This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
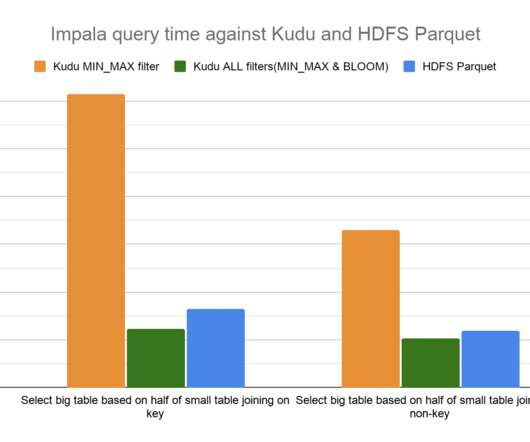
Pushing down column predicate filters to Kudu allows for optimized execution by skipping reading column values for filtered out rows and reducing network IO between a client, like the distributed query engine Apache Impala, and Kudu. Broadcast the generated hash table to all worker nodes. Before 7.1.5, Join Queries.
During the first-ever virtual broadcast of our annual Data Impact Awards (DIA) ceremony, we had the great pleasure of announcing this year’s finalists and winners. It hosts over 150 big data analytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery.
To optimize your viewing experience, online video transmission uses streaming-specific and HTTP-based protocols. It supports many media formats and allows for multicast, enabling a single host to broadcast to multiple recipients. For instance, Real-Time Messaging Protocol operates using specialized streaming servers.
Player performance information also improves the quality of coaching and reduces decision-making time, making for a higher quality game and broadcast. Broadcasters and advertisers are willing to pay more if they can get eyeballs on their names and logos. And that makes fans much more likely to come back.
It integrates data across a wide arrange of sources to help optimize the value of ad dollar spending. Its cloud-hosted tool manages customer communications to deliver the right messages at times when they can be absorbed. So Oracle renamed it Oracle Advertising and Customer Experience.
Hackers have turned to exploiting website optimization platform Google Analytics to steal credit cards, passwords, IP addresses and a whole host of compromising information that can be shared by hacked sites. It’s important to never rest on your laurels when it comes to securing your network.
It integrates data across a wide arrange of sources to help optimize the value of ad dollar spending. Its cloud-hosted tool manages customer communications to deliver the right messages at times when they can be absorbed. So Oracle renamed it Oracle Advertising and Customer Experience.
Netflix uses AWS cloud services for optimizing almost all of its services. In much the same way, a user can unblock sports events that are broadcast online. Another example is that a Russian digital streaming platform could be hosting the Russian swimming championships, but only within Russia.
Most savvy marketers recognize the importance of using analytics technology to optimize their strategies to get a higher ROI. Instagram uses big data to identify and block offensive content, create personalized feeds for their users and optimize their advertising platform. Go Live Instagram loves live broadcasts. And guess what?
As head of the JRFUs media business division, Yutaka Muroguchi has contracts with all three organizations, and is in charge of video management and broadcasting rights. At that time, the decision was made to produce the official match footage themselves rather than by the broadcasting station J Sports.
When you send requests to your OpenSearch Service domain, the request is broadcast to the nodes with shards that will process that request. These dedicated coordinator nodes offload coordination tasks and dashboard hosting from data nodes, freeing up CPU and memory resources.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content