This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Snapshots are crucial for data backup and disaster recovery in Amazon OpenSearch Service. These snapshots allow you to generate backups of your domain indexes and cluster state at specific moments and save them in a reliable storage location such as Amazon Simple Storage Service (Amazon S3). Snapshots are not instantaneous.
In this post, we will introduce a new mechanism called Reindexing-from-Snapshot (RFS), and explain how it can address your concerns and simplify migrating to OpenSearch. Documents are parsed from the snapshot and then reindexed to the target cluster, so that performance impact to the source clusters is minimized during migration.
The adoption of open table formats is a crucial consideration for organizations looking to optimize their data management practices and extract maximum value from their data. Branching Branches are independent lineage of snapshot history that point to the head of each lineage. In earlier posts, we discussed AWS Glue 5.0
Contour Plots allow for the easy identification of maxima, minima, and optimal combinations of X and Y variables that produce desired Z values. Contour plots — Stata The post Chart Snapshot: Contour Plots appeared first on The Data Visualisation Catalogue Blog.
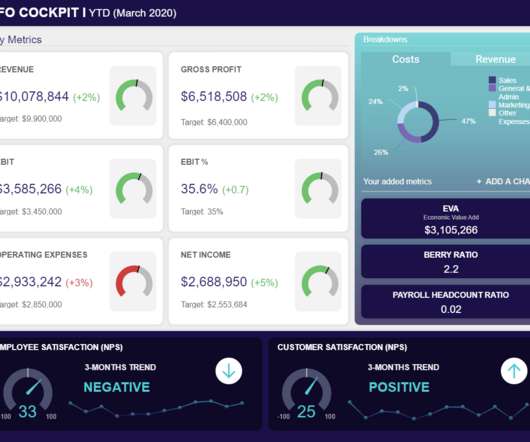
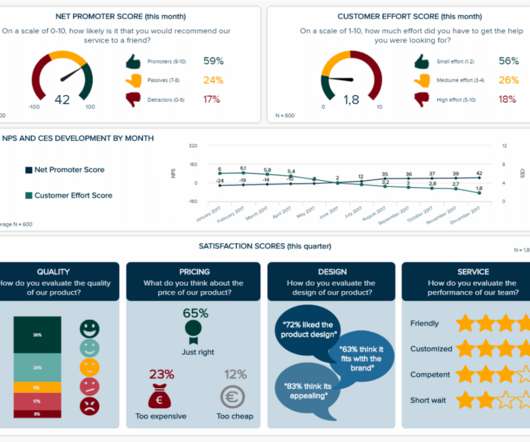
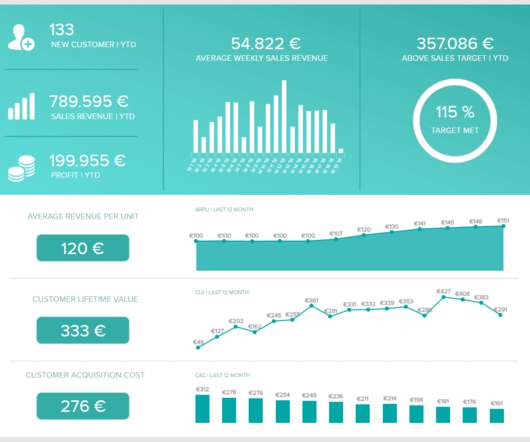
By including this cohesive mix of visual information, every CFO, regardless of sector, can gain a clear snapshot of the company’s fiscal performance within the first quarter of the year. Once you have set your aims, goals, and outcomes, you will be able to select CFO dashboard KPIs that will help you optimize your efforts.
Systems of this nature generate a huge number of small objects and need attention to compact them to a more optimal size for faster reading, such as 128 MB, 256 MB, or 512 MB. As of this writing, only the optimize-data optimization is supported. To check how to create an Amazon S3 bucket, follow the instructions given here.
With a powerful dashboard maker , each point of your customer relations can be optimized to maximize your performance while bringing various additional benefits to the picture. Whether you’re looking at consumer management dashboards and reports, every CRM dashboard template you use should be optimal in terms of design.
This is part of our series of blog posts on recent enhancements to Impala. Impala Optimizations for Small Queries. We’ll discuss the various phases Impala takes a query through and how small query optimizations are incorporated into the design of each phase. The entire collection is available here. Query Planner Design.
Despite their advantages, traditional data lake architectures often grapple with challenges such as understanding deviations from the most optimal state of the table over time, identifying issues in data pipelines, and monitoring a large number of tables. It is essential for optimizing read and write performance.
You can use big data analytics in logistics, for instance, to optimize routing, improve factory processes, and create razor-sharp efficiency across the entire supply chain. This isn’t just valuable for the customer – it allows logistics companies to see patterns at play that can be used to optimize their delivery strategies.
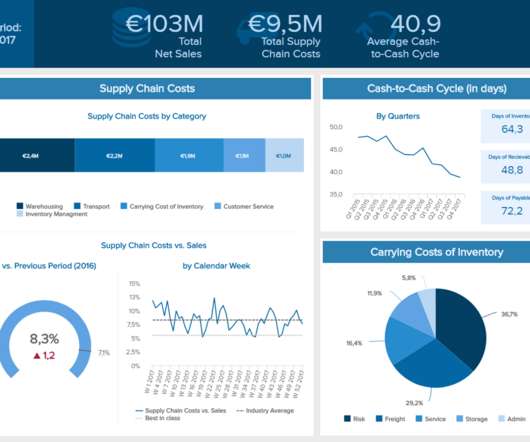
That’s why it’s critical to monitor and optimize relevant supply chain metrics. While there are numerous KPI examples you can select for your assessment and optimization, we have focused on a list that will enable you to identify potential bottlenecks and ensure sustainable development. Delivery Time.
Operational optimization and forecasting. Cost optimization. Another important factor to consider is cost optimization. Our procurement dashboard above is not only visually balanced but also offers a clear-cut snapshot of every vital metric you need to improve your procurement processes at a glance. Cost optimization.
While there are numerous types of dashboards that you can choose from to adjust and optimize your results, we have selected the top 3 that will tell you more about the story behind them. Such dashboards are extremely convenient to share the most important information in a snapshot. Let’s take a closer look.
This blog discusses a few problems that you might encounter with Iceberg tables and offers strategies on how to optimize them in each of those scenarios. Problem with too many snapshots Everytime a write operation occurs on an Iceberg table, a new snapshot is created. See Write properties.
Cloudinary is a cloud-based media management platform that provides a comprehensive set of tools and services for managing, optimizing, and delivering images, videos, and other media assets on websites and mobile applications.
Engagement: By obtaining access to a panoramic snapshot of your business’s entire customer service and support processes, you’ll be able to make vital improvements to your service levels, consumer touchpoints, content, and communications.
When you build your transactional data lake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 data lake to optimize the production environment. Update your-iceberg-storage-blog in the following configuration with the bucket that you created to test this example.
Companies such as Adobe , Expedia , LinkedIn , Tencent , and Netflix have published blogs about their Apache Iceberg adoption for processing their large scale analytics datasets. . In Iceberg, instead of listing O(n) partitions (directory listing at runtime) in a table for query planning, Iceberg performs an O(1) RPC to read the snapshot.
Whenever there is an update to the Iceberg table, a new snapshot of the table is created, and the metadata pointer points to the current table metadata file. At the top of the hierarchy is the metadata file, which stores information about the table’s schema, partition information, and snapshots. We use iceberg-blog-cluster.
To learn more about the features supported in each Apache Flink version, you can consult the Apache Flink blog , which discusses at length each of the Flink Improvement Proposals (FLIPs) incorporated into each of the versioned releases. This enables you to roll back your application statefully if issues occur during or after your upgrade.
Overview This blog post describes support for materialized views for the Iceberg table format. Queries containing joins, filters, projections, group-by, or aggregations without group-by can be transparently rewritten by the Hive optimizer to use one or more eligible materialized views.
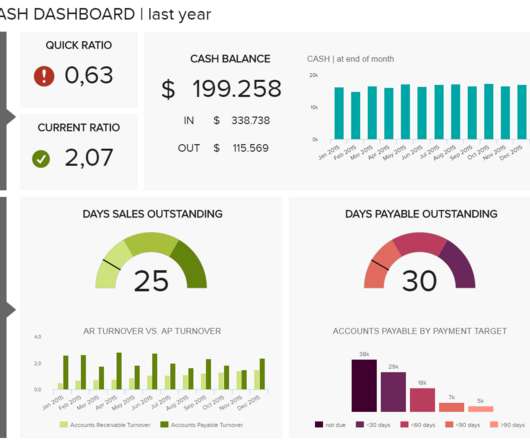
Usually, these reports are considered to be financial statements which include: a balance sheet: is a snapshot of a business at a specific time and shows the ending assets, liability, and equity balances as of the balance sheet date. The balance sheet is a snapshot of your business finances at a moment in time, showing assets and liabilities.
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera Data Warehouse with Iceberg. We will publish follow up blogs for other data services. Iceberg basics Iceberg is an open table format designed for large analytic workloads.
In this blog post we describe one of these instances — Google search deciding when to check if web pages have changed. Example: Recrawl Logic within Google search Google search works because our software has previously crawled many billions of web pages, that is, scraped and snapshotted each one.
Armed with powerful visualizations and real-time data, modern weekly summary reports enable businesses to closely monitor their performance and the progress of their strategies to extract relevant insights and optimize their processes to ensure constant growth. Your Chance: Want to build great weekly status reports on your own?
Plus, metrics like click-through-rate will also help you gauge how engaging or effective specific marketing initiatives are, allowing you to make the tweaks necessary for optimal promotional success. You need to keep an optimal number of available staff to take care of patients and make sure you don’t overburden your employees.
Hudi provides tables , transactions , efficient upserts and deletes , advanced indexes , streaming ingestion services , data clustering and compaction optimizations, and concurrency control , all while keeping your data in open source file formats. Read optimized queries – For MoR tables, queries see the latest data compacted.
This blog post will explore how zero-ETL capabilities combined with its new application connectors are transforming the way businesses integrate and analyze their data from popular platforms such as ServiceNow, Salesforce, Zendesk, SAP and others. Open the AWS Glue console.
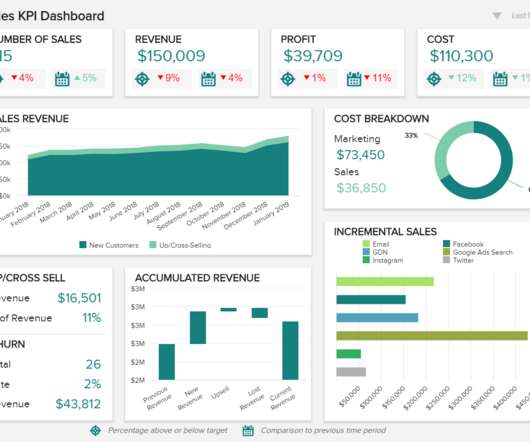
Analytics and sales should partner to forecast new business revenue and manage pipeline, because sales teams that have an analyst dedicated to their data and trends, drive insights that optimize workflows and decision making. Key ways to optimize insights for sales. Daily snapshot of opportunities – a summary.
It provides a brief snapshot of the entire business. I humbly believe the challenge is that in a world of too much data, with lots more on the way, there is a deep desire amongst executives to get "summarize data," to get "just a snapshot," or to get the "top-line view." digital performance. Standstill.
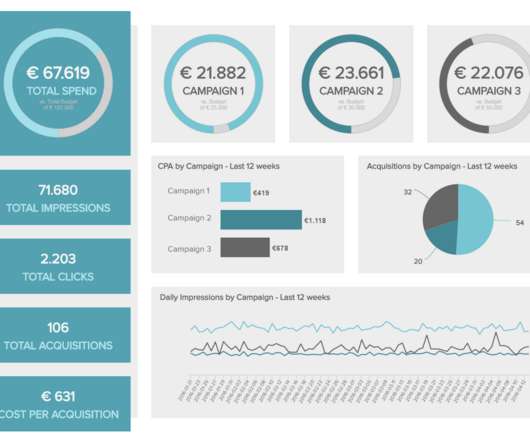
A procurement report allows an organization to demonstrate how its procurement activities deliver value for money, contribute to the realization of its broader goals and objectives, and provide a panoramic snapshot of the effectiveness of its procurement strategy. Manage your spend data. click to enlarge**.
Do they want to get more social reach on the blog posts your company is putting out? Make Sure Your Dashboard Is Mobile-Optimized. If you create dashboard designs that aren’t optimized across devices, you’re not using them to their fullest potential. Do they care about helping their staff get more sales and leads?
One of the most effective Twitter KPIs , the ‘top 5 Tweets’ metric offers a clear, concise, and digestible visual snapshot of your most engaging Tweets over a specific period of time. Globally, around 500 million Tweets are sent out every single day. 4) CPM of Twitter Ads. 6) Viewer retention. 8) Viewer information.
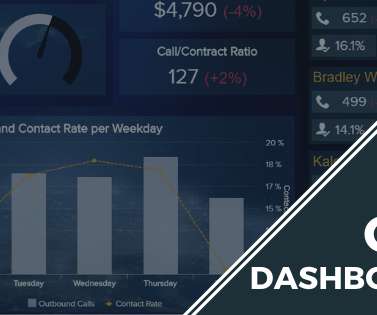
A call center dashboard is an intuitive visual reporting tool that displays a range of relevant call center metrics and KPIs that allow customer service managers and teams to monitor and optimize performance and spot emerging trends in a central location. To learn more and start your data-driven journey, try our 14-day trial – for free!
We had to identify the “optimal path” for customers without any information from the customer. Create a snapshot . Export the snapshot to the destination in the Cloud. Import the snapshot into the database. This meant intelligent automation behind the scenes. Enable replication.
OpenSearch Serverless optimizes resource use depending on the type you set. Snapshot management By default, OpenSearch Service takes hourly snapshots of your data with a retention time of 14 days. The automatic snapshots are incremental in nature and help you recover from data loss or cluster failure. and OpenSearch 2.7
A SaaS company report example that packs a real informational punch, this particular report format offers a panoramic snapshot of the insights and information every ambitious software-as-a-service business needs to succeed. click to enlarge**. You won’t regret it!
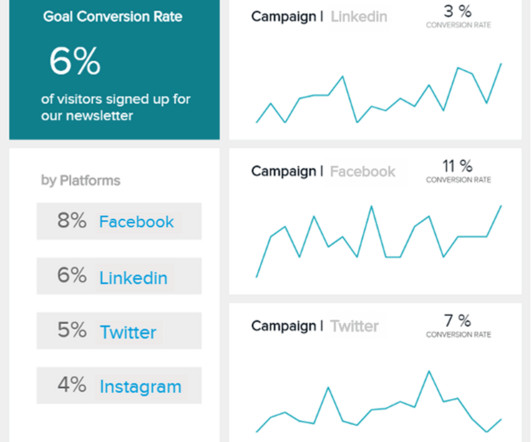
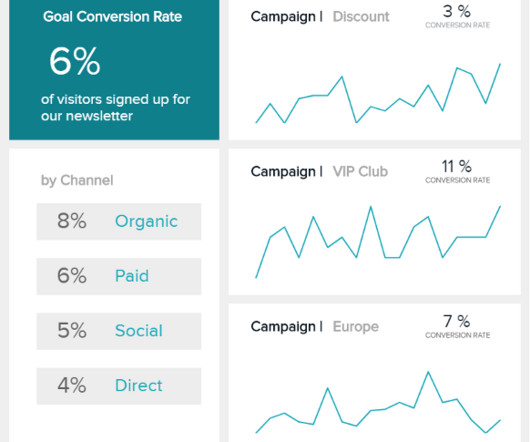
In many cases, your conversion goal will be the closing of a sale, but this particular type of metric can extend to email subscriptions from a specific piece of blog content, free trial sign-ups, or eBook downloads. In this case, it is being tracked by the marketing channel and observed for a 30-day period.
See the snapshot below. HDFS also provides snapshotting, inter-cluster replication, and disaster recovery. . For the examples presented in this blog, we assume you have a CDP account already. The solr.hdfs.home of the hdfs backup repository must be set to the bucket we want to place the snapshots. What does DDE entail?
Determining optimal table partitioning Determining optimal partitioning for each table is very important in order to optimize query performance and minimize the impact on teams querying the tables when partitioning changes. The following diagram illustrates the solution architecture. Orca addressed this in several ways.
Extracting business insights based on factual data and not just simple intuition will lead companies to optimize several processes and ensure sustainable development. The post Monthly Reports Templates & Examples To Monitor Business Performance appeared first on BI Blog | Data Visualization & Analytics Blog | datapine.
Drawing from the results of our “Cloudera Enterprise Data Maturity Report: Identifying the Impact of an Enterprise Data Strategy” survey, this series of 5 blog posts explores different ways in which a holistic, integrated enterprise data strategy enables businesses to realize desired outcomes, be it revenue, resilience or culture. .
In working with thousands of customers deploying Spark applications, we saw significant challenges with managing Spark as well as automating, delivering, and optimizing secure data pipelines. The post Cloudera Data Engineering 2021 Year End Review appeared first on Cloudera Blog. Test Drive CDP Pubic Cloud.
In this blog, I will describe a few strategies one could undertake for various use cases. They also provide a “ snapshot” procedure that creates an Iceberg table with a different name with the same underlying data. You could first create a snapshot table, run sanity checks on the snapshot table, and ensure that everything is in order.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content