This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post How Can You Optimize your Spark Jobs and Attain Efficiency – Tips and Tricks! This article was published as a part of the Data Science Blogathon. Introduction “Data is the new oil” ~ that’s no secret and is. appeared first on Analytics Vidhya.
Before the advent of broadcast media and mass culture, individuals’ mental models of the world were generated locally, along with their sense of reality and what they considered ground truth. What has happened? Reality has once again become decentralized. The InfoLandscapes. “Cyberspace.
For engineering teams, WWE operates under the pressure of delivering high-quality live broadcasts into the living rooms of millions of fans each week, from venues across the world. says Ralph Riley, Director of Broadcast IT Systems at WWE. They also put WWE in danger of missing SLAs with broadcast partners.
Currently, 51% of organizations are exploring their potential to optimize administrative tasks (60%), customer service (54%), and business content creation (53%). Despite the challenges, there is optimism about driving greater adoption. However, only 12% have deployed such tools to date.
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. Some of the queries in our benchmark experienced up to 12x speed up.
We’ve already discussed how checkpoints, when triggered by the job manager, signal all source operators to snapshot their state, which is then broadcasted as a special record called a checkpoint barrier. Then it broadcasts the barrier downstream. However, it continues to process partitions that are behind the barrier.
Internally, Apache Flink uses clever mechanisms to maintain exactly-once state consistency, while also optimizing for throughput and reduced latency. After the barriers from all upstream partitions have arrived, the sub-task takes the snapshot of its state and then broadcasts the barrier downstream.
In the annual Porsche Carrera Cup Brasil, data is essential to keep drivers safe and sustain optimal performance of race cars. Together, they established a core architecture that the company could build on to develop its engineering capabilities and, eventually, support for entertainment and broadcasting, which remains on Morrone’s roadmap.
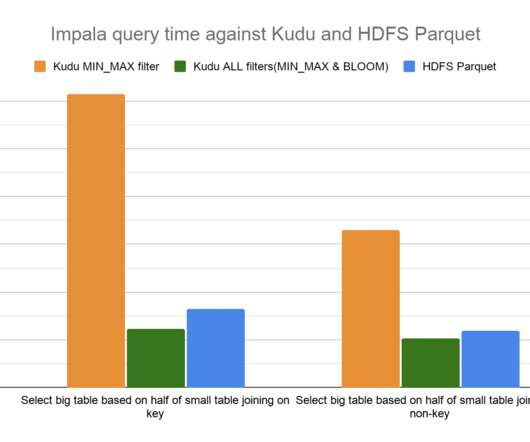
Pushing down column predicate filters to Kudu allows for optimized execution by skipping reading column values for filtered out rows and reducing network IO between a client, like the distributed query engine Apache Impala, and Kudu. Broadcast the generated hash table to all worker nodes. Join Queries.
Catalyst now stops at each stage boundary to try and apply additional optimizations given the information available on the intermediate data. This is what the execution of the first TPC-DS query looks like before and after enabling AQE: Dynamically Converting Sort Merge Joins to Broadcast Joins. Dynamically Optimize Skewed Joins.
As a result, a developer may observe that their AWS Glue jobs are completing without apparent errors, yet the system could be operating far from its optimal efficiency. This can be an effective strategy to optimize join operations and mitigate data skew issues resulting from shuffling large amounts of data across nodes.
Delta lake allows thousands of data to run in parallel, address optimization and partition challenges, faster metadata operations, maintains a transactional log and continuously keeps updating the data. improved data processing in the following ways: Skewed Join Optimization. Optimization. Advantages of using Delta Lakes.
This data includes usage analytics & reports that you can view and analyse in order to optimize your service. Every IPTV/OTT platform relies on user data and statistics to optimize its content. This allows you to optimize your EPG, therefore having more people installed into your billing system. Client Reporting.
Suboptimal data distribution – If data distribution is suboptimal, you might notice a large broadcast or redistribution of data across compute nodes when two large tables are joined together. Nested loop joins are the cross-joins without a join condition that result in the Cartesian product of two tables.
When you use Trino on Amazon EMR or Athena, you get the latest open source community innovations along with proprietary, AWS developed optimizations. and Athena engine version 2, AWS has been developing query plan and engine behavior optimizations that improve query performance on Trino. Starting from Amazon EMR 6.8.0
With Windows Studio Effects it’s easy to broadcast to the group without extraneous airport lounge noises seeping through. 3 Cocreator is optimized for English text prompts. Recall is optimized for select languages (English, Chinese (simplified), French, German, Japanese, and Spanish). Coming to more Entra ID users over time.
All mainstage sessions will be professionally recorded and re-broadcast on Thursday May 11 th at the FutureIT | Canada virtual event for those who are unable to attend in person. With its tagline, “Building the Digital Enterprise with Cloud, AI and Security” you can be sure the conversations are going to yield some very strong outcomes.
These networks can be even more effective when they are optimized with machine learning. There is a primary router, which is connected to an internet modem and broadcasts a signal throughout the house. As useful as mesh networks can be, they are even more effective when optimized with machine learning.
In a join between a small table (right side) and a big table (left side) we typically read the entire small table and broadcast the generated hash table to the tasks scanning the bigger table. Hive users can check how probedecode optimization applies for their MapJoin queries using their standard query explain plans.
Sreesha Rao, senior manager of IT applications at Niagara Bottling and Seth Dobrin, CDO of IBM Analytics, spoke with Dave Vellante in NYC on the eve of the 13 September taping of the Win with AI digital broadcast about the company’s efforts to save on plastic use by optimizing the settings of its pallet wrappers, machines that wrap an entire pallet (..)
After the adoption of the final report, the broadcasting of negative trends to regional and municipal authorities, approval and implementation of the action plan for training young personnel for the education system for the coming years. Decision making. Sociocultural environment.
In this article, we will explore various optimizations that can be implemented to help you achieve better performance or plan for scalability. . The existing protocols need to be optimized carefully to achieve improvements. In this upcoming section, we will discuss a few of the possible optimizations.
A growing number of marketers are using AI to optimize and automate marketing campaigns in fantastic ways. You can tailor your messaging to be more relevant based on previous interactions, whether you’re sending a broadcast or a sponsored message. Artificial intelligence has upended the digital marketing profession. Use keywords.
have expanded the reach of the race to a new generation of fans and ensured they’re able to continually optimize race operations. “We Today, you a see a television broadcast that’s full of live, rich data about rider speeds and time gaps, and you’ve got second screen apps like Race Center that allow you to follow every moment of the race.”
Player performance information also improves the quality of coaching and reduces decision-making time, making for a higher quality game and broadcast. Broadcasters and advertisers are willing to pay more if they can get eyeballs on their names and logos. And that makes fans much more likely to come back.
Coaches can analyze formations, player movements, and positioning to identify areas of improvement and optimize strategies. The Influence of Data Collection on Training Training regimes can be greatly optimized through data analysis. Understanding the tactical aspects of the game becomes easier with data analysis.
But things go awry and when they do, Proctor & Gamble now employs its Hot Melt Optimization platform to catch snags and get the process back on track. This ensures that the output of each facility exceeds what was achieved before Hot Melt Optimization was launched.
Most importantly, AI can help optimize cybersecurity apps to help stop hackers. Before your crypto transaction is completed, it must be broadcast to its proprietary network for validation. The most important benefit is that they can help stop hackers. How Do Crypto Wallets Work?
To optimize your viewing experience, online video transmission uses streaming-specific and HTTP-based protocols. It supports many media formats and allows for multicast, enabling a single host to broadcast to multiple recipients. For instance, Real-Time Messaging Protocol operates using specialized streaming servers.
It integrates data across a wide arrange of sources to help optimize the value of ad dollar spending. The platform is integrated across digital venues such as search and social media and older markets such as print, cable TV, radio, and broadcast. So Oracle renamed it Oracle Advertising and Customer Experience.
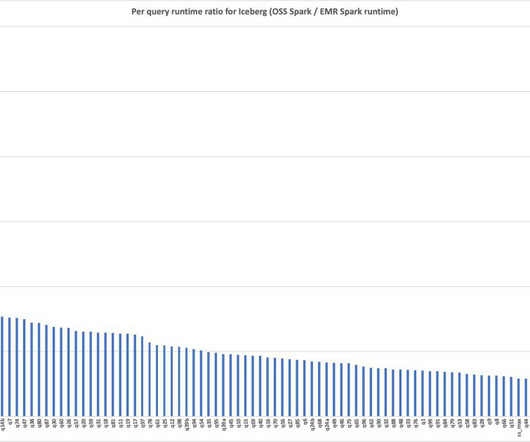
times faster with Amazon EMR runtime for Apache Spark , we detailed some of the optimizations, showing a runtime improvement of 4.5 However, many of the optimizations are geared towards DataSource V1, whereas Iceberg uses Spark DataSource V2. We have added eight new optimizations incrementally since the Amazon EMR 6.15
During the first-ever virtual broadcast of our annual Data Impact Awards (DIA) ceremony, we had the great pleasure of announcing this year’s finalists and winners. To optimize investments, effectively bundle product offerings, and deliver contextual campaigns, Globe Telecom created a new analytical environment.
In addition, a lot of work has also been put into ensuring that Impala runs optimally in decoupled compute scenarios, where the data lives in object storage or remote HDFS. These are the common bottlenecks in analytic queries, and are notoriously difficult to optimize. . Broadcast Hash Join. Summary and call to action.
Hackers have turned to exploiting website optimization platform Google Analytics to steal credit cards, passwords, IP addresses and a whole host of compromising information that can be shared by hacked sites. It’s important to never rest on your laurels when it comes to securing your network.
WiFi-enabled tracking: WiFi-enabled tracking systems use a tag affixed to an asset to broadcast a variety of information about it over a local WiFi network. Enterprise asset management with the IBM Maximo Application Suite helps companies optimize asset performance and extend asset lifespans.
He brings expertise in developing IT strategy, digital transformation, AI engineering, process optimization and operations. He brings in 20 years of experience across sectors including media, broadcasting, data centre, telecom, BFSI, and retail. Broadcast Audience Research Council (BARC) India appoints Mahendra K Upadhyay as CIO.
By default, the sink writes in batches to optimize throughput. SQL In Apache Flink SQL, users can provide hints to join queries that can be used to suggest the optimizer to have an effect in the query plan. The DataStream API now supports features like side outputs and broadcast state, and gaps on windowing API have been closed.
It integrates data across a wide arrange of sources to help optimize the value of ad dollar spending. The platform is integrated across digital venues such as search and social media and older markets such as print, cable TV, radio, and broadcast. So Oracle renamed it Oracle Advertising and Customer Experience.
Greater alignment across business units: Optimize management processes according to a variety of factors beyond just the condition of a piece of equipment. Radio frequency identifier tags (RFID): RFID tags broadcast information about the asset they’re attached to using radio-frequency signals and Bluetooth technology.
Unlike other communication channels, social media posts are broadcast to the public. This requires organizations to monitor their channels and use tools that create notifications every time their brand is mentioned. That can turn an individual issue into a much larger corporate reputation issue if not immediately addressed.
Today, many mundane but necessary tasks associated with equipment repair and optimization are being turned over to machines thanks to 5G connectivity paired with AI and ML capabilities. Smart factories 5G, along with AI and ML, is poised to help factories become not only smarter but more automated, efficient and resilient.
Optimal use of capital, maintaining disciplined capital allocation prioritization. The conference call, which will be broadcast live via the Internet, and a copy of this press release along with supplemental slides used during the call, can be accessed on CDW’s website at investor.cdw.com. The transaction also would have added $0.62
Netflix uses AWS cloud services for optimizing almost all of its services. In much the same way, a user can unblock sports events that are broadcast online. Many businesses are leveraging these solutions to provide content to their viewers, since 94% of them have discovered that it is the best way to grow their brands.
Stale marketing or measurement thinking applied to them results in terribly sub optimal results for all involved. Are you broadcasting or participating in conversation? These new channels, Twitter and Facebook and YouTube and Tumblr and, yes, even blogs, are very distinct customer / participant experiences. Velocity. *
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content