This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enterprise data is brought into data lakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. We use Anthropic’s Claude 2.1 foundation model (FM) in Amazon Bedrock as the LLM.
Metadata used to be a secret shared between system programmers and the data. Metadata described the data in terms of cardinality, data types such as strings vs integers, and primary or foreign key relationships. Inevitably, the information that could and needed to be expressed by metadata increased in complexity.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud data warehouses.
Introduction In the real world, obtaining high-quality annotated data remains a challenge. This blog post summarizes our findings, focusing on NER as a first-step key task for knowledge extraction. Data In Natural Language Processing (NLP), domain-specific knowledge plays a crucial role in the accuracy of tasks like NER.
There are countless examples of big data transforming many different industries. There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. This is something that you can learn more about in just about any technology blog.
Producing insights from raw data is a time-consuming process. The Importance of Exploratory Analytics in the Data Science Lifecycle. Exploratory analysis is a critical component of the data science lifecycle. As a result, exploratory analysis is inherently iterative, and difficult to scope.
This blog post is co-written with Raj Samineni from ATPCO. In today’s data-driven world, companies across industries recognize the immense value of data in making decisions, driving innovation, and building new products to serve their customers.
Next, I will explain how knowledge graphs help them to get a unified view to data derived from multiple sources and get richer insights in less time. Next, I will explain how knowledge graphs help them to get a unified view to data derived from multiple sources and get richer insights in less time.
Many data catalog initiatives fail. According to the latest report from Eckerson Group, Deep Dive on Data Catalogs , shoppers must match the goals of their organizations to the capabilities of their chosen catalog. A data catalog’s approach is key. Finding a trustworthy asset in a sea of data can take analysts months.
When I think about unstructured data, I see my colleague Rob Gerbrandt (an information governance genius) walking into a customer’s conference room where tubes of core samples line three walls. While most of us would see dirt and rock, Rob sees unstructured data. have encouraged the creation of unstructured data.
Data modeling supports collaboration among business stakeholders – with different job roles and skills – to coordinate with business objectives. Data resides everywhere in a business , on-premise and in private or public clouds. A single source of data truth helps companies begin to leverage data as a strategic asset.
We started with our marketing content and quickly expanded that to also integrate a set of workflows for data and content management. Through Ontotext Metadata Studio (OMDS), we then apply semantic content enrichment using textanalysis based on our marketing vocabularies.
Year after year, IBM Consulting works with the United States Tennis Association (USTA) to transform massive amounts of data into meaningful insight for tennis fans. This year, the USTA is using watsonx , IBM’s new AI and data platform for business.
AI and machine learning are the future of every industry, especially data and analytics. Reading through the Gartner Top 10 Trends in Data and Analytics for 2020 , I was struck by how different terms mean different things to different audiences under different contexts. But what do we really mean when we talk about these issues?
Ever since Hippocrates founded his school of medicine in ancient Greece some 2,500 years ago, writes Hannah Fry in her book Hello World: Being Human in the Age of Algorithms , what has been fundamental to healthcare (as she calls it “the fight to keep us healthy”) was observation, experimentation and the analysis of data.
What Makes a Data Fabric? Data Fabric’ has reached where ‘Cloud Computing’ and ‘Grid Computing’ once trod. Data Fabric hit the Gartner top ten in 2019. This multiplicity of data leads to the growth silos, which in turns increases the cost of integration. It is a buzzword.
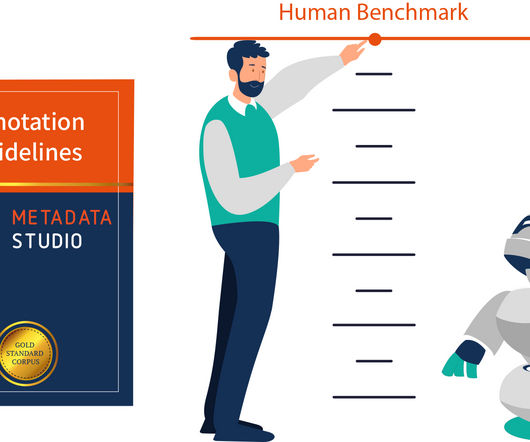
An area of AI that Ontotext has been working on for over 20 years is text analytics. This data can then be easily analyzed to provide insights or used to train machine learning models. In text analytics, the human benchmark is a set of documents manually annotated by human experts. You can read more about it in this blog post.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible data transforms in Python and SQL. dbt is predominantly used by data warehouses (such as Amazon Redshift ) customers who are looking to keep their data transform logic separate from storage and engine.
In much the same way, in the context of Artificial Intelligence AI systems, the Gold Standard refers to a set of data that has been manually prepared or verified and that represents “the objective truth” as closely as possible. And this is a challenge, as today’s data comes in huge volumes and from various sources.
Apache Spark is a powerful big data engine used for large-scale data analytics. You can use Apache Spark to process streaming data from a variety of streaming sources, including Amazon Kinesis Data Streams for use cases like clickstream analysis, fraud detection, and more. Starting with Amazon EMR 7.1,
It enriched their understanding of the full spectrum of knowledge graph business applications and the technology partner ecosystem needed to turn data into a competitive advantage. Content and data management solutions based on knowledge graphs are becoming increasingly important across enterprises.
The integration of DataRobot and Azure OpenAI Service breaks down a barrier that has long existed between data teams and business stakeholders. Traditionally, developing appropriate data science code and interpreting the results to solve a use-case is manually done by data scientists.
At the same time, most data management (DM) applications require 100% correct retrieval, 0% hallucination! At the same time, most data management (DM) applications require 100% correct retrieval, 0% hallucination! And getting a free text summary of the results, instead of just a table. I am very optimistic!
In this blog, I will cover: What is watsonx.ai? IBM software products are embedding watsonx capabilities across digital labor, IT automation, security, sustainability, and application modernization to help unlock new levels of business value for clients. What capabilities are included in watsonx.ai? What is watsonx.data? What is watsonx.ai?
In today’s digital age, data is at the heart of every organization’s success. One of the most commonly used formats for exchanging data is XML. Analyzing XML files can help organizations gain insights into their data, allowing them to make better decisions and improve their operations.
The three roles of a knowledge graph A knowledge graph is a versatile way of organizing and using data. Like a database , knowledge graphs have schemas and users can apply complex structured queries to extract specific data needed. Because of the formal semantics attached to the data, knowledge graphs can act as a knowledge base.
Sentiment analysis invites us to consider the sentence, You’re so smart! In fact, when presented with a piece of text, sometimes even humans disagree about its tonality, especially if there’s not a fair deal of informative context provided to help rule out incorrect interpretations. Sentiment analysis datasets. It provides 1.6
Organizations that invest time and resources to improve the knowledge and capabilities of their employees perform better. The risk is that the organization creates a valuable asset with years of expertise and experience that is directly relevant to the organization and that valuable asset can one day cross the street to your competitors.
In this post, we explain how you can enable business users to ask and answer questions about data using their everyday business language by using the Amazon QuickSight natural language query function, Amazon QuickSight Q. Q uses the same QuickSight datasets you use for your dashboards and reports so your data is governed and secured.
This is part of Ontotext’s AI-in-Action initiative aimed at enabling data scientists and engineers to benefit from the AI capabilities of our products. RED’s focus on news content serves a pivotal function: identifying, extracting, and structuring data on events, parties involved, and subsequent impacts.
In 2023, data leaders and enthusiasts were enamored of — and often distracted by — initiatives such as generative AI and cloud migration. I expect to see the following data and knowledge management trends emerge in 2024.
It uses Amazon Simple Storage Service (Amazon S3) as the primary data storage for indexes, adding durability for your data. It uses Amazon Simple Storage Service (Amazon S3) as the primary data storage for indexes, adding durability for your data. When you create a serverless collection, you set a collection type.
Companies collect and analyze vast amounts of data to make informed business decisions. From product development to customer satisfaction, nearly every aspect of a business uses data and analytics to measure success and define strategies. When choosing between qualitative and quantitative data, think about what you want to learn.
According to an article in Harvard Business Review , cross-industry studies show that, on average, big enterprises actively use less than half of their structured data and sometimes about 1% of their unstructured data. The many data warehouse systems designed in the last 30 years present significant difficulties in that respect.
That’s the equivalent of 1 petabyte ( ComputerWeekly ) – the amount of unstructured data available within our large pharmaceutical client’s business. Then imagine the insights that are locked in that massive amount of data. Ensure content can be reused within the data hub to support pharmaceutical use cases.
Entity linking is the process of automatically linking entity mentions from text to the corresponding entries in a knowledge base. It has been an important capability for Ontotext ever since we dove into Natural Language Processing (NLP), as it is a crucial aspect of the interplay between textanalysis and knowledge graphs.
We’ve already discussed that enterprise knowledge graphs bring together and harmonize all-important organizational knowledge and metadata. We’ve already discussed that enterprise knowledge graphs bring together and harmonize all-important organizational knowledge and metadata. Building a single data graph across the three services.
Consider the following practices that, until recently, were relegated to the R&D department: Data-driven decision making – the collection and analysis of data to guide decisions that improve success. Complicating matters is the increasing focus on data protection and the far-reaching implications of IoT (e.g.
Ontotext’s GraphDB is an enterprise-ready semantic graph database (also called RDF triplestore because it stores data in RDF triples). It provides the core infrastructure for solutions where modelling agility, data integration, relationship exploration, cross-enterprise data publishing and consumption are critical. .
In today’s fast changing environment, enterprises that have transitioned from being focused on applications to becoming data-driven gain a significant competitive edge. There are four groups of data that are naturally siloed: Structured data (e.g., internal metadata, industry ontologies, etc.)
Data leaders today are faced with an almost impossible challenge. They are expected to understand the entire data landscape and generate business-moving insights while facing the voracious needs of different teams and the constraints of technology architecture and compliance.
It’s no secret that data scientists and researchers spend 80% of their time on the less glamorous tasks of chasing down data, cleaning it up, and making sure it’s not full of nonsense. During the target identification phase of drug development, several challenges related to data can impede progress.
It’s no secret that data scientists and researchers spend 80% of their time on the less glamorous tasks of chasing down data, cleaning it up, and making sure it’s not full of nonsense. During the target identification phase of drug development, several challenges related to data can impede progress.
The similarity indices are a fuzzy match heuristic based on statistical semantics, which is particularly useful when retrieving the closest related texts or when grouping a cluster of graph nodes based on their topology. Let’s go through some of the main types of text semantic similarities searches with a simple but representative example.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content