This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It leverages knowledge graphs to keep track of all the data sources and data flows, using AI to fill the gaps so you have the most comprehensive metadata management solution. Together, Cloudera and Octopai will help reinvent how customers manage their metadata and track lineage across all their data sources.
Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values. Although LLMs can generate syntactically correct SQL queries, they still need the table metadata for writing accurate SQL query.
When an organization’s data governance and metadata management programs work in harmony, then everything is easier. Creating and sustaining an enterprise-wide view of and easy access to underlying metadata is also a tall order. Metadata Management Takes Time. Finding metadata, “the data about the data,” isn’t easy.
What Is Metadata? Metadata is information about data. A clothing catalog or dictionary are both examples of metadata repositories. Indeed, a popular online catalog, like Amazon, offers rich metadata around products to guide shoppers: ratings, reviews, and product details are all examples of metadata.
Metadata management is key to wringing all the value possible from data assets. What Is Metadata? Analyst firm Gartner defines metadata as “information that describes various facets of an information asset to improve its usability throughout its life cycle. It is metadata that turns information into an asset.”.
way we package information has a lot to do with metadata. The somewhat conventional metaphor about metadata is the one of the library card. This metaphor has it that books are the data and library cards are the metadata helping us find what we need, want to know more about or even what we don’t know we were looking for.
In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient. You will learn about an open-source solution that can collect important metrics from the Iceberg metadata layer.
Under the hood, UniForm generates Iceberg metadata files (including metadata and manifest files) that are required for Iceberg clients to access the underlying data files in Delta Lake tables. Both Delta Lake and Iceberg metadata files reference the same data files. The table is registered in AWS Glue Data Catalog.
Not Every Graph is a Knowledge Graph: Schemas and Semantic Metadata Matter. To be able to automate these operations and maintain sufficient data quality, enterprises have started implementing the so-called data fabrics , that employ diverse metadata sourced from different systems. Metadata about Relationships Come in Handy.
Better Metadata Management Add Descriptions and Data Product tags to tables and columns in the Data Catalog for improved governance. Smarter Profiling & Test Generation Improved logic reduces false positives , making test results more accurate and actionable. DataOps just got more intelligent.
How RFS works OpenSearch and Elasticsearch snapshots are a directory tree that contains both data and metadata. Metadata files exist in the snapshot to provide details about the snapshot as a whole, the source cluster’s global metadata and settings, each index in the snapshot, and each shard in the snapshot.
If you include the title of this blog, you were just presented with 13 examples of heteronyms in the preceding paragraphs. This is accomplished through tags, annotations, and metadata (TAM). Smart content includes labeled (tagged, annotated) metadata (TAM). What you have just experienced is a plethora of heteronyms.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI. It is a critical feature for delivering unified access to data in distributed, multi-engine architectures.
And for that future to be a reality, data teams must shift their attention to metadata, the new turf war for data. The need for unified metadata While open and distributed architectures offer many benefits, they come with their own set of challenges. Data teams actually need to unify the metadata. Open data is the future.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
An Iceberg table’s metadata stores a history of snapshots, which are updated with each transaction. Over time, this creates multiple data files and metadata files as changes accumulate. Additionally, they can impact query performance due to the overhead of handling large amounts of metadata.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. Launch summary Following is the launch summary which provides the announcement links and reference blogs for the key announcements.
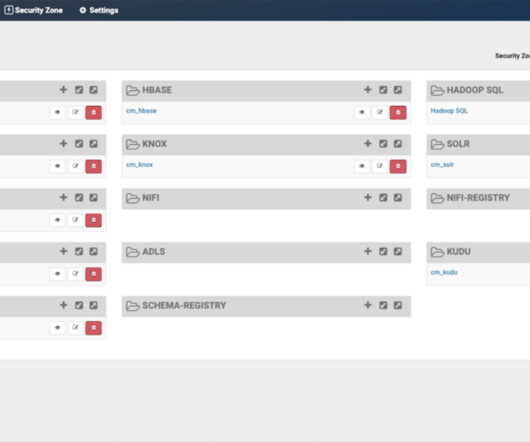
This will allow a data office to implement access policies over metadata management assets like tags or classifications, business glossaries, and data catalog entities, laying the foundation for comprehensive data access control. First, a set of initial metadata objects are created by the data steward.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machine learning services to streamline the user journey from data to insight.
And specifically, I was reading one of your blog posts recently that talked about the dark ages of data. It could be metadata that you weren’t capturing before. The post The Struggle Between Data Dark Ages and LLM Accuracy appeared first on Cloudera Blog. Here are some key takeaways from Ray in that conversation.
The main goal of creating an enterprise data fabric is not new. It is the ability to deliver the right data at the right time, in the right shape, and to the right data consumer, irrespective of how and where it is stored. Data fabric is the common “net” that stitches integrated data from multiple data […].
Run the following commands: export PROJ_NAME=lfappblog aws s3 cp s3://aws-blogs-artifacts-public/BDB-3934/schema.graphql ~/${PROJ_NAME}/amplify/backend/api/${PROJ_NAME}/schema.graphql In the s chema.graphql file, you can see that the lf-app-lambda-engine function is set as the data source for the GraphQL queries.
Organizations with particularly deep data stores might need a data catalog with advanced capabilities, such as automated metadata harvesting to speed up the data preparation process. Three Types of Metadata in a Data Catalog. The metadata provides information about the asset that makes it easier to locate, understand and evaluate.
With all these diverse metadata sources, it is difficult to understand the complicated web they form much less get a simple visual flow of data lineage and impact analysis. The metadata-driven suite automatically finds, models, ingests, catalogs and governs cloud data assets. Subscribe to the erwin Expert Blog.
The domain requires a team that creates/updates/runs the domain, and we can’t forget metadata: catalogs, lineage, test results, processing history, etc., …. At this point in our blog series, we have talked about data mesh from an organizational and technical perspective.
Discoverable – users have access to a catalog or metadata management tool which renders the domain discoverable and accessible. We’ll cover some of the potential challenges facing data mesh enterprise architectures in our next blog. Also, the domain must support the attributes that are part of every modern data architecture.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Apache Iceberg addresses customer needs by capturing rich metadata information about the dataset at the time the individual data files are created.
These rules are not necessarily “Rocket Science” (despite the name of this blog site), but they are common business sense for most business-disruptive technology implementations in enterprises. The latter is essential for Generative AI implementations.
In a previous blog , I explored the value of dark data and how it can reveal insights that can streamline processes, improve customer experiences, generate more revenue – and maybe even help make the world a better place. Analyze your metadata. The data you’ve collected and saved over the years isn’t free. Use people.
That’s because it’s the best way to visualize metadata , and metadata is now the heart of enterprise data management and data governance/ intelligence efforts. erwin DM 2020 is an essential source of metadata and a critical enabler of data governance and intelligence efforts. erwin Data Modeler: Where the Magic Happens.
Business analysts enhance the data with business metadata/glossaries and publish the same as data assets or data products. Users can search for assets in the Amazon DataZone catalog, view the metadata assigned to them, and access the assets. Amazon Athena is used to query, and explore the data.
This means the data files in the data lake aren’t modified during the migration and all Apache Iceberg metadata files (manifests, manifest files, and table metadata files) are generated outside the purview of the data. In this method, the metadata are recreated in an isolated environment and colocated with the existing data files.
Metadata is the basis of trust for data forensics as we answer the questions of fact or fiction when it comes to the data we see. Being that AI is comprised of more data than code, it is now more essential than ever to combine data with metadata in near real-time.
This is part of our series of blog posts on recent enhancements to Impala. Metadata Caching. As Impala’s adoption grew the catalog service started to experience these growing pains, therefore recently we introduced two new features to alleviate the stress, On-demand Metadata and Zero Touch Metadata. More on this below.
After you create the asset, you can add glossaries or metadata forms, but its not necessary for this post. Create it as a JSON file on your workstation (for this post, we call it blog-sub-target.json ). Enter a name for the asset. For Asset type , choose S3 object collection. For S3 location ARN , enter the ARN of the S3 prefix.
This blog post will explore how zero-ETL capabilities combined with its new application connectors are transforming the way businesses integrate and analyze their data from popular platforms such as ServiceNow, Salesforce, Zendesk, SAP and others. The data is also registered in the Glue Data Catalog , a metadata repository.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. Data and Metadata: Data inputs and data outputs produced based on the application logic. Introduction.
This blog post summarizes our findings, focusing on NER as a first-step key task for knowledge extraction. You can use the Ontotext Metadata Studio (OMDS) to integrate any NER model and apply it to your documents to extract the entities you are interested in.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient data analytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. Each change to a table produces a new metadata file to provide atomicity.
Most data governance tools today start with the slow, waterfall building of metadata with data stewards and then hope to use that metadata to drive code that runs in production. In reality, the ‘active metadata’ is just a written specification for a data developer to write their code.
In this blog post, we will ingest a real world dataset into Ozone, create a Hive table on top of it and analyze the data to study the correlation between new vaccinations and new cases per country using a Spark ML Jupyter notebook in CML. Learn more about the impacts of global data sharing in this blog, The Ethics of Data Exchange.
Companies such as Adobe , Expedia , LinkedIn , Tencent , and Netflix have published blogs about their Apache Iceberg adoption for processing their large scale analytics datasets. . In CDP we enable Iceberg tables side-by-side with the Hive table types, both of which are part of our SDX metadata and security framework.
In a previous blog , I explained that data lineage is basically the history of data, including a data set’s origin, characteristics, quality and movement over time. Data lineage helps answer questions about the origin of data in key performance indicator (KPI) reports, including: How are the report tables and columns defined in the metadata?
However, more than 50 percent say they have deployed metadata management, data analytics, and data quality solutions. erwin Named a Leader in Gartner 2019 Metadata Management Magic Quadrant. And close to 50 percent have deployed data catalogs and business glossaries. Most have only data governance operations.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content