

Accelerate Amazon Redshift Data Lake queries with AWS Glue Data Catalog Column Statistics
AWS Big Data
OCTOBER 1, 2024
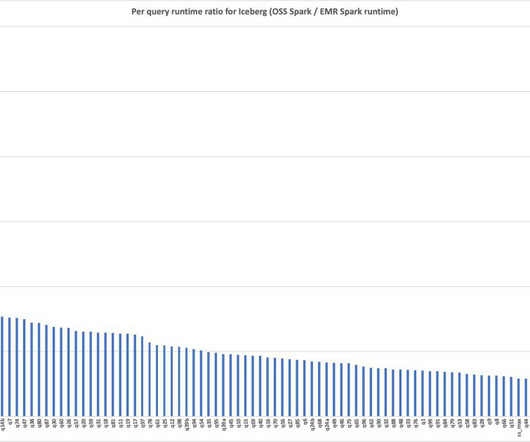
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. Enabling AWS Glue Data Catalog column statistics further improved performance by 3x versus last year.




















Let's personalize your content