This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post explores how to start using Delta Lake UniForm on Amazon Web Services (AWS). You can learn how to query Delta Lake native tables through UniForm from different datawarehouses or engines such as Amazon Redshift as an example of expanding data access to more engines. This takes around 2 minutes.
Back by popular demand, we’ve updated our data nerd Gift Giving Guide to cap off 2021. We’ve kept some classics and added some new titles that are sure to put a smile on your data nerd’s face. Here are eight highly recommendable books to help you find that special gift. ?? ?? ???. How did we get here?
Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Data must be able to freely move to and from datawarehouses, datalakes, and data marts, and interfaces must make it easy for users to consume that data.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, datawarehouse, and purpose-built stores with a unified governance model. Of those tables, some are larger (such as in terms of record volume) than others, and some are updated more frequently than others.
job reads a dataset, updated daily in an S3 bucket under different partitions, containing new book reviews from an online marketplace and runs SparkSQL to gather insights into the user votes for the book reviews. Understanding the upgrade process through an example We now show a production Glue 2.0 using the Spark Upgrade feature.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
Adapted from the book Effective Data Science Infrastructure. Data is at the core of any ML project, so data infrastructure is a foundational concern. ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing datawarehouses.
However, companies are still struggling to manage data effectively, to implement GenAI applications that deliver proven business value. The post OReilly Releases First Chapters of a New Book about Logical Data Management appeared first on Data Management Blog - Data Integration and Modern Data Management Articles, Analysis and Information.
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
For those in the data world, this post provides a curated guide for all analytics sessions that you can use to quickly schedule and build your itinerary. Book your spot early for the sessions you do not want to miss. 11:30 AM – 12:30 PM (PDT) Ceasars Forum ANT318 | Accelerate innovation with end-to-end serverless data architecture.
Designing databases for datawarehouses or data marts is intrinsically much different than designing for traditional OLTP systems. Accordingly, data modelers must embrace some new tricks when designing datawarehouses and data marts. Figure 1: Pricing for a 4 TB datawarehouse in AWS.
The knock-on impact of this lack of analyst coverage is a paucity of data about monies being spent on data management. In reality MDM ( master data management ) means Major Data Mess at most large firms, the end result of 20-plus years of throwing data into datawarehouses and datalakes without a comprehensive data strategy.
This dynamic integration of streaming data enables generative AI applications to respond promptly to changing conditions, improving their adaptability and overall performance in various tasks. To better understand this, imagine a chatbot that helps travelers book their travel.
Connect with experts, meet with book authors on data warehousing and analytics (at the Meet the Authors event on November 29 and 30, 3:00 PM – 4:00 PM), win prizes, and learn all about the latest innovations from our AWS Analytics services.
I was a student system administrator for the campus computing group and at that time they were migrating the campus phone book to a new tool, new to me, known as Oracle. After having rebuilt their datawarehouse, I decided to take a little bit more of a pointed role, and I joined Oracle as a database performance engineer.
One pulse sends 150 bytes of data. So, each band can send out 500KB to 750KB of data. To handle the huge volume of data thus generated, the company is in the process of deploying a datalake, datawarehouse, and real-time analytical tools in a hybrid model.
How Synapse works with DataLakes and Warehouses. Synapse services, datalakes, and datawarehouses are often discussed together. Here’s how they correlate: Datalake: An information repository that can be stored in a variety of different ways, typically in a raw format like SQL.
The details of each step are as follows: Populate the Amazon Redshift Serverless datawarehouse with company stock information stored in Amazon Simple Storage Service (Amazon S3). Redshift Serverless is a fully functional datawarehouse holding data tables maintained in real time.
Cloudera Operational Database enables developers to quickly build future-proof applications that are architected to handle data evolution. Many business applications such as flight booking and mobile banking rely on a database that can scale and serve data at low latency. Cloudera DataWarehouse to perform ETL operations.
The data drawn from power visualizations comes from a variety of sources: Structured data , in the form of relational databases such as Excel, or unstructured data, deriving from text, video, audio, photos, the internet and smart devices. Her debut novel, The Book of Jeremiah , was published in 2019.
Generating business outcomes In 4 days, the Altron SI team left the Immersion Day workshop with the following: A data pipeline ingesting data from 21 sources (SQL tables and files) and combining them into three mastered and harmonized views that are cataloged for Altron’s B2B accounts.
In his spare time, Raghavarao enjoys spending time with his family, reading books, and watching movies. Hang Zuo is a Senior Product Manager on the Amazon Kinesis Data Streams team at Amazon Web Services.
models are trained on IBM’s curated, enterprise-focused datalake. Fortunately, data stores serve as secure data repositories and enable foundation models to scale in both terms of their size and their training data. Foundation models focused on enterprise value IBM’s watsonx.ai All watsonx.ai
You have a specific book in mind, but you have no idea where to find it. You enter the title of the book into the computer and the library’s digital inventory system tells you the exact section and aisle where the book is located. It uses metadata and data management tools to organize all data assets within your organization.
Powering a knowledge management system with a data lakehouse Organizations need a data lakehouse to target data challenges that come with deploying an AI-powered knowledge management system. It provides the combination of datalake flexibility and datawarehouse performance to help to scale AI.
In fact is is the crucial final link between an organisation’s data and the people who need to use it. In many ways how people experience data capabilities will be determined by this final link. When the sadly common refrain of “we built state-of-the-art data capabilities, why is noone using them?
In his book titled “The Fourth Industrial Revolution,” Klaus Schwab describes the age as, “characterized by a much more ubiquitous and mobile internet, by smaller and more powerful sensors that have become cheaper, and by artificial intelligence and machine learning.”
With that in mind, we have prepared a list of the top 19 definitive data analytics and big databooks, along with magazines and authentic readers’ reviews upvoted by the Goodreads community. Essential Big Data And Data Analytics Insights. Discover The Best Data Analytics And Big DataBooks Of All Time.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , datawarehouse, datalake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
Its distributed architecture empowers organizations to query massive datasets across databases, datalakes, and cloud platforms with speed and reliability. Optimizing connections to your data sources is equally important, as it directly impacts the speed and efficiency of data access.
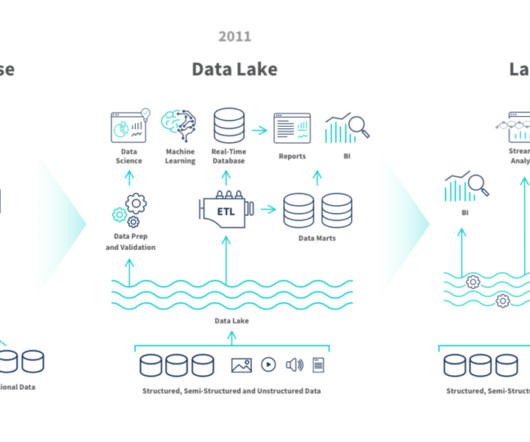
To have any hope of generating value from growing data sets, enterprise organizations must turn to the latest technology. You’ve heard of datawarehouses, and probable datalakes, but now, the data lakehouse is emerging as the new corporate buzzword. To address this, the data lakehouse was born.
This includes cleaning, aggregating, enriching, and restructuring data to fit the desired format. Load : Once data transformation is complete, the transformed data is loaded into the target system, such as a datawarehouse, database, or another application.
Data Access What insights can we derive from our cloud ERP? What are the best practices for analyzing cloud ERP data? Data Management How do we create a datawarehouse or datalake in the cloud using our cloud ERP? How do I access the legacy data from my previous ERP?
What are the best practices for analyzing cloud ERP data? Data Management. How do we create a datawarehouse or datalake in the cloud using our cloud ERP? How do I access the legacy data from my previous ERP? How can we rapidly build BI reports on cloud ERP data without any help from IT?
When migrating to the cloud, there are a variety of different approaches you can take to maintain your data strategy. Those options include: Datalake or Azure DataLake Services (ADLS) is Microsoft’s new data solution, which provides unstructured date analytics through AI. Different Approaches to Migration.
Trino allows users to run ad hoc queries across massive datasets, making real-time decision-making a reality without needing extensive data transformations. This is particularly valuable for teams that require instant answers from their data. DataLake Analytics: Trino doesn’t just stop at databases.
For companies that operate multiple corporate entities, the most common approach is to create distinct companies within D365 F&SCM, each with its own set of books. Jet Reports now offers high performance connectivity with options to connect to Synapse/Azure DataLakes, BYOD, SQL or your Cubes and Tabular models.
Use existing AWS Glue tables This section has following prerequisites: A datalake administrator user by following Create a datalake administrator. For detailed instruction see Revoking permission using the Lake Formation console. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team.
This is the final part of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to process data with Amazon Redshift Spectrum and create the gold (consumption) layer. The following diagram illustrates the different layers of the datalake.
datalakes & warehouses like Cloudera, Google Big Query, etc., Scalability: Your source systems, data volumes, and calculation complexities change as your business evolves. This includes databases like Microsoft SQL server, IBM DB2, etc., ERP & accounting systems like Microsoft Dynamics 365, SAGE, Quickbooks, etc.,
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content