This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The release of a new full version always comes with an exciting list of new functionalities. of Ontotext’s GraphDB has lots of new bells and whistles that will ensure that it remains the market leader for semantic databases. Ontotext has increased its commitment to open-source with this major redesign of the Plugin API.
In our previous blog post of the series, we covered how to ingest data from different sources into GraphDB , validate it and infer new knowledge from the extant facts. With the great data integration powers of GraphDB, LAZY has achieved a lot. Now LAZY has to get all that disparate data and store it into GraphDB.
Through this series of blog posts, we’ll discuss how to best scale and branch out an analytics solution using a knowledge graph technology stack. Our main weapons when beating that beast will be GraphDB , Ontotext Platform , Kafka , Elasticsearch , Kibana and Jupyter. After all, no one wants their new office collapsing on their heads.
In 2019, Ontotext open-sourced the front-end and engine plugins of GraphDB to make the development and operation of knowledge graphs easier and richer. Our analytics shows that in 2019 (just as in 2018), the knowledge graph remains the unrivaled star of our most popular blog posts. We also released Ontotext Platform 3.0
Or to browse repositories by asking questions like “What were the new odours that appeared during the Industrial revolution?” Or to browse repositories by asking questions like “What were the new odours that appeared during the Industrial revolution?” But what about questions related to intangibles? What if we told you could?
It also allows us to put the new features of our products into a real-world use case right away. Doing so we become early adopters, gather instant feedback from our internal users, and use it to improve our products further. We store this in GraphDB by leveraging standard tooling for knowledge graph management. What is OTKG?
Our blog post GraphDB Cluster Deployment Strategies explained how to deploy a high-availability GraphDB cluster. Ontotext collaborates with major cloud providers, Azure and AWS, to offer the GraphDB high-availability cluster either as a managed service in Ontotext’s account or in the customer’s account.
In this article, we argue that a knowledge graph built with semantic technology (the type of Ontotext’s GraphDB) improves the way enterprises operate in an interconnected world. Such an approach, no matter what name we use for it, is all about improving the way enterprises operate in an interconnected world.
We have already explained how to deploy GraphDB in a generic environment and on Azure. This post will guide you through deploying GraphDB in your AWS account using our Terraform scripts. This post will guide you through deploying GraphDB in your AWS account using our Terraform scripts. Ontotext does not stop here, of course.
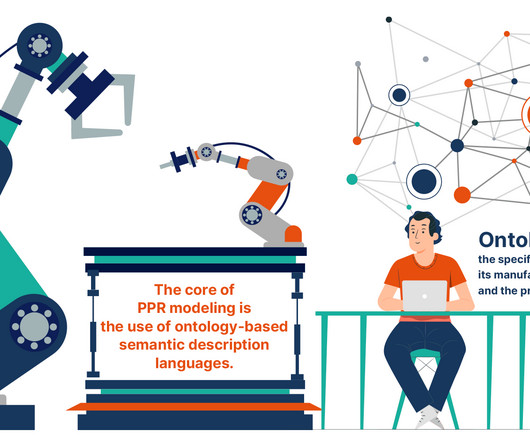
This blog post delves into the PPR modeling paradigm, highlighting its significance and application in robot-based automation. Scalability : Supporting the expansion of knowledge bases as new products, processes, and resources are introduced. What is the PPR Modeling Paradigm?
This blog post will present a NLQ integration for Ontotext GraphDB in LangChain: a framework designed to simplify the creation of applications using LLMs. The diagram above offers a high-level overview of how NLQ for GraphDB works in LangChain. If the generated query is a valid SPARQL query, then it is executed against GraphDB.
Ontotext Platform synergizes knowledge graphs and text analysis as follows: Knowledge graphs can improve text analysis performance. Text analysis can extract new concepts and relationships, which can be added to enrich a knowledge graph with information not available from structure sources. nouns, verbs, adjectives, etc.)
In this post, which is a matured version of my opening keynote at Ontotext’s Knowledge Graph Forum 2023 , I will start with evidence about the impact of complexity on the growth and efficiency of big enterprises. This requires new tools and new systems, which results in diverse and siloed data.
This blog post goes through the basics of the joint solution delivered by Ontotext and metaphacts to speed up this journey. GraphDB & metaphactory Working Hand in Hand. At the heart of our solution are Ontotext’s GraphDB and metaphacts’ metaphactory. Common Challenges in Knowledge Graph Projects.
Every new dataset and new user adds a little more friction that hits the core metric of the velocity of data and brings it down to zero. Particularly those on the “the create side of the house” who are tasked to deliver insights and analytics. The result is issues in discovery as well as consistency across applications.
Humans are stuck on this planet until they devised a way to travel, 11kms per second, the escape velocity from Earth. It’s only been very recently that humans figured out how to go that fast. It’s hard and it’s expensive. According to this article , it costs $54,500 for every kilogram you want into space. How did they do it?
Bikes to the moon The event opened with Atanas Kiryakov who invited us to consider that getting to the moon on a bike is impossible unless you have a really well-tuned bike. ” With new business lines, leading to new tools, a lot of diverse and siloed data inevitably enters enterprise systems.
Such an approach, no matter what name we use for it, is all about improving the way enterprises operate in an interconnected world. Examples of such continuous improvement are technological giants like Google and Amazon who use semantic technology principles to build better data architectures for better user experiences.
The Open Science (or Open Scholarship) movement has been gaining momentum, especially since the European Commission has committed itself to ensuring open access to all funded research in April 2016. Ontotext’s knowledge graph-based technologies are seen as a key to realizing the benefits of Open Science.
In this blog post, we dive into the capabilities of Ontotext’s semantic technology products and solutions that facilitate NLQ. Let’s see how we can achieve our own RAG using Ontotext’s RDF database GraphDB. This dramatically simplifies the interaction with complex databases and analytics systems.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content