This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern data architectures.
The Role of Catalog in DataSecurity. Recently, I dug in with CIOs on the topic of datasecurity. Recently, I dug in with CIOs on the topic of datasecurity. What came as no surprise was the importance CIOs place on taking a broader approach to data protection. What am I required to do?
Data is the most significant asset of any organization. However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture.
Amazon DataZone is a data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and from third-party sources.
Amazon Redshift supports querying data stored in Apache Iceberg tables managed by Amazon S3 Tables , which we previously covered as part of getting started blog post. Well also review an example with simultaneously using data that resides both in Amazon Redshift and Amazon S3 Tables, enabling a unified analytics experience.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. In addition, organizations rely on an increasingly diverse array of digital systems, data fragmentation has become a significant challenge.
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
To achieve this, they aimed to break down data silos and centralize data from various business units and countries into the BMW Cloud Data Hub (CDH). However, the initial version of CDH supported only coarse-grained access control to entire data assets, and hence it was not possible to scope access to data asset subsets.
The need to integrate diverse data sources has grown exponentially, but there are several common challenges when integrating and analyzing data from multiple sources, services, and applications. First, you need to create and maintain independent connections to the same data source for different services.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or data lake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud data warehouses.
Read the complete blog below for a more detailed description of the vendors and their capabilities. This is not surprising given that DataOps enables enterprise data teams to generate significant business value from their data. Testing and Data Observability. Download the 2021 DataOps Vendor Landscape here.
The data mesh design pattern breaks giant, monolithic enterprise data architectures into subsystems or domains, each managed by a dedicated team. DataOps helps the data mesh deliver greater business agility by enabling decentralized domains to work in concert. . But first, let’s define the data mesh design pattern.
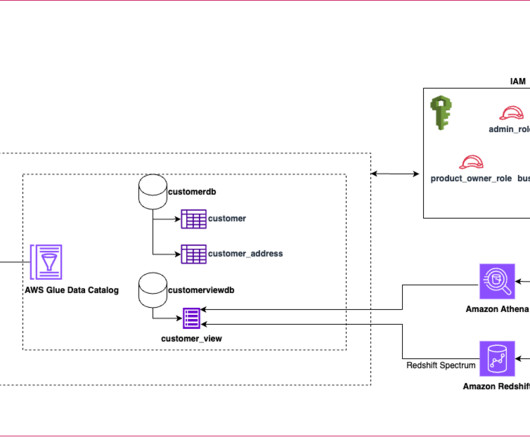
Today’s data lakes are expanding across lines of business operating in diverse landscapes and using various engines to process and analyze data. Traditionally, SQL views have been used to define and share filtered data sets that meet the requirements of these lines of business for easier consumption.
Many of these are unsurprising: you can ask it to write a letter, you can ask it to make up a story, you can ask it to write descriptive entries for products in a catalog. Many of these are unsurprising: you can ask it to write a letter, you can ask it to make up a story, you can ask it to write descriptive entries for products in a catalog.
In today’s data-driven world, the ability to seamlessly integrate and utilize diverse data sources is critical for gaining actionable insights and driving innovation. Use case Consider a large ecommerce company that relies heavily on data-driven insights to optimize its operations, marketing strategies, and customer experiences.
As they continue to implement their Digital First strategy for speed, scale and the elimination of complexity, they are always seeking ways to innovate, modernize and also streamline data access control in the Cloud. BMO has accumulated sensitive financial data and needed to build an analytic environment that was secure and performant.
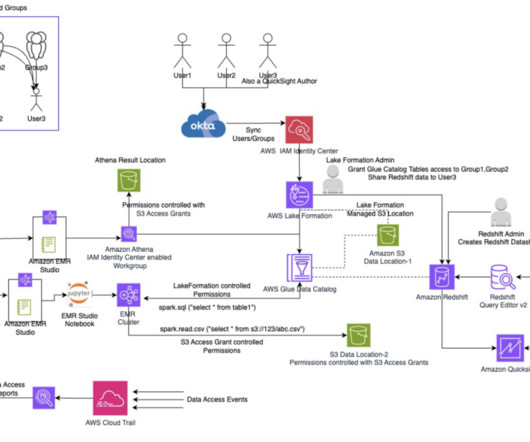
Data lakes have been gaining popularity for storing vast amounts of data from diverse sources in a scalable and cost-effective way. As the number of data consumers grows, data lake administrators often need to implement fine-grained access controls for different user profiles.
To enable them to use the AWS services, their identities from the external IdP are mapped to AWS Identity and Access Management (IAM) roles within AWS, and access policies are applied to these IAM roles by data administrators. Additionally, this user builds Amazon QuickSight visualizations for the data in Redshift tables.
Over the years, organizations have invested in creating purpose-built, cloud-based data lakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple data lakes, each built on different technology stacks.
Organizations with a solid understanding of data governance (DG) are better equipped to keep pace with the speed of modern business. In this post, the erwin Experts address: What Is Data Governance? Why Is Data Governance Important? What Is Good Data Governance? What Are the Key Benefits of Data Governance?
Director of Product, Salesforce Data Cloud. In today’s ever-evolving business landscape, organizations must harness and act on data to fuel analytics, generate insights, and make informed decisions to deliver exceptional customer experiences. What is Salesforce Data Cloud? This post is co-authored by Rajkumar Irudayaraj, Sr.
Remote working has revealed the inconsistency and fragility of workflow processes in many data organizations. The data teams share a common objective; to create analytics for the (internal or external) customer. Data Science Workflow – Kubeflow, Python, R. Data Engineering Workflow – Airflow, ETL.
Apache Hudi is an open table format that brings database and data warehouse capabilities to data lakes. Apache Hudi helps data engineers manage complex challenges, such as managing continuously evolving datasets with transactions while maintaining query performance.
Today, we’re making available a new capability of AWS Glue DataCatalog that allows generating column-level statistics for AWS Glue tables. Data lakes are designed for storing vast amounts of raw, unstructured, or semi-structured data at a low cost, and organizations share those datasets across multiple departments and teams.
The company uses AWS Cloud services to build data-driven products and scale engineering best practices. To ensure a sustainable data platform amid growth and profitability phases, their tech teams adopted a decentralized data mesh architecture.
We’ve read many predictions for 2023 in the data field: they cover excellent topics like data mesh, observability, governance, lakehouses, LLMs, etc. What will the world of data tools be like at the end of 2025? Central IT Data Teams focus on standards, compliance, and cost reduction. Recession: the party is over.
In today’s data-driven world, the ability to effortlessly move and analyze data across diverse platforms is essential. Amazon AppFlow , a fully managed data integration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery.
These business units have varying landscapes, where a data lake is managed by Amazon Simple Storage Service (Amazon S3) and analytics workloads are run on Amazon Redshift , a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data.
Data governance (DG) as a an “emergency service” may be one critical lesson learned coming out of the COVID-19 crisis. Where crisis leads to vulnerability, data governance as an emergency service enables organization management to direct or redirect efforts to ensure activities continue and risks are mitigated.
In the data-driven era, CIO’s need a solid understanding of data governance 2.0 … Data governance (DG) is no longer about just compliance or relegated to the confines of IT. Today, data governance needs to be a ubiquitous part of your organization’s culture. Creating a Culture of Data Governance.
Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback. and later supports the Apache Iceberg framework for data lakes. Apache Iceberg is designed to support these features on cost-effective petabyte-scale data lakes on Amazon S3.
Customers of all sizes and industries use Amazon Simple Storage Service (Amazon S3) to store data globally for a variety of use cases. Customers want to know how their data is being accessed, when it is being accessed, and who is accessing it. With exponential growth in data volume, centralized monitoring becomes challenging.
Amazon DataZone enables customers to discover, access, share, and govern data at scale across organizational boundaries, reducing the undifferentiated heavy lifting of making data and analytics tools accessible to everyone in the organization. This is challenging because access to data is managed differently by each of the tools.
AWS Data Pipeline helps customers automate the movement and transformation of data. With Data Pipeline, customers can define data-driven workflows, so that tasks can be dependent on the successful completion of previous tasks. Some customers want a deeper level of control and specificity than possible using Data Pipeline.
This is a guest blog post co-authored with Atul Khare and Bhupender Panwar from Salesforce. It runs miscellaneous services to facilitate investigation, mitigation, and containment for security operations. The platform ingests more than 1 PB of data per day, more than 10 million events per second, and more than 200 different log types.
In light of recent, high-profile data breaches, it’s past-time we re-examined strategic data governance and its role in managing regulatory requirements. for alleged violations of the European Union’s General Data Protection Regulation (GDPR). Given this, Oppenheimer & Co. Complexity.
In today’s world, customers manage vast amounts of data in their Amazon Simple Storage Service (Amazon S3) data lakes, which requires convoluted data pipelines to continuously understand the changes in the data layout and make them available to consuming systems.
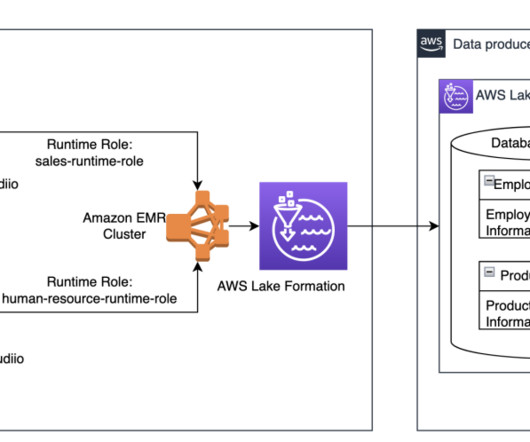
Amazon EMR Studio is an integrated development environment (IDE) that makes it straightforward for data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark. We’re happy to introduce runtime roles for EMR Studio Workspaces.
This allows you to simplify security and governance over transactional data lakes by providing access controls at table-, column-, and row-level permissions with your Apache Spark jobs. Many large enterprise companies seek to use their transactional data lake to gain insights and improve decision-making.
Data intelligence has a critical role to play in the supercomputing battle against Covid-19. While leveraging supercomputing power is a tremendous asset in our fight to combat this global pandemic, in order to deliver life-saving insights, you really have to understand what data you have and where it came from.
In today’s rapidly evolving digital landscape, enterprises across regulated industries face a critical challenge as they navigate their digital transformation journeys: effectively managing and governing data from legacy systems that are being phased out or replaced.
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized datacatalog.
Last week, we announced the general availability of custom AWS service blueprints , a new feature in Amazon DataZone allowing you to customize your Amazon DataZone project environments to use existing AWS Identity and Access Management (IAM) roles and AWS services to embed the service into your existing processes.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content