

Unstructured data management and governance using AWS AI/ML and analytics services
AWS Big Data
OCTOBER 25, 2023
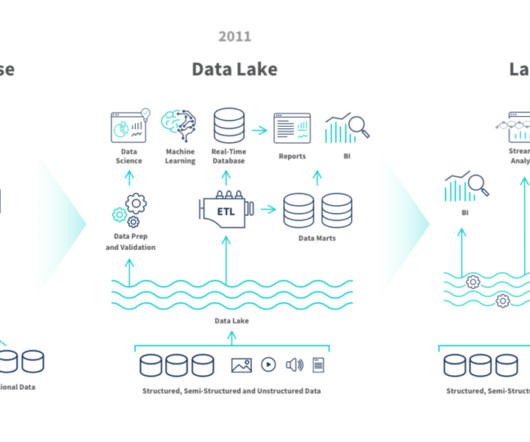
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Text, images, audio, and videos are common examples of unstructured data.



















Let's personalize your content