This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In part 1 of this blog post, we discussed the need to be mindful of data bias and the resulting consequences when certain parameters are skewed. Systems should be designed with bias, causality and uncertainty in mind. Even if protected features are removed, they can often be inferred from the presence of proxy features.
by KAY BRODERSEN For the first time in the history of statistics, recent innovations in big data might allow us to estimate fine-grained causal effects, automatically and at scale. How can we establish that there is a causal link between our idea and the outcome metric we care about? Causalinference at scale may be one such key.
The paradox can be resolved by better understanding the data — exploring how it was generated and identifying the lurking variable. To better understand when the data should be grouped, you should be familiar with causalinference. This drug seems to be bad for women, bad for men, but good for people!”.
By MUKUND SUNDARARAJAN, ANKUR TALY, QIQI YAN Editor's note: Causalinference is central to answering questions in science, engineering and business and hence the topic has received particular attention on this blog. In this post, we explore causalinference in this setting via the problem of attribution in deep networks.
However, if one changes assignment weights when there are time-based confounders, then ignoring this complexity can lead to biased inference in an OCE. Just as in ramp-up, making inferences while ignoring the complexity of time-based confounders that are present can lead to biased estimates. Y_i=Y_i(t)$ if $T_i=t$.
We can estimate the causal effect of prominence as the difference in log odds of uptake between stories which were recommended and those which were eligible (i.e. The former approach will tend to produce more realistic outcomes, but can be harder to understand, and may not give us adequate data to assess unlikely decisions.
In the past year, we’ve released research reports and prototypes exploring Deep Learning for Anomaly Detection , Causality for Machine Learning and NLP for Automated Question Answering. textbooks, and understanding potential applications and limitations by prototyping. . Evolving Research At Cloudera Fast Forward.
This blog post provides details for how we can make inferences without waiting for complete uptake. Background At Google, experimentation is an invaluable tool for making decisions and inference about new products and features. In any case, it is clear that we cannot make inference without some caution in this case.
Some of that uncertainty is the result of statistical inference, i.e., using a finite sample of observations for estimation. This blog post introduces the notions of representational uncertainty and interventional uncertainty to paint a fuller picture of what the practicing data scientist is up against. For instance, fluff.ai
Obvious: No CxO understands the story we are trying to tell – or, even the fundamentals of what we do in the world of analytics. You see… None of the currently recommended frameworks and maturity models aids analytics leaders in truly understanding the bottom line impact of their work. The Implications of Complexity. The Impact Matrix.
By JEAN STEINER Randomized A/B experiments are the gold standard for estimating causal effects. This blog post explores how this problem arises in applications at Google, and how we can 'mind our units' through analysis and logging. The plot shows how ignoring the group structure (red) leads to increasingly optimistic inferences (i.e.,
by NIALL CARDIN, OMKAR MURALIDHARAN, and AMIR NAJMI When working with complex systems or phenomena, the data scientist must often operate with incomplete and provisional understanding, even as she works to advance the state of knowledge. We’re not going to engage in this debate but in this blog post we do focus on science.
This allows researchers to connect genetic information from NCBI Gene with protein data from UniProt, facilitating a more holistic understanding of gene-protein interactions. Metadata is crucial for data discovery, understanding, and management.
This allows researchers to connect genetic information from NCBI Gene with protein data from UniProt, facilitating a more holistic understanding of gene-protein interactions. Metadata is crucial for data discovery, understanding, and management.
For us, demand for forecasts emerged from a determination to better understand business growth and health, more efficiently conduct day-to-day operations, and optimize longer-term resource planning and allocation decisions. Forecasting" for us also did not mean using time series in a causalinference setting. OTexts, 2014.
Implicitly, there was a prior belief about some interesting causal mechanism or an underlying hypothesis motivating the collection of the data. Understanding the goals of the organization as well as guiding principles for extracting value from data are both critical for success in this environment. And for good reason! Is it real?
IMO, the theme here is to shift more of the deeper aspects of inference – such as explainability, auditability, trust, etc. Instead, consider a “full stack” tracing from the point of data collection all the way out through inference. Finale Doshi-Velez, Been Kim (2017-02-28) ; see also the Domino blog article about TCAV.
Indeed, understanding and facilitating user choices through improvements in the service offering is much of what LSOS data science teams do. A particularly attractive approach to understanding user behavior in online services is live experimentation. To understand this better we need a few definitions.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




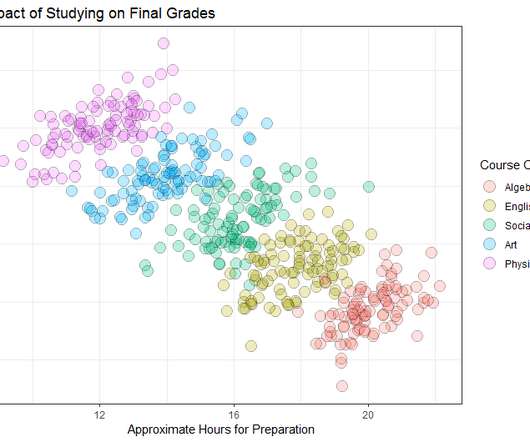





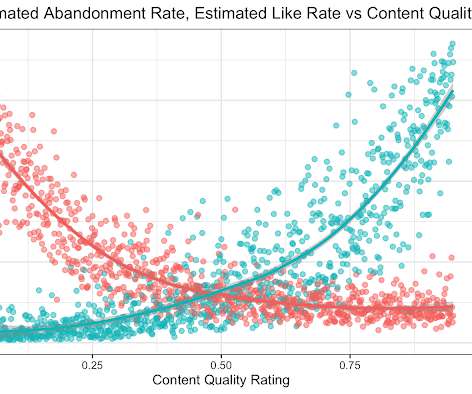













Let's personalize your content