This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Additionally, multiple copies of the same data locked in proprietary systems contribute to version control issues, redundancies, staleness, and management headaches. It leverages knowledge graphs to keep track of all the data sources and data flows, using AI to fill the gaps so you have the most comprehensive metadatamanagement solution.
Managingmetadata across tools and teams is a growing challenge for organizations building modern data and AI platforms. Teams use Collibra to curate business context, classify sensitive data, and manage access to information in line with compliance requirements. This post was co-written with Vasiliki Nikolopoulou from Collibra.
It helps you track, manage, and deploy models. It helps you track, manage, and deploy models. It manages the entire machine learning lifecycle. MLflow also manages models after deployment. Managing ML projects without MLFlow is challenging. Reproducibility : MLFlow standardizes how experiments are managed.
Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values. Although LLMs can generate syntactically correct SQL queries, they still need the table metadata for writing accurate SQL query.
Install them with: pip install pypdf langchain If you want to manage dependencies neatly, create a requirements.txt file with: pypdf langchain requests And run: pip install -r requirements.txt Step 1: Set Up the PDF Parser(parser.py) The core class CustomPDFParser uses PyPDF to extract text and metadata from each PDF page.
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. Both Delta Lake and Iceberg metadata files reference the same data files.
It is appealing to migrate from self-managed OpenSearch and Elasticsearch clusters in legacy versions to Amazon OpenSearch Service to enjoy the ease of use, native integration with AWS services, and rich features from the open-source environment ( OpenSearch is now part of Linux Foundation ).
The second use case enables the creation of reports containing shop floor key metrics for different management levels. In addition, the team aligned on business metadata attributes that would help with data discovery. The data solution uses Amazon DataZone glossaries and metadata forms to provide business context to their data.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machine learning services to streamline the user journey from data to insight. This led to inefficiencies in data governance and access control.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. You can also create new data lake tables using Redshift Managed Storage (RMS) as a native storage option.
Amazon DataZone , a data management service, helps you catalog, discover, share, and govern data stored across AWS, on-premises systems, and third-party sources. This Lambda function contains the logic to manage access policies for the subscribed unmanaged asset, automating the subscription process for unstructured S3 assets.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. As stated earlier, the first step involves data ingestion.
This isn’t just about making data management effortless—it’s about using AI to make your data work harder for you, unlocking insights that might otherwise remain hidden, and enabling everyone in your organization to work with data confidently, regardless of their technical expertise. Having confidence in your data is key.
However, managing schema evolution at scale presents significant challenges. To address this challenge, this post demonstrates how to build such a solution by combining Amazon Simple Storage Service (Amazon S3) for data storage, AWS Glue Data Catalog for schema management, and Amazon Athena for one-time querying.
Open table formats are emerging in the rapidly evolving domain of big data management, fundamentally altering the landscape of data storage and analysis. The adoption of open table formats is a crucial consideration for organizations looking to optimize their data management practices and extract maximum value from their data.
It combines the flexibility and scalability of data lake storage with the data analytics, data governance, and data management functionality of the data warehouse. They reduce data management effort and overhead by automating some of the most tedious lakehouse maintenance tasks. Go sign up for our 5-day trial here to see for yourself.
Combine data processing, AI analysis, and professional reporting without jumping between tools or managing complex infrastructure. Integration with Feature Stores Connect the workflow output to feature stores like Feast or Tecton for automated feature pipeline creation and management. // 2.
Zero-ETL is a set of fully managed integrations by AWS that minimizes the need to build ETL data pipelines. We take care of the ETL for you by automating the creation and management of data replication. Zero-ETL provides service-managed replication. Glue ETL offers customer-managed data ingestion. What is zero-ETL?
The post My Take on the 2024 Gartner® Critical Capabilities for Data Integration Tools Report appeared first on Data ManagementBlog - Data Integration and Modern Data Management Articles, Analysis and Information.
This API-first approach offers several advantages: you get access to cutting-edge capabilities without managing infrastructure, you can experiment with different models quickly, and you can focus on application logic rather than model implementation. Understanding Model Capabilities : Each foundation model excels in different areas.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. This approach simplifies your data journey and helps you meet your security requirements. For Database , enter your database name. Choose Add data.
Inevitably, the majority of companies will find themselves managing distributed systems, often in multiple clouds and on-premises. Clouderas investment in and support for open metadata standards, our true hybrid architecture, and our native Spark offering for Iceberg combine to make us the ideal Iceberg data lakehouse.
Today, they play a critical role in syncing with customer applications, enabling the ability to manage concurrent data operations while maintaining the integrity and consistency of information. By using features like Icebergs compaction, OTFs streamline maintenance, making it straightforward to manage object and metadata versioning at scale.
Today, organizations look to data and to technology to help them understand historical results, and predict the future needs of the enterprise to manage everything from suppliers and supplies to new locations, new products and services, hiring, training and investments. But too much data can also create issues.
Will the new creative, diverse and scalable data pipelines you are building also incorporate the AI governance guardrails needed to manage and limit your organizational risk? Metadata is the basis of trust for data forensics as we answer the questions of fact or fiction when it comes to the data we see.
schema.yml`: YAML file defining metadata, tests, and descriptions for the models in this directory. schema.yml`: YAML file defining metadata, tests, and descriptions for the staging models. With Dagster, you can easily manage diverse data operations across your ecosystem. toml │ setup. py │ └───orchestration assets. py __init__.
We have ingestion engineers, analytic engineers, stewards, governors, modelers, owners, scientists, product managers, compliance officers, and executives. Data Governance Teams: Data Governance professionals employ quality testing as a means to enhance data catalogs with high-quality metadata. But it also introduces a problem.
The post The R in RAG appeared first on Data ManagementBlog - Data Integration and Modern Data Management Articles, Analysis and Information. Many know that it stands for retrieval augmented generation, but recently I’ve encountered some confusion around the “R” (retrieval) aspect of RAG. I think that much of that confusion.
This blog post summarizes our findings, focusing on NER as a first-step key task for knowledge extraction. You can use the Ontotext Metadata Studio (OMDS) to integrate any NER model and apply it to your documents to extract the entities you are interested in.
SageMaker is natively integrated with Apache Airflow and Amazon Managed Workflows for Apache Airflow (Amazon MWAA), and is used to automate the workflow orchestration for jobs, querybooks, and notebooks with a Python-based DAG definition. To use the sample data provided in this blog post, your domain should be in us-east-1 region.
Together, you can use these capabilities to author, manage, operate, and monitor data processing workloads across your organization. Select the Amazon S3 source node and enter the following values: S3 URI: s3://aws-bigdata-blog/generated_synthetic_reviews/data/product_category=Apparel/ Format: Parquet Select Update node.
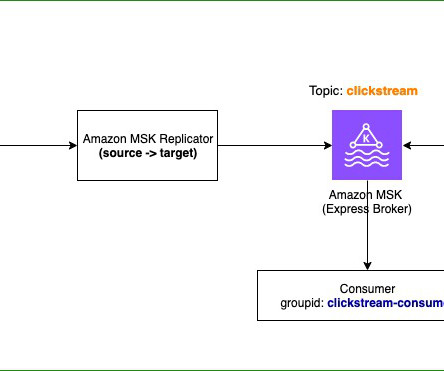
Amazon Managed Streaming for Apache Kafka (Amazon MSK) now offers a new broker type called Express brokers. Express brokers provide straightforward operations with hands-free storage management by offering unlimited storage without pre-provisioning, eliminating disk-related bottlenecks.
This feature will be discussed in detail later in this blog. The raw metadata is assumed to be not more than 100Gb. Vamshi Vijay Nakkirtha is a software engineering manager working on the OpenSearch Project and Amazon OpenSearch Service. For detailed implementation steps, see to the OpenSearch documentation.
Ali Tore, Senior Vice President of Advanced Analytics at Salesforce, highlighting the value of this integration, says “We’re excited to partner with Amazon to bring Tableau’s powerful data exploration and AI-driven analytics capabilities to customers managing data across organizational boundaries with Amazon DataZone.
Better MetadataManagement Add Descriptions and Data Product tags to tables and columns in the Data Catalog for improved governance. Enhanced Column Profiling Displays Get clearer insights with redesigned views in the Data Catalog, Profiling Results, Hygiene Issues, and Test Results pages. DataOps just got more intelligent.
Given the importance of data in the world today, organizations face the dual challenges of managing large-scale, continuously incoming data while vetting its quality and reliability. AWS Glue is a serverless data integration service that you can use to effectively monitor and manage data quality through AWS Glue Data Quality.
REST Catalog Value Proposition It provides open, metastore-agnostic APIs for Iceberg metadata operations, dramatically simplifying the Iceberg client and metastore/engine integration. It provides real time metadata access by directly integrating with the Iceberg-compatible metastore. You will see the 2 carrier records in the table.
With native Jira integration, teams can now create and manage workflows directly within their existing project management environment. Microsoft Entra ID SSO support : Simplify authentication and enhance security through centralized identity management. Modern data stack integration DBT integration : This is a game-changer.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI. It is a critical feature for delivering unified access to data in distributed, multi-engine architectures.
This is where business glossaries and metadata come in. Metadatamanagement tools and business glossary capabilities can help align these definitions early, before the move. The post Model first, move smart: Why data modeling is the key to successful migrations appeared first on erwin Expert Blog. They happen by design.
The problem isn’t just the volume of the data, but also how difficult it is to manage and make sense of it. All of this data is essential for investigations and threat hunting, but existing systems often struggle to manage it efficiently. In many traditional systems, query planning can take as long as executing the query itself.
To address these challenges, organizations often build bespoke integrations between services, tools, and their own access management systems. Build with projects : ML and generative AI model Build, train, and deploy ML and foundation models with fully managed infrastructure, tools, and workflows. option("multiLine", "true").option("header",
Organizations today face the challenge of managing and deriving insights from an ever-expanding universe of data in real time. The cost of commercial observability solutions becomes prohibitive, forcing teams to manage multiple separate tools and increasing both operational overhead and troubleshooting complexity.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content