit one with thousands of dimensions. As Dale Markowitz wrote on the Google Cloud blog, “If you’d like to embed text–i.e. to do text search or similarity search on text–you’re in luck.
Over the last 18 months, supply chain issues have dominated our nightly news, social feeds and family conversations at the dinner table. Enterprise data from external sources (IoT devices, video feeds, beacon and location devices at the edge) provide overwhelming insight, but it is recognized the data from the edge is not risk free.
Up to this point, authoritative DNS providers have approached this challenge in one of two ways: Overwhelm network teams with data Several authoritative DNS providers offer raw data feeds as an add-on feature. DNS Insights is a targeted data feed drawn from a wide variety of DNS and network metrics.
Participants can choose from the following categories for their prototype: Climate Smart Agriculture: With the world’s population expected to hit nearly 10 billion by 2050, finding sustainable ways to feed all of these people is critical for addressing global hunger as well as mitigating the climate crisis.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content