This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Additionally, multiple copies of the same data locked in proprietary systems contribute to version control issues, redundancies, staleness, and management headaches. It leverages knowledge graphs to keep track of all the data sources and data flows, using AI to fill the gaps so you have the most comprehensive metadatamanagement solution.
Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values. Although LLMs can generate syntactically correct SQL queries, they still need the table metadata for writing accurate SQL query.
To mitigate this issue, various compression techniques can be used to optimize memory usage and computational efficiency. Amazon OpenSearch Service , as a vector database, supports scalar and product quantization techniques to optimize memory usage and reduce operational costs.
It combines the flexibility and scalability of data lake storage with the data analytics, data governance, and data management functionality of the data warehouse. Let’s take a look at some of the features in Cloudera Lakehouse Optimizer, the benefits they provide, and the road ahead for this service.
First query response times for dashboard queries have significantly improved by optimizing code execution and reducing compilation overhead. We have enhanced autonomics algorithms to generate and implement smarter and quicker optimal data layout recommendations for distribution and sort keys, further optimizing performance.
It is appealing to migrate from self-managed OpenSearch and Elasticsearch clusters in legacy versions to Amazon OpenSearch Service to enjoy the ease of use, native integration with AWS services, and rich features from the open-source environment ( OpenSearch is now part of Linux Foundation ).
Traditional machine learning systems excel at classification, prediction, and optimization—they analyze existing data to make decisions about new inputs. Instead of optimizing for accuracy metrics, you evaluate creativity, coherence, and usefulness. This difference shapes everything about how you work with these systems.
Open table formats are emerging in the rapidly evolving domain of big data management, fundamentally altering the landscape of data storage and analysis. The adoption of open table formats is a crucial consideration for organizations looking to optimize their data management practices and extract maximum value from their data.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. As stated earlier, the first step involves data ingestion.
Today, they play a critical role in syncing with customer applications, enabling the ability to manage concurrent data operations while maintaining the integrity and consistency of information. By using features like Icebergs compaction, OTFs streamline maintenance, making it straightforward to manage object and metadata versioning at scale.
Combine data processing, AI analysis, and professional reporting without jumping between tools or managing complex infrastructure. Integration with Feature Stores Connect the workflow output to feature stores like Feast or Tecton for automated feature pipeline creation and management. // 2.
However, managing schema evolution at scale presents significant challenges. To address this challenge, this post demonstrates how to build such a solution by combining Amazon Simple Storage Service (Amazon S3) for data storage, AWS Glue Data Catalog for schema management, and Amazon Athena for one-time querying.
Zero-ETL is a set of fully managed integrations by AWS that minimizes the need to build ETL data pipelines. We take care of the ETL for you by automating the creation and management of data replication. Zero-ETL provides service-managed replication. Glue ETL offers customer-managed data ingestion. What is zero-ETL?
Better MetadataManagement Add Descriptions and Data Product tags to tables and columns in the Data Catalog for improved governance. With updated TestGen 3.0 , you have the power to score, monitor, and optimize your data quality like never before. DataOps just got more intelligent.
This blog post summarizes our findings, focusing on NER as a first-step key task for knowledge extraction. We also experimented with prompt optimization tools, however these experiments did not yield promising results. In many cases, prompt optimizers were removing crucial entity-specific information and oversimplifying.
Finally, the purchase_patterns table examines customer purchase behavior over time, aiding in understanding buying trends and optimizing the customer journey. schema.yml`: YAML file defining metadata, tests, and descriptions for the models in this directory. customer_demographics.sql`: Model for transforming customer demographic data.
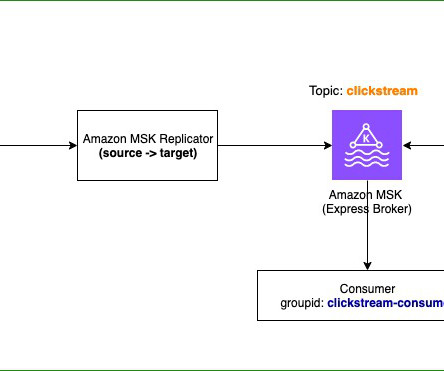
Amazon Managed Streaming for Apache Kafka (Amazon MSK) now offers a new broker type called Express brokers. Express brokers provide straightforward operations with hands-free storage management by offering unlimited storage without pre-provisioning, eliminating disk-related bottlenecks.
Are you incurring significant cross Availability Zone traffic costs when running an Apache Kafka client in containerized environments on Amazon Elastic Kubernetes Service (Amazon EKS) that consume data from Amazon Managed Streaming for Apache Kafka (Amazon MSK) topics? An Apache Kafka client consumer will register to read against a topic.
The problem isn’t just the volume of the data, but also how difficult it is to manage and make sense of it. All of this data is essential for investigations and threat hunting, but existing systems often struggle to manage it efficiently. In many traditional systems, query planning can take as long as executing the query itself.
Importance of baggage analytics Baggage management is a process that starts at baggage check-in and ends with the passenger claiming their baggage in a happy path scenario. The following figure explains the high-level baggage management process and respective key performance indicators (KPI).
Organizations today face the challenge of managing and deriving insights from an ever-expanding universe of data in real time. The cost of commercial observability solutions becomes prohibitive, forcing teams to manage multiple separate tools and increasing both operational overhead and troubleshooting complexity.
You can’t optimize what you don’t understand. This is where business glossaries and metadata come in. Metadatamanagement tools and business glossary capabilities can help align these definitions early, before the move. Maybe the only person who understood how that legacy CRM database was structured retired last year.
Superior functionality Enjoy advanced metadatamanagement, model and database comparisons, roundtrip engineering and deep integration with data catalogs and business glossaries. Learn More Now The post Dont get left in the dark with SAP PowerDesigner: Keep the lights on with erwin appeared first on erwin Expert Blog.
Healthcare systems face significant challenges managing vast amounts of data while maintaining regulatory compliance, security, and performance. In this post, we address common multi-tenancy challenges and provide actionable solutions for security, tenant isolation, workload management, and cost optimization across diverse healthcare tenants.
In this blog post, we will demonstrate how business units can use Amazon SageMaker Unified Studio to discover, subscribe to, and analyze these distributed data assets. SageMaker Lakehouse streamlines connecting to, cataloging, and managing permissions on data from multiple sources.
Its like optimizing your websites load time while your checkout process is brokenyoure getting better at the wrong thing. Instead of focusing on the few metrics that matter for your specific use case, youre trying to optimize multiple dimensions simultaneously. Second, too many metrics fragment your attention.
Despite their advantages, traditional data lake architectures often grapple with challenges such as understanding deviations from the most optimal state of the table over time, identifying issues in data pipelines, and monitoring a large number of tables.
This is part of our series of blog posts on recent enhancements to Impala. Impala Optimizations for Small Queries. We’ll discuss the various phases Impala takes a query through and how small query optimizations are incorporated into the design of each phase. The entire collection is available here. Query Planner Design.
Relational databases benefit from decades of tweaks and optimizations to deliver performance. This is a graph of millions of edges and vertices – in enterprise data management terms it is a giant piece of master/reference data. Not Every Graph is a Knowledge Graph: Schemas and Semantic Metadata Matter.
Iceberg tables store metadata in manifest files. As the number of data files increase, the amount of metadata stored in these manifest files also increases, leading to longer query planning time. The query runtime also increases because it’s proportional to the number of data or metadata file read operations.
1) What Is Data Quality Management? However, with all good things comes many challenges and businesses often struggle with managing their information in the correct way. Enters data quality management. What Is Data Quality Management (DQM)? Why Do You Need Data Quality Management? Table of Contents.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
This blog post is co-written with Hardeep Randhawa and Abhay Kumar from HPE. Their large inventory requires extensive supply chain management to source parts, make products, and distribute them globally. Each file arrives as a pair with a tail metadata file in CSV format containing the size and name of the file.
Enterprises are trying to manage data chaos. For decades, data modeling has been the optimal way to design and deploy new relational databases with high-quality data sources and support application development. erwin DM 2020 is an essential source of metadata and a critical enabler of data governance and intelligence efforts.
With all these diverse metadata sources, it is difficult to understand the complicated web they form much less get a simple visual flow of data lineage and impact analysis. The metadata-driven suite automatically finds, models, ingests, catalogs and governs cloud data assets. But let’s be honest – no one likes to move.
You also can manage the effectiveness of your business and ensure you understand what critical systems are for business continuity and measuring corporate performance. The most optimal and streamlined way to achieve this is by using a data catalog, which can provide a first stop for users ahead of working in BI platforms.
On AWS, you can run Trino on Amazon EMR , where you have the flexibility to run your preferred version of open source Trino on Amazon Elastic Compute Cloud (Amazon EC2) instances that you manage, or on Amazon Athena for a serverless experience. and later, S3 file metadata-based join optimizations are turned on by default.
The main use of business intelligence is to help business units, managers, top executives, and other operational workers make better-informed decisions backed up with accurate data. The top management believed that tackling this turnover would be key in improving the customer experience and that this would lead to higher revenues.
The Ozone Manager is a critical component of Ozone. It is a replicated, highly-available service that is responsible for managing the metadata for all objects stored in Ozone. As Ozone scales to exabytes of data, it is important to ensure that Ozone Manager can perform at scale.
Metadatamanagement performs a critical role within the modern data management stack. However, as data volumes continue to grow, manual approaches to metadatamanagement are sub-optimal and can result in missed opportunities. This puts into perspective the role of active metadatamanagement.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Apache Iceberg addresses customer needs by capturing rich metadata information about the dataset at the time the individual data files are created.
In a previous blog , I explained that data lineage is basically the history of data, including a data set’s origin, characteristics, quality and movement over time. This information is critical to regulatory compliance, change management and data governance not to mention delivering an optimal customer experience.
Cloudinary is a cloud-based media management platform that provides a comprehensive set of tools and services for managing, optimizing, and delivering images, videos, and other media assets on websites and mobile applications.
To improve the way they model and manage risk, institutions must modernize their data management and data governance practices. Implementing a modern data architecture makes it possible for financial institutions to break down legacy data silos, simplifying data management, governance, and integration — and driving down costs.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content