This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. Some of the queries in our benchmark experienced up to 12x speed up.
When you use Trino on Amazon EMR or Athena, you get the latest open source community innovations along with proprietary, AWS developed optimizations. and Athena engine version 2, AWS has been developing query plan and engine behavior optimizations that improve query performance on Trino. Starting from Amazon EMR 6.8.0
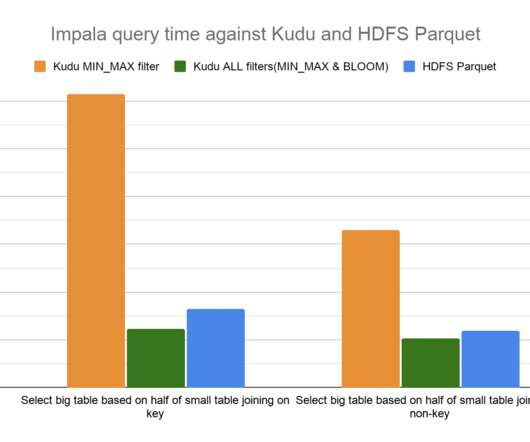
Pushing down column predicate filters to Kudu allows for optimized execution by skipping reading column values for filtered out rows and reducing network IO between a client, like the distributed query engine Apache Impala, and Kudu. Broadcast the generated hash table to all worker nodes. Join Queries.
It integrates data across a wide arrange of sources to help optimize the value of ad dollar spending. Along the way, metadata is collected, organized, and maintained to help debug and ensure data integrity. So Oracle renamed it Oracle Advertising and Customer Experience. Agencies and ad buyers for large clients turn to Simpli.fi
It integrates data across a wide arrange of sources to help optimize the value of ad dollar spending. Along the way, metadata is collected, organized, and maintained to help debug and ensure data integrity. So Oracle renamed it Oracle Advertising and Customer Experience.
Along with the ability to implement ACID transactions and scalable metadata handling, Delta Lakes can also unify the streaming and batch data processing”. . The schema of the metadata is as follows: Column Type Description format string Format of the table, that is, “delta”. Advantages of using Delta Lakes.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content