This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It leverages knowledge graphs to keep track of all the data sources and data flows, using AI to fill the gaps so you have the most comprehensive metadata management solution. Together, Cloudera and Octopai will help reinvent how customers manage their metadata and track lineage across all their data sources.
Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values. Although LLMs can generate syntactically correct SQL queries, they still need the table metadata for writing accurate SQL query.
Better Metadata Management Add Descriptions and Data Product tags to tables and columns in the Data Catalog for improved governance. With updated TestGen 3.0 , you have the power to score, monitor, and optimize your data quality like never before. DataOps just got more intelligent.
Despite their advantages, traditional data lake architectures often grapple with challenges such as understanding deviations from the most optimal state of the table over time, identifying issues in data pipelines, and monitoring a large number of tables. It is essential for optimizing read and write performance.
This is part of our series of blog posts on recent enhancements to Impala. Impala Optimizations for Small Queries. We’ll discuss the various phases Impala takes a query through and how small query optimizations are incorporated into the design of each phase. The entire collection is available here. Query Planner Design.
Relational databases benefit from decades of tweaks and optimizations to deliver performance. Not Every Graph is a Knowledge Graph: Schemas and Semantic Metadata Matter. This metadata should then be represented, along with its intricate relationships, in a connected knowledge graph model that can be understood by the business teams”.
The adoption of open table formats is a crucial consideration for organizations looking to optimize their data management practices and extract maximum value from their data. An Iceberg table’s metadata stores a history of snapshots, which are updated with each transaction. In earlier posts, we discussed AWS Glue 5.0 for Apache Spark.
First query response times for dashboard queries have significantly improved by optimizing code execution and reducing compilation overhead. We have enhanced autonomics algorithms to generate and implement smarter and quicker optimal data layout recommendations for distribution and sort keys, further optimizing performance.
Iceberg tables store metadata in manifest files. As the number of data files increase, the amount of metadata stored in these manifest files also increases, leading to longer query planning time. The query runtime also increases because it’s proportional to the number of data or metadata file read operations.
How RFS works OpenSearch and Elasticsearch snapshots are a directory tree that contains both data and metadata. Metadata files exist in the snapshot to provide details about the snapshot as a whole, the source cluster’s global metadata and settings, each index in the snapshot, and each shard in the snapshot.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
For decades, data modeling has been the optimal way to design and deploy new relational databases with high-quality data sources and support application development. That’s because it’s the best way to visualize metadata , and metadata is now the heart of enterprise data management and data governance/ intelligence efforts.
With all these diverse metadata sources, it is difficult to understand the complicated web they form much less get a simple visual flow of data lineage and impact analysis. The metadata-driven suite automatically finds, models, ingests, catalogs and governs cloud data assets. Subscribe to the erwin Expert Blog.
Organizations with particularly deep data stores might need a data catalog with advanced capabilities, such as automated metadata harvesting to speed up the data preparation process. The most optimal and streamlined way to achieve this is by using a data catalog, which can provide a first stop for users ahead of working in BI platforms.
Run the following commands: export PROJ_NAME=lfappblog aws s3 cp s3://aws-blogs-artifacts-public/BDB-3934/schema.graphql ~/${PROJ_NAME}/amplify/backend/api/${PROJ_NAME}/schema.graphql In the s chema.graphql file, you can see that the lf-app-lambda-engine function is set as the data source for the GraphQL queries.
This blog post is co-written with Hardeep Randhawa and Abhay Kumar from HPE. Each file arrives as a pair with a tail metadata file in CSV format containing the size and name of the file. This metadata file is later used to read source file names during processing into the staging layer.
Cloudinary is a cloud-based media management platform that provides a comprehensive set of tools and services for managing, optimizing, and delivering images, videos, and other media assets on websites and mobile applications. This concept makes Iceberg extremely versatile.
In this context, Amazon DataZone is the optimal choice for managing the enterprise data platform. Business analysts enhance the data with business metadata/glossaries and publish the same as data assets or data products. As stated earlier, the first step involves data ingestion. Amazon Athena is used to query, and explore the data.
Metadata management performs a critical role within the modern data management stack. However, as data volumes continue to grow, manual approaches to metadata management are sub-optimal and can result in missed opportunities. This puts into perspective the role of active metadata management. Improve data discovery.
Ontotext’s approach is to optimize models and algorithms through human contribution and benchmarking in order to create better and more accurate AI. You can read more about it in this blog post. What Are The Benefits Of Using Ontotext Metadata Studio? Ontotext Metadata Studio addresses all of these problems head on.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Apache Iceberg addresses customer needs by capturing rich metadata information about the dataset at the time the individual data files are created.
When you use Trino on Amazon EMR or Athena, you get the latest open source community innovations along with proprietary, AWS developed optimizations. and Athena engine version 2, AWS has been developing query plan and engine behavior optimizations that improve query performance on Trino. Starting from Amazon EMR 6.8.0
This is a guest blog post co-written with Sumesh M R from Cargotec and Tero Karttunen from Knowit Finland. Through their unique position in ports, at sea, and on roads, they optimize global cargo flows and create sustainable customer value. An AWS Glue job (metadata exporter) runs daily on the source account.
In the public cloud, these cost management issues are compounded by consumption rates, where compute is often overused due to a lack of visibility into optimization opportunities. The data temperature feature lets us see whether hot or cold data sets are deployed optimally, including the underlying file sizes and partitioning styles.
This blog post summarizes our findings, focusing on NER as a first-step key task for knowledge extraction. We also experimented with prompt optimization tools, however these experiments did not yield promising results. In many cases, prompt optimizers were removing crucial entity-specific information and oversimplifying.
In a previous blog , I explained that data lineage is basically the history of data, including a data set’s origin, characteristics, quality and movement over time. This information is critical to regulatory compliance, change management and data governance not to mention delivering an optimal customer experience.
Achieving consistently high performance requires an efficient routing system, optimizing traffic between the services your application depends on. In summary, IBM NS1 Connect offers a range of traffic steering options to meet diverse business needs to help ensure optimal application performance in the “now” era.
Companies such as Adobe , Expedia , LinkedIn , Tencent , and Netflix have published blogs about their Apache Iceberg adoption for processing their large scale analytics datasets. . Users do not need to know how the table is partitioned to optimize the SQL query performance. Multi-function analytics .
This blog post will explore how zero-ETL capabilities combined with its new application connectors are transforming the way businesses integrate and analyze their data from popular platforms such as ServiceNow, Salesforce, Zendesk, SAP and others. The data is also registered in the Glue Data Catalog , a metadata repository.
Artificial intelligence (AI) is something that, by its very nature, can be surrounded by a sea of skepticism but also excitement and optimism when it comes to harnessing its power. Preparing For an AI-powered Future There’s plenty of optimism and interest surrounding GenAI and AI more broadly.
With lots of data comes yet more calls for automation, optimization, and productivity initiatives to put that data to good use. Analysis, however, requires enterprises to find and collect metadata. Download Gartner’s “Market Guide for Active Metadata Management” to learn more, or read on for a summary of the firm’s outlook.
This benefit goes directly in hand with the fact that analytics provide businesses with technologies to spot trends and patterns that will lead to the optimization of resources and processes. It is important to optimize processes, increase operational efficiency, drive new revenue, and improve the decision-making of the company.
This is something that you can learn more about in just about any technology blog. How is Data Virtualization performance optimized? The study and analysis of data allows to improve the automation of processes, optimizing sales strategies and improving business efficiency. for scalable performance in demanding environments.
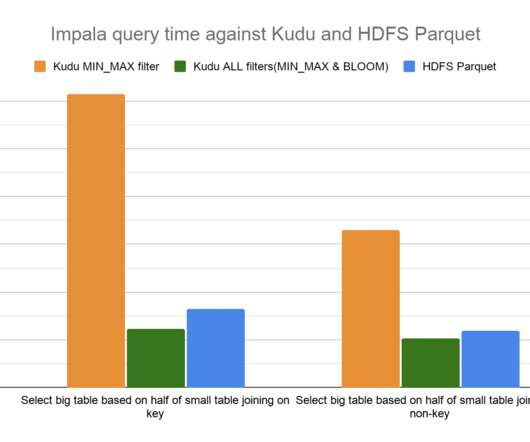
Pushing down column predicate filters to Kudu allows for optimized execution by skipping reading column values for filtered out rows and reducing network IO between a client, like the distributed query engine Apache Impala, and Kudu. One of the ways Apache Kudu achieves this is by supporting column predicates with scanners. Join Queries.
As the economy slowed, they focused on cost optimization. Even if you don’t have a formal data intelligence program in place, there is a good possibility your organization has intelligence about its data, because it is difficult for data to exist without some form of associated metadata.
Bhaval Patel of Space-O Technologies wrote a blog post about the growing importance of AI for mobile apps. In this blog post, we will explore how AI-driven app development strategies can help your e-commerce business stay ahead in the mobile-first world. AI has been invaluable for e-commerce brands.
This blog discusses a few problems that you might encounter with Iceberg tables and offers strategies on how to optimize them in each of those scenarios. A bloated metadata.json file could increase both read/write times because a large metadata file needs to be read/written every time. Iceberg doesn’t delete the old data files.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. Data and Metadata: Data inputs and data outputs produced based on the application logic. Introduction.
Overview This blog post describes support for materialized views for the Iceberg table format. Queries containing joins, filters, projections, group-by, or aggregations without group-by can be transparently rewritten by the Hive optimizer to use one or more eligible materialized views.
In a previous blog post on CDW performance, we compared Azure HDInsight to CDW. In this blog post, we compare Cloudera Data Warehouse (CDW) on Cloudera Data Platform (CDP) using Apache Hive-LLAP to EMR 6.0 (also powered by Apache Hive-LLAP) on Amazon using the TPC-DS 2.9 More on this later in the blog.
Hudi provides tables , transactions , efficient upserts and deletes , advanced indexes , streaming ingestion services , data clustering and compaction optimizations, and concurrency control , all while keeping your data in open source file formats. Read optimized queries – For MoR tables, queries see the latest data compacted.
In this blog post, we compare Cloudera Data Warehouse (CDW) on Cloudera Data Platform (CDP) using Apache Hive-LLAP to Microsoft HDInsight (also powered by Apache Hive-LLAP) on Azure using the TPC-DS 2.9 The post Cloudera Data Warehouse outperforms Azure HDInsight in TPC-DS benchmark appeared first on Cloudera Blog.
Data Pipeline Observability: Optimizes pipelines by monitoring data quality, detecting issues, tracing data lineage, and identifying anomalies using live and historical metadata. At DataKitchen, we think of this is a ‘meta-orchestration’ of the code and tools acting upon the data.
Advanced predictive analytics and modeling are now optimizing safety stocks and supply chains to include the element in risk so that optimized inventory levels and redundant capital deployment in high risk manufacturing processes are optimized. Digital Transformation is not without Risk. Open source solutions reduce risk.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content