This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We’ve already discussed how checkpoints, when triggered by the job manager, signal all source operators to snapshot their state, which is then broadcasted as a special record called a checkpoint barrier. Then it broadcasts the barrier downstream. However, it continues to process partitions that are behind the barrier.
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. Performance was tested on a Redshift serverless data warehouse with 128 RPU.
In the annual Porsche Carrera Cup Brasil, data is essential to keep drivers safe and sustain optimal performance of race cars. Together, they established a core architecture that the company could build on to develop its engineering capabilities and, eventually, support for entertainment and broadcasting, which remains on Morrone’s roadmap.
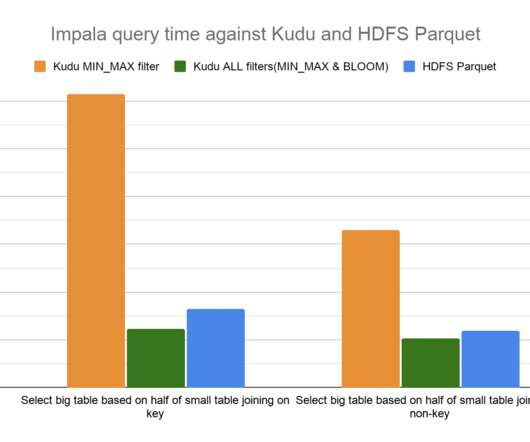
Pushing down column predicate filters to Kudu allows for optimized execution by skipping reading column values for filtered out rows and reducing network IO between a client, like the distributed query engine Apache Impala, and Kudu. Broadcast the generated hash table to all worker nodes. CDP Runtime 7.1.5 Bloom filter. Join Queries.
Internally, Apache Flink uses clever mechanisms to maintain exactly-once state consistency, while also optimizing for throughput and reduced latency. After the barriers from all upstream partitions have arrived, the sub-task takes the snapshot of its state and then broadcasts the barrier downstream.
To test Query profiler against the sample data, load the tpcds sample data and run queries. Suboptimal data distribution – If data distribution is suboptimal, you might notice a large broadcast or redistribution of data across compute nodes when two large tables are joined together.
When you use Trino on Amazon EMR or Athena, you get the latest open source community innovations along with proprietary, AWS developed optimizations. and Athena engine version 2, AWS has been developing query plan and engine behavior optimizations that improve query performance on Trino. Starting from Amazon EMR 6.8.0
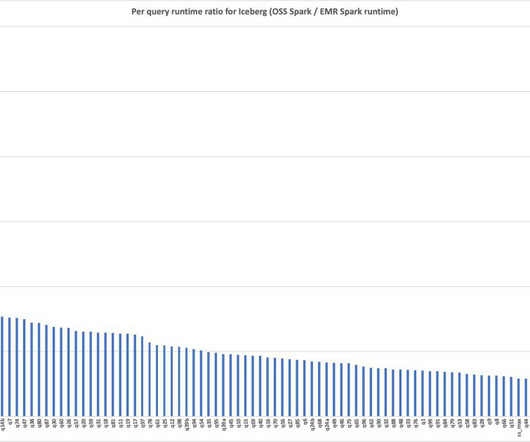
times faster with Amazon EMR runtime for Apache Spark , we detailed some of the optimizations, showing a runtime improvement of 4.5 However, many of the optimizations are geared towards DataSource V1, whereas Iceberg uses Spark DataSource V2. We have added eight new optimizations incrementally since the Amazon EMR 6.15
But things go awry and when they do, Proctor & Gamble now employs its Hot Melt Optimization platform to catch snags and get the process back on track. The resulting platform was pilot tested for nine months at one P&G plant before being rolled out half of P&G’s Pampers manufacturing plants across the US.
In 2019, another team tested the new fraudulent behavior Honeypot in Ethereum. Most importantly, AI can help optimize cybersecurity apps to help stop hackers. Before your crypto transaction is completed, it must be broadcast to its proprietary network for validation. The most important benefit is that they can help stop hackers.
It integrates data across a wide arrange of sources to help optimize the value of ad dollar spending. The platform is integrated across digital venues such as search and social media and older markets such as print, cable TV, radio, and broadcast. One common way to test market sentiment is to gather information directly from customers.
In addition, a lot of work has also been put into ensuring that Impala runs optimally in decoupled compute scenarios, where the data lives in object storage or remote HDFS. These are the common bottlenecks in analytic queries, and are notoriously difficult to optimize. . Broadcast Hash Join. Degree of Parallelism. Runtime (sec).
By default, the sink writes in batches to optimize throughput. SQL In Apache Flink SQL, users can provide hints to join queries that can be used to suggest the optimizer to have an effect in the query plan. The DataStream API now supports features like side outputs and broadcast state, and gaps on windowing API have been closed.
It integrates data across a wide arrange of sources to help optimize the value of ad dollar spending. The platform is integrated across digital venues such as search and social media and older markets such as print, cable TV, radio, and broadcast. So Oracle renamed it Oracle Advertising and Customer Experience.
Digital twins allow companies to run tests and predict performance based on simulations. Greater alignment across business units: Optimize management processes according to a variety of factors beyond just the condition of a piece of equipment. These factors can include available resources (e.g.,
He brings expertise in developing IT strategy, digital transformation, AI engineering, process optimization and operations. He brings in 20 years of experience across sectors including media, broadcasting, data centre, telecom, BFSI, and retail. December 2021. Airtel CISO Manish Tiwari joins Fractal as CIO.
It allows the company to run tests and predict performance based on simulations. Read this blog post to explore how digital twins can help you optimize your asset performance. RFID tags broadcast a variety of information about an asset in addition to its location, including the temperature and humidity of its environment.
The lesson is about the limitation of optimizing for a local maxima, usually in a silo. I believe this approach optimizes for a local maxima (the media buying bubble) and does not create the necessary incentives to solve for the global maxima (short or long-term business success). I believe this is necessary, but not sufficient.
As head of the JRFUs media business division, Yutaka Muroguchi has contracts with all three organizations, and is in charge of video management and broadcasting rights. At that time, the decision was made to produce the official match footage themselves rather than by the broadcasting station J Sports.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content