This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. Performance was tested on a Redshift serverless data warehouse with 128 RPU.
This feature is part of the Amazon Redshift console and provides a visual and graphical representation of the query’s run order, execution plan, and various statistics. To test Query profiler against the sample data, load the tpcds sample data and run queries. Try this feature in your environment and share your feedback with us.
We started by giving this data to the technical staff of the clubs, but we decided it was the moment to offer these advanced statistics to the fans and the media,” Bruno says. “We We had some tests in the laboratory first, and then we tested with the fans. We followed the design thinking process,” says Bruno. “We
Benchmark setup In our testing, we used the 3 TB dataset stored in Amazon S3 in compressed Parquet format and metadata for databases and tables is stored in the AWS Glue Data Catalog. Table and column statistics were not present for any of the tables. In this post, we compare Amazon EMR 6.15.0 times faster on Amazon EMR 6.15.0
Others aim simply to manage the collection and integration of data, leaving the analysis and presentation work to other tools that specialize in data science and statistics. The platform is integrated across digital venues such as search and social media and older markets such as print, cable TV, radio, and broadcast. Survey CTO.
A 1958 Harvard Business Review article coined the term information technology, focusing their definition on rapidly processing large amounts of information, using statistical and mathematical methods in decision-making, and simulating higher order thinking through applications.
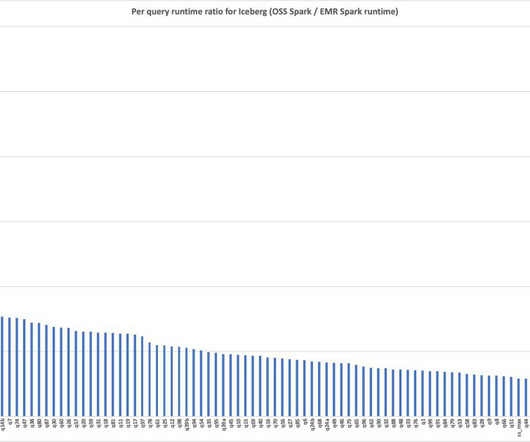
To assess the Spark engine’s performance with the Iceberg table format, we performed benchmark tests using the 3 TB TPC-DS dataset, version 2.13 (our results derived from the TPC-DS dataset are not directly comparable to the official TPC-DS results due to setup differences). No precalculated statistics were used for these tables.
These sources include ad marketplaces that dump statistics about audience engagement and click-through rates, sales software systems that report on customer purchases, and websites — and even storeroom floors — that track engagement. Survey CTO One common way to test market sentiment is to gather information directly from customers.
1) What Is A Misleading Statistic? 2) Are Statistics Reliable? 3) Misleading Statistics Examples In Real Life. 4) How Can Statistics Be Misleading. 5) How To Avoid & Identify The Misuse Of Statistics? If all this is true, what is the problem with statistics? What Is A Misleading Statistic?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content