This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One effective strategy is transforming long-form content like blog posts into engaging Twitter threads. In this article, we’ll explore how to build an application to automate blog to Twitter thread creation […] The post Automate Blog to Twitter Thread using Gemini-2.0,
But what if Blog Creation with AI could do it all for you? Imagine a seamless process where, alongside your writing, AI generates original, high-quality images tailored […] The post Automated Image Generation: Transforming Your Blog Creation Process appeared first on Analytics Vidhya.
This blog dives into the remarkable journey of a data team that achieved unparalleled efficiency using DataOps principles and software that transformed their analytics and data teams into a hyper-efficient powerhouse.
It also includes free machine learning books, courses, blogs, newsletters, and links to local meetups and communities. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies.
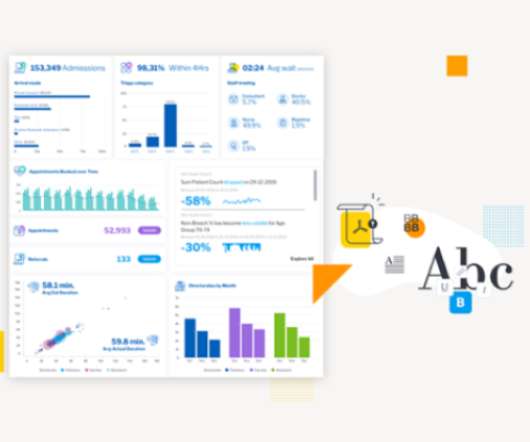
In this blog, we explore 5 key principles that exist to ensure you create a relevant dashboard that guides and simplifies the user experience, makes it as easy as possible to interpret what is presented no matter its complexity, and increases the adoption of BI.
This blog post will guide you through the process of creating such an agent using LangChain, a framework for developing […] The post Building a Web-Searching Agent with LangChain and Llama 3.3 Creating AI agents that can interact with the real world is a great area of research and development. 70B appeared first on Analytics Vidhya.
2025 will be about the pursuit of near-term, bottom-line gains while competing for declining consumer loyalty and digital-first business buyers,” Sharyn Leaver, Forrester chief research officer, wrote in a blog post Tuesday. Some leaders will pursue that goal strategically, in ways that set up their organizations for long-term success.
Choose the Amazon S3 source node and enter the following values: S3 URI : s3://aws-blogs-artifacts-public/artifacts/BDB-4798/data/venue.csv Format : CSV Delimiter : , Multiline : Enabled Header : Disabled Leave the rest as default. To learn more, refer to our documentation and the AWS News Blog. Locate the icon at the canvas.
Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid Ali Awan ( @1abidaliawan ) is a certified data scientist professional who loves building machine learning models.
This blog acts as a beginner’s guide to what data storytelling means for your company’s business intelligence and data analytics, explains the importance of leveraging it today, and illustrates how Yellowfin’s own set of storytelling tools can enrich your insight reporting efforts.
YouTube offers billions of videos, and the internet is filled with articles, blogs, and academic papers. In the age of information overload, it’s easy to get lost in the large amount of content available online.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter How to Learn Math for Data Science: A Roadmap for Beginners Confused about where to start with data (..)
In this blog, we will dive deep into the […] The post What is Beam Search in NLP Decoding? It is especially important in sequence generation tasks such as text generation, machine translation, and summarization. Beam search balances between exploring the search space efficiently and generating high-quality output.
Note: While using Postman or Insomnia to run the API calls mentioned throughout this blog, choose AWS IAM v4 as the authentication method and input your IAM credentials in the Authorization section. See blog post to understand how to use snapshot management policies to manage automated snapshot in OpenSearch Service.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Serve Machine Learning Models via REST APIs in Under 10 Minutes Stop leaving your models on your laptop. (..)
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 10 Python Math & Statistical Analysis One-Liners Python makes common math and stats tasks super (..)
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter How to Combine Streamlit, Pandas, and Plotly for Interactive Data Apps With just two Python files and (..)
Launch summary Following is the launch summary which provides the announcement links and reference blogs for the key announcements. To generate accurate SQL queries, Amazon Bedrock Knowledge Bases uses database schema, previous query history, and other contextual information that is provided about the data sources.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Build ETL Pipelines for Data Science Workflows in About 30 Lines of Python Want to understand how ETL (..)
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Build a Data Cleaning & Validation Pipeline in Under 50 Lines of Python Clean and validate messy (..)
Refer to the detailed blog post on how you can use this to connect through various other tools. Check out the video below and the detailed blog post to learn how to connect Amazon DataZone to external analytics tools via JDBC. The feature is supported in all AWS commercial Regions where Amazon DataZone is currently available.
Create it as a JSON file on your workstation (for this post, we call it blog-sub-target.json ). You can use the command create-subscription-target to create the subscription target. The following is an example JSON payload for the subscription target creation.
“With the addition of Fabric Databases, Fabric now brings together both transactional and analytical workloads, creating a truly unified data platform,” Arun Ulag, corporate vice president of Azure Data, said in a blog post Tuesday.
This example reads a 3 TB TPC-DS dataset in Parquet format from a publicly accessible S3 bucket: spark.read.parquet("s3://blogpost-sparkoneks-us-east-1/blog/BLOG_TPCDS-TEST-3T-partitioned/store/").createOrReplaceTempView("store") spark.read.parquet("s3://blogpost-sparkoneks-us-east-1/blog/BLOG_TPCDS-TEST-3T-partitioned/item/").createOrReplaceTempView("item")
This blog […] The post A Guide to Flax: Building Efficient Neural Networks with JAX appeared first on Analytics Vidhya. Flax’s seamless integration with JAX enables automatic differentiation, Just-In-Time (JIT) compilation, and support for hardware accelerators, making it ideal for both experimental research and production.
EY, in a recent blog post focused on top opportunities for IT companies in 2025, recommends money raised from these activities be used on AI projects. Divestitures can also help companies zero in on their potential and market relevance, the blog authors note.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter The Lifecycle of Feature Engineering: From Raw Data to Model-Ready Inputs This article explains how (..)
LlamaIndex added a document research assistant for blog creation blueprint. LangChain expanded its structured report generation blueprint, which allows users to define a topic and specify an outline to guide an agent in searching the web for information relevant to a report.
Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid Ali Awan ( @1abidaliawan ) is a certified data scientist professional who loves building machine learning models.
This blog post explores an innovative approach to SQL-code generation and SQL code explanation using the Latest PydanticAI Framework and Google’s Gemini-1.5
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter MLFlow Mastery: A Complete Guide to Experiment Tracking and Model Management MLFlow is a tool that helps (..)
For those who enjoy reading, we also have a blog post that delves into the ideas in more detail. The post Webinar: Test Coverage: The Software Development Idea That Supercharges Data Quality & Data Engineering first appeared on DataKitchen.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 7 Must-Know Machine Learning Algorithms Explained in 10 Minutes Get up to speed with the 7 most essential (..)
EY, en una publicacin reciente en su blog centrada en las principales oportunidades para las empresas de TI en 2025, recomienda que el dinero recaudado con estas actividades se utilice en proyectos de IA. Las desinversiones tambin pueden ayudar a las empresas a centrarse en su potencial y relevancia en el mercado, sealan los autores.
To learn more, check out the following AWS News blog announcements: Amazon SageMaker Amazon SageMaker Lakehouse Amazon SageMaker Data and AI Governance About the authors G2 Krishnamoorthy is VP of Analytics, leading AWS data lake services, data integration, Amazon OpenSearch Service, and Amazon QuickSight.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Build Your Own Simple Data Pipeline with Python and Docker Learn how to develop a simple data pipeline (..)
To dive deeper into how to replicate BMWs data success story, check out the AWS blog post on building a data mesh with Amazon Lake Formation and AWS Glue. About the authors Ruben Simon is a Head of Product for BMW’s Cloud Data Hub, the company’s largest data platform.
However, you can use the same file name as long as it’s from different auto-copy jobs: job_customerA_sales – s3://redshift-blogs/sales/customerA/2022-10-15-sales.csv job_customerB_sales – s3://redshift-blogs/sales/customerB/2022-10-15-sales.csv Do not update file contents. Do not overwrite existing files.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 8 Ways to Scale your Data Science Workloads From in-spreadsheet machine learning to terabyte sized DataFrames, (..)
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Integrating DuckDB & Python: An Analytics Guide Learn how to run lightning-fast SQL queries on (..)
When Timing Goes Wrong: How Latency Issues Cascade Into Data Quality Nightmares As data engineers, we’ve all been there. A dashboard shows anomalous metrics, a machine learning model starts producing bizarre predictions, or stakeholders complain about inconsistent reports.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content