This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In the real world, obtaining high-quality annotated data remains a challenge. Generative AI (GenAI) models, such as GPT-4, offer a promising solution, potentially reducing the dependency on labor-intensive annotation. This blog post summarizes our findings, focusing on NER as a first-step key task for knowledge extraction.
Programmers encounter many common challenges when trying to teach computers to understand natural language text data. In this post, we’ll discuss these challenges in detail and include some tips and tricks to help you handle text data more easily. Most common challenges we face in NLP are around unstructured data and Big Data.
Challenges Medical multilingual question answering (QA) presents several challenges stemming from the diverse nature of medical terminologies and linguistic variations. Furthermore, as the clinical data is highly sensitive, there are no open-access models or datasets available to solve the task, especially in the multilingual setting.
To help in the battle against disinformation, Ontotext is tackling the challenge of identifying narratives or disinformation campaigns. According to recent publications for entity linking , Wikipedia and Wikidata are among the most popular ones. Wikidata is the biggest public knowledge graph, covering over 100 million entities.
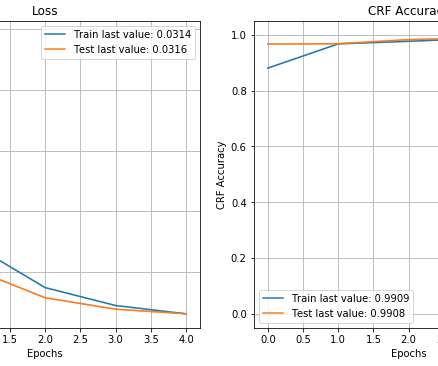
In this blog post we present the NamedEntityRecognition problem and show how a BiLSTM-CRF model can be fitted using a freely available annotated corpus and Keras. The model achieves relatively high accuracy and all data and code is freely available in the article. What is NamedEntityRecognition?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content