This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern data architectures.
We are excited to announce the acquisition of Octopai , a leading data lineage and catalog platform that provides data discovery and governance for enterprises to enhance their data-driven decision making.
Amazon Redshift supports querying data stored in Apache Iceberg tables managed by Amazon S3 Tables , which we previously covered as part of getting started blog post. Well also review an example with simultaneously using data that resides both in Amazon Redshift and Amazon S3 Tables, enabling a unified analytics experience.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. In addition, organizations rely on an increasingly diverse array of digital systems, data fragmentation has become a significant challenge.
What attributes of your organization’s strategies can you attribute to successful outcomes? Do you converse with your employees about decisions that might be the converse of what they would expect? What you have just experienced is a plethora of heteronyms. Before we start, I have a few questions for you. Can you find them all?
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or data lake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
Below is our third post (3 of 5) on combining data mesh with DataOps to foster greater innovation while addressing the challenges of a decentralized architecture. We’ve talked about data mesh in organizational terms (see our first post, “ What is a Data Mesh? ”) and how team structure supports agility.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud data warehouses. large instances.
Is Your Team in Denial of Data Quality? Here’s How to Tell In many organizations, data quality problems fester in the shadowsignored, rationalized, or swept aside with confident-sounding statements that mask a deeper dysfunction. That doesn’t mean the data inside was correct. A pipeline ran “all green”?
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
Third, any commitment to a disruptive technology (including data-intensive and AI implementations) must start with a business strategy. I suggest that the simplest business strategy starts with answering three basic questions: What? That is: (1) What is it you want to do and where does it fit within the context of your organization?
Enterprise data is brought into data lakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Can it also help write SQL queries? The answer is yes. The solution architecture and workflow.
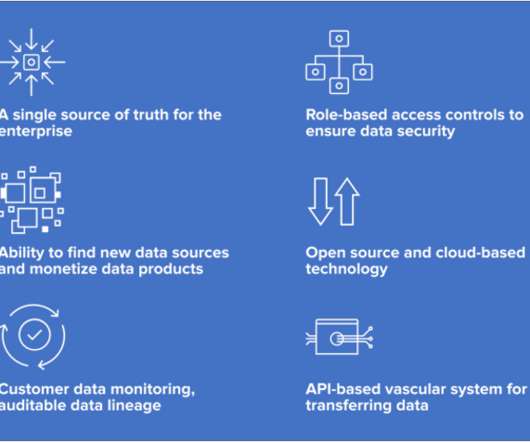
No matter where data comes from, becoming data-driven depends on every member of your organization being able to find, access, and use the data they need.
What is it, how does it work, what can it do, and what are the risks of using it? Many of these are unsurprising: you can ask it to write a letter, you can ask it to make up a story, you can ask it to write descriptive entries for products in a catalog. What Software Are We Talking About? It’s much more.
The data mesh design pattern breaks giant, monolithic enterprise data architectures into subsystems or domains, each managed by a dedicated team. DataOps helps the data mesh deliver greater business agility by enabling decentralized domains to work in concert. . But first, let’s define the data mesh design pattern.
Read the complete blog below for a more detailed description of the vendors and their capabilities. This is not surprising given that DataOps enables enterprise data teams to generate significant business value from their data. Testing and Data Observability. Download the 2021 DataOps Vendor Landscape here.
Industry analysts who follow the data and analytics industry tell DataKitchen that they are receiving inquiries about “data fabrics” from enterprise clients on a near-daily basis. Gartner included data fabrics in their top ten trends for data and analytics in 2019. What is a Data Fabric?
We wanted to find out what people are actually doing, so in September we surveyed O’Reilly’s users. Our survey focused on how companies use generative AI, what bottlenecks they see in adoption, and what skills gaps need to be addressed. AI users say that AI programming (66%) and data analysis (59%) are the most needed skills.
So if you’re going to move from your data from on-premise legacy data stores and warehouse systems to the cloud, you should do it right the first time. And as you make this transition, you need to understand whatdata you have, know where it is located, and govern it along the way. Then you must bulk load the legacy data.
When it comes to using AI and machine learning across your organization, there are many good reasons to provide your data and analytics community with an intelligent data foundation. For instance, Large Language Models (LLMs) are known to ultimately perform better when data is structured.
If you’re serious about a data-driven strategy , you’re going to need a datacatalog. Organizations need a datacatalog because it enables them to create a seamless way for employees to access and consume data and business assets in an organized manner. Three Types of Metadata in a DataCatalog.
Organizations with a solid understanding of data governance (DG) are better equipped to keep pace with the speed of modern business. In this post, the erwin Experts address: What Is Data Governance? Why Is Data Governance Important? What Is Good Data Governance? What Are the Key Benefits of Data Governance?
Recently, we announced enhanced multi-function analytics support in Cloudera Data Platform (CDP) with Apache Iceberg. Iceberg is a high-performance open table format for huge analytic data sets. This enables you to maximize utilization of streaming data at scale. The Catalog Type should be set to Hive.
A constant flow of breaking news from the data lakehouse space is making notable tech headlines this week. On Tuesday, Databricks announced that it will acquire Tabular, a data management company founded by the creators of Apache Iceberg, Ryan Blue, Daniel Weeks, and Jason Reidfor. How Open is Your Open Source?
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and data architecture and views the data organization from the perspective of its processes and workflows.
Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback. Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback. AWS Glue 3.0
Open table formats are emerging in the rapidly evolving domain of big data management, fundamentally altering the landscape of data storage and analysis. By providing a standardized framework for data representation, open table formats break down data silos, enhance data quality, and accelerate analytics at scale.
Amazon DataZone enables customers to discover, access, share, and govern data at scale across organizational boundaries, reducing the undifferentiated heavy lifting of making data and analytics tools accessible to everyone in the organization. This is challenging because access to data is managed differently by each of the tools.
We just announced Cloudera DataFlow for the Public Cloud (CDF-PC), the first cloud-native runtime for Apache NiFi data flows. In this blog post we’re revisiting the challenges that come with running Apache NiFi at scale before we take a closer look at the architecture and core features of CDF-PC.
As organizations deal with managing ever more data, the need to automate data management becomes clear. Last week erwin issued its 2020 State of Data Governance and Automation (DGA) Report. One piece of the research that stuck with me is that 70% of respondents spend 10 or more hours per week on data-related activities.
Teams need to urgently respond to everything from massive changes in workforce access and management to what-if planning for a variety of grim scenarios, in addition to building and documenting new applications and providing fast, accurate access to data for smart decision-making. Data Modeling. Data Governance.
To simplify data access and empower users to leverage trusted information, organizations need a better approach that provides better insights and business outcomes faster, without sacrificing data access controls. There are many different approaches, but you’ll want an architecture that can be used regardless of your data estate.
This is part of our series of blog posts on recent enhancements to Impala. Apache Impala is synonymous with high-performance processing of extremely large datasets, but what if our data isn’t huge? What if our queries are very selective? It turns out that Apache Impala scales down with data just as well as it scales up.
Director of Product, Salesforce Data Cloud. In today’s ever-evolving business landscape, organizations must harness and act on data to fuel analytics, generate insights, and make informed decisions to deliver exceptional customer experiences. What is Salesforce Data Cloud? What is Amazon Redshift?
Since then, we have been working hard to expose the full power of Apache Flink SQL and the existing Data Warehousing tools in CDP to combine it into a state-of-the-art real-time analytics platform. Flink SQL DDL and Catalog support. Catalog Integrations. This step significantly speeds up query development and data exploration.
When an organization’s data governance and metadata management programs work in harmony, then everything is easier. Data governance is a complex but critical practice. There’s always more data to handle, much of it unstructured; more data sources, like IoT, more points of integration, and more regulatory compliance requirements.
Many datacatalog initiatives fail. How can prospective buyers ensure they partner with the right catalog to drive success? According to the latest report from Eckerson Group, Deep Dive on DataCatalogs , shoppers must match the goals of their organizations to the capabilities of their chosen catalog.
Performance is one of the key, if not the most important deciding criterion, in choosing a Cloud Data Warehouse service. In today’s fast changing world, enterprises have to make data driven decisions quickly and for that they rely heavily on their data warehouse service. . Cloudera Data Warehouse vs HDInsight.
The cloud supports this new workforce, connecting remote workers to vital data, no matter their location. And what are the benefits? Data Cloud Migration Challenges and Solutions. Cloud migration is the process of moving enterprise data and infrastructure from on premise to off premise. But why migrate at all?
Customers of all sizes and industries use Amazon Simple Storage Service (Amazon S3) to store data globally for a variety of use cases. Customers want to know how their data is being accessed, when it is being accessed, and who is accessing it. With exponential growth in data volume, centralized monitoring becomes challenging.
In a previous blog post on CDW performance, we compared Azure HDInsight to CDW. In this blog post, we compare Cloudera Data Warehouse (CDW) on Cloudera Data Platform (CDP) using Apache Hive-LLAP to EMR 6.0 (also powered by Apache Hive-LLAP) on Amazon using the TPC-DS 2.9 More on this later in the blog.
In the era of big data, data lakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
Over the years, organizations have invested in creating purpose-built, cloud-based data lakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple data lakes, each built on different technology stacks.
Data flows are an integral part of every modern enterprise. At Cloudera, we’re helping our customers implement data flows on-premises and in the public cloud using Apache NiFi , a core component of Cloudera DataFlow. In this blog post, I want to share the top three requirements for data flows in 2021 that we hear from our customers.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content