This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, even the most powerful systems can experience performance degradation if they encounter anti-patterns like grossly inaccurate table statistics, such as the row count metadata. This can have a significant impact on overall query performance.
Benchmark setup In our testing, we used the 3 TB dataset stored in Amazon S3 in compressed Parquet format and metadata for databases and tables is stored in the AWS Glue Data Catalog. When statistics aren’t available, Amazon EMR and Athena use S3 file metadata to optimize query plans. With Amazon EMR 6.10.0
In some cases, the precursor can occur sufficiently in advance of the tidal wave’s predicted arrival at inhabited shores, thereby enabling early warnings to be broadcasted. A cognitive person is curious about odd things that they see and hear—things or circumstances or behaviors that seem out of context, unusual, and surprising.
These systems rely on an active leader node to identify failures or delays and then broadcast this information to all nodes. OpenSearch Service utilizes an internal node-to-node communication protocol for replicating write traffic and coordinating metadata updates through an elected leader.
Along the way, metadata is collected, organized, and maintained to help debug and ensure data integrity. The platform is integrated across digital venues such as search and social media and older markets such as print, cable TV, radio, and broadcast. Agencies and ad buyers for large clients turn to Simpli.fi
The leader node is the authority on the metadata in the cluster, which is called cluster state. Any changes to the cluster state are processed by the leader node and broadcasted to all of the nodes in the cluster. Amazon OpenSearch clusters are comprised of data nodes and cluster manager nodes.
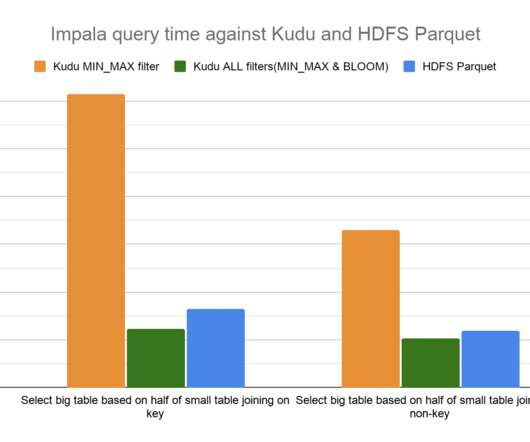
Consider the case of a broadcast hash join between a small table and a big table where predicate pushdown is not available. Broadcast the generated hash table to all worker nodes. COMPUTE STATS were run on all tables to help gather information about the table metadata and help Impala optimize the query plan. Join Queries.
The seminar was organized by the European Broadcasting Union (EBU) and the respective community that is dedicated to foster knowledge sharing and learning on data-related projects, such as metadata and AI. To address this issue, Ontotext, an AI company and a member of the vera.ai
Along the way, metadata is collected, organized, and maintained to help debug and ensure data integrity. The platform is integrated across digital venues such as search and social media and older markets such as print, cable TV, radio, and broadcast.
Searching of metadata about the content, including title, author, and description 2. Some organizations consider data products a one-way information broadcast. Data product discovery should mirror the capabilities of online content subscription services. These include: 1.
Along with the ability to implement ACID transactions and scalable metadata handling, Delta Lakes can also unify the streaming and batch data processing”. . The schema of the metadata is as follows: Column Type Description format string Format of the table, that is, “delta”. Advantages of using Delta Lakes.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content