This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Generative AI is the biggest and hottest trend in AI (Artificial Intelligence) at the start of 2023. Third, any commitment to a disruptive technology (including data-intensive and AI implementations) must start with a business strategy. In short, you must be willing and able to answer the seven WWWWWH questions (Who?
What attributes of your organization’s strategies can you attribute to successful outcomes? Do you converse with your employees about decisions that might be the converse of what they would expect? What you have just experienced is a plethora of heteronyms. This is accomplished through tags, annotations, and metadata (TAM).
Introduction In the real world, obtaining high-quality annotateddata remains a challenge. Generative AI (GenAI) models, such as GPT-4, offer a promising solution, potentially reducing the dependency on labor-intensive annotation. Your goal is to extract entities with types: Person, Organisation, Location.
We stand on the frontier of an AI revolution. Over the past decade, deep learning arose from a seismic collision of data availability and sheer compute power, enabling a host of impressive AI capabilities. It sounds like a joke, but it’s not, as anyone who has tried to solve business problems with AI may know.
This post is for people making technology decisions, by which I mean data science team leads, architects, dev team leads, even managers who are involved in strategic decisions about the technology used in their organizations. and you’re wondering what it is, this post is for you. this post on the Ray project blog ?.
With advanced analytics, flexible dashboarding and effective data visualization, FP&A storytelling has become both an art and science. You can find a blog post version of my commentary below, and a draft video of my section: What’s new with analytics and storytelling for finance teams? What typically goes wrong?
The word “data” is ubiquitous in narratives of the modern world. And data, the thing itself, is vital to the functioning of that world. This blog discusses quantifications, types, and implications of data. Quantifications of data. Quantifications of data. So data is big and growing.
Generative AI is powering a new world of creative, customized communications, allowing marketing teams to deliver greater personalization at scale and meet today’s high customer expectations. Enterprise marketing teams stand to benefit greatly from generative AI, yet introduction of this capability will require new skills and processes.
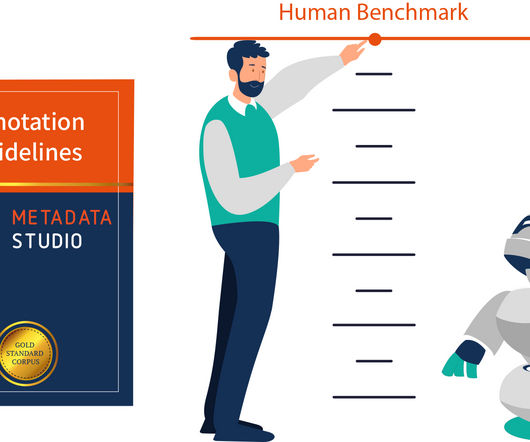
Assessing the abilities of Artificial Intelligence (AI) systems is a critical aspect of development that has become increasingly important as AI has expanded into various areas of application. We can evaluate their performance through comparisons to human benchmarks, to other AI systems or a combination of both.
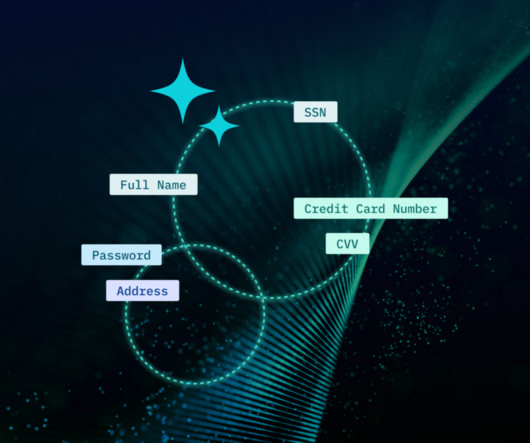
In the ever-evolving digital landscape, the importance of data discovery and classification can’t be overstated. As we generate and interact with unprecedented volumes of data, the task of accurately identifying, categorizing, and utilizing this information becomes increasingly difficult.
But, as Ontotext’s CEO Atanas Kiryakov often says, we forget that nobody nurtures the Artificial Intelligence (AI) systems for 7 years to learn how to walk, talk, count, read, write and, even more important, not touch hot stoves and avoid tilting full glasses and asking: Can I get 3 more cookies? What do AI systems need to learn?
Sometimes the problem with artificial intelligence (AI) and automation is that they are too labor intensive. Traditional AI tools, especially deep learning-based ones, require huge amounts of effort to use. You need to collect, curate, and annotatedata for any specific task you want to perform.
As datasets become bigger and more complex, only AI, materialized views, and more sophisticated coding languages will be able to glean insights from them. A data scientist must be skilled in many arts: math and statistics, computer science, and domain knowledge. Statistical techniques to handle nontrivial data.
Foundational models (FMs) are marking the beginning of a new era in machine learning (ML) and artificial intelligence (AI) , which is leading to faster development of AI that can be adapted to a wide range of downstream tasks and fine-tuned for an array of applications.
Ever since Hippocrates founded his school of medicine in ancient Greece some 2,500 years ago, writes Hannah Fry in her book Hello World: Being Human in the Age of Algorithms , what has been fundamental to healthcare (as she calls it “the fight to keep us healthy”) was observation, experimentation and the analysis of data.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. What is machine learning? the target or outcome variable is known).
We as a taxonomy community are facing rapid technological change and grappling with where our discipline fits into a world captivated by ChatGPT and other generative models. The challenge of complexity Knowledge models for taxonomy have responded to an increasing need for sophistication and expressiveness.
What is OTKG? OTKG models information about Ontotext, combined with content produced by different teams inside the organization. We started with our marketing content and quickly expanded that to also integrate a set of workflows for data and content management. Where does AI fit into this?
Today, the rate of data volume increase is similar to the rate of decrease in sequencing cost. Processing terabytes or even petabytes of increasing complex omics data generated by NGS platforms has necessitated development of omics informatics. What is Amazon Omics?
This is part of Ontotext’s AI-in-Action initiative aimed at enabling data scientists and engineers to benefit from the AI capabilities of our products. We have experimented with different models that enable linking to Wikidata. Since they meet our requirements, we’ve chosen them as our primary target knowledge base.
Have you ever been in a conversation where someone mentioned a “knowledge graph,” only to realize that their description was completely different from what you had in mind? What is a knowledge graph? An ontology enriches data within a knowledge graph with context and meaning that humans and computers can interpret.
This is part of Ontotext’s AI-in-Action initiative aimed at enabling data scientists and engineers to benefit from the AI capabilities of our products. Have you ever tried to find out what your medical records say after a doctor’s visit? Even for a human, this task is difficult to solve.
Addressing the Key Mandates of a Modern Model Risk Management Framework (MRM) When Leveraging Machine Learning . The regulatory guidance presented in these documents laid the foundation for evaluating and managing model risk for financial institutions across the United States.
In Computer Science, we are trained to use the Okham razor – the simplest model of reality that can get the job done is the best one. Next, I will explain how knowledge graphs help them to get a unified view to data derived from multiple sources and get richer insights in less time.
As such, we are witnessing a revolution in the healthcare industry, in which there is now an opportunity to employ a new model of improved, personalized, evidence and data-driven clinical care. Additionally, organizations are increasingly restrained due to budgetary constraints and having limited data sciences resources.
Faster R-CNN is a single-stage model that is trained end-to-end. Here are some examples: In the above image, the green boxes are the Ground Truth, while the red boxes are what the first cut solution could detect. Several architecture firms work with community development companies to ensure safety and regulatory compliance.
What is the future of knowledge graphs in the era of ChatGPT and Large Language Models? To start with, Large Language Models (LLM) will not replace databases. They are good for compressing information, but one cannot retrieve from such a model the same information that it got trained on.
Generating actionable insights across growing data volumes and disconnected data silos is becoming increasingly challenging for organizations. Working across data islands leads to siloed thinking and the inability to implement critical business initiatives such as Customer, Product, or Asset 360. Data Fabric: Who and What?
Creating those plans require ingesting massive amounts of data resources, aggregating, cleansing, and standardizing that data, and then performing analysis on the finished product. That’s because Microsoft Excel is still the go-to tool for performing all of that data prep. AI, on the other hand, doesn’t miss a thing. .
Gartner predicts that graph technologies will be used in 80% of data and analytics innovations by 2025, up from 10% in 2021. Use Case #1: Customer 360 / Enterprise 360 Customer data is typically spread across multiple applications, departments, and regions. Several factors are driving the adoption of knowledge graphs.
and discern what’s behind it. With that said, recent advances in deep learning methods have allowed models to improve to a point that is quickly approaching human precision on this difficult task. The first step in developing any model is gathering a suitable source of training data, and sentiment analysis is no exception.
Image credit: [link] As the title suggests, this is a story about a question that may resonate well with many machine learning practitioners trying to build applications in the real world, where clean and annotateddata on a specific problem can be sparse— How do we leverage the power of AI when we have very little data?
This is part of Ontotext’s AI-in-Action initiative aimed at enabling data scientists and engineers to benefit from the AI capabilities of our products. What’s the difference between a graph and a knowledge graph? You can play with this service interactively at [link].
To prevent costly product recalls, excessive scrap, re-work and other costs associated with poor quality, companies look to automate inspections and identify weld defects early and consistently. The unsung heroes Welding is the fusion of two compounds with heat. The chair you’re sitting in while reading this likely has dozens of welds.
Image by Gerd Altmann from Pixabay Assisted annotation and other automation methods that can be used for knowledge graph creation and natural language understanding should be more flexible and iterative than they often are. A well-designed knowledge graph describes the contexts or domains of the data it contains.
Introduction Whether you are in the position of Sherlock Holmes, a data analyst, or a business manager, its always useful to augment your vision of the available data to derive better insights. An intelligent assistant is a handy way to reveal the knowledge locked in the tangled hairball of data.
Making Sense of Messy Data. One of the big challenges for the scientific community in the current situation is the vast volume of data that is constantly produced from various sources in several domains. What follows is a list of the COVID-19-related projects currently using GraphDB. medications: 16,406 instances.
This is part of Ontotext’s AI-in-Action initiative aimed at enabling data scientists and engineers to benefit from the AI capabilities of our products. Disinformation is on the rise and fact-checkers struggle to keep up with the amount of data that is to be analyzed. Text2Event is a transformer model by Lu et al.²
Most AI teams focus on the wrong things. Heres a common scene from my consulting work: AI TEAM Heres our agent architectureweve got RAG here, a router there, and were using this new framework for ME [Holding up my hand to pause the enthusiastic tech lead] Can you show me how youre measuring if any of this actually works?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content