This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As leaders work to define the right metrics, those measures must be tightly aligned with the business strategy and should account for the cost of not investing. As leaders work to define the right metrics, those measures must be tightly aligned with the business strategy and should account for the cost of not investing.
Stale marketing or measurement thinking applied to them results in terribly sub optimal results for all involved. Are not just reporting "hits", rather coming up with clever metrics. Quantitative Metrics / Analyses. While on the surface they might seem useful, I am always suspicious of compound metrics.
Amazon Redshift provides performance metrics and data so you can track the health and performance of your provisioned clusters, serverless workgroups, and databases. This will open the query plan in a tree view along with additional metrics on the side panel. For more information, refer to Amazon Redshift clusters.
We’ve already discussed how checkpoints, when triggered by the job manager, signal all source operators to snapshot their state, which is then broadcasted as a special record called a checkpoint barrier. Then it broadcasts the barrier downstream. For more details, refer to Limitations.
As a result, a developer may observe that their AWS Glue jobs are completing without apparent errors, yet the system could be operating far from its optimal efficiency. Another thing that you can use is the summary metrics for each stage. You can detect data skew with data analysis or by using the Spark UI.
Internally, Apache Flink uses clever mechanisms to maintain exactly-once state consistency, while also optimizing for throughput and reduced latency. The time a sub-task spends on the synchronous and asynchronous parts of the checkpoint is measured by Sync Duration and Async Duration metrics, shown by the Apache Flink UI.
These networks can be even more effective when they are optimized with machine learning. There is a primary router, which is connected to an internet modem and broadcasts a signal throughout the house. As useful as mesh networks can be, they are even more effective when optimized with machine learning.
Today, teams utilize sophisticated tracking systems, video analysis tools, and wearable devices to gather a wide range of performance metrics. In addition to performance metrics, data collection also includes injury and fitness data. However, the advent of advanced technologies and analytics has ushered in a new era of data collection.
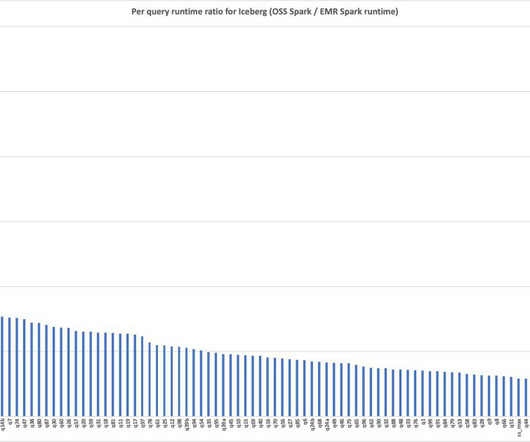
times faster with Amazon EMR runtime for Apache Spark , we detailed some of the optimizations, showing a runtime improvement of 4.5 However, many of the optimizations are geared towards DataSource V1, whereas Iceberg uses Spark DataSource V2. We have added eight new optimizations incrementally since the Amazon EMR 6.15
Hackers have turned to exploiting website optimization platform Google Analytics to steal credit cards, passwords, IP addresses and a whole host of compromising information that can be shared by hacked sites. Although you have to request a demo to get started. If you need an enterprise edition, it may come at a dollar.
Greater alignment across business units: Optimize management processes according to a variety of factors beyond just the condition of a piece of equipment. Radio frequency identifier tags (RFID): RFID tags broadcast information about the asset they’re attached to using radio-frequency signals and Bluetooth technology.
This makes 5G’s Block Error Rate (BER)—a metric of error frequency—much lower. Today, many mundane but necessary tasks associated with equipment repair and optimization are being turned over to machines thanks to 5G connectivity paired with AI and ML capabilities.
Read this blog post to explore how digital twins can help you optimize your asset performance. Asset lifecycle management best practices The primary objective of asset lifecycle management (ALM) should always be the optimization of assets throughout their lifecycle. Each offers unique strengths and are upgrades on their predecessors.
For framing purposes, Spark’s sweet spot is quickly developing exploratory/interactive analysis and iterative algorithms , e.g., gradient descent and MCMC, whereas Dataflow’s sweet spot is processing streaming data and highly-optimized, robust, fixed pipelines. Spark provides the user with greater flexibility.
The lesson is about the limitation of optimizing for a local maxima, usually in a silo. If the Surface Marketing team is like every other team at every other company engaged in sponsorships and television advertising, it’ll measure the same collection of smart metrics like everyone else. Better than Reach and Brand Lift metrics?
Most savvy marketers recognize the importance of using analytics technology to optimize their strategies to get a higher ROI. Instagram uses big data to identify and block offensive content, create personalized feeds for their users and optimize their advertising platform. Go Live Instagram loves live broadcasts.
When you send requests to your OpenSearch Service domain, the request is broadcast to the nodes with shards that will process that request. We recommend using CPU optimized instances of a size similar to that of the data nodes. Coordinator metrics While the guidelines above are a good start, every use case is unique.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content